StreamBench: Towards Benchmarking Continuous Improvement of Language Agents
2406.08747
2
0
Abstract
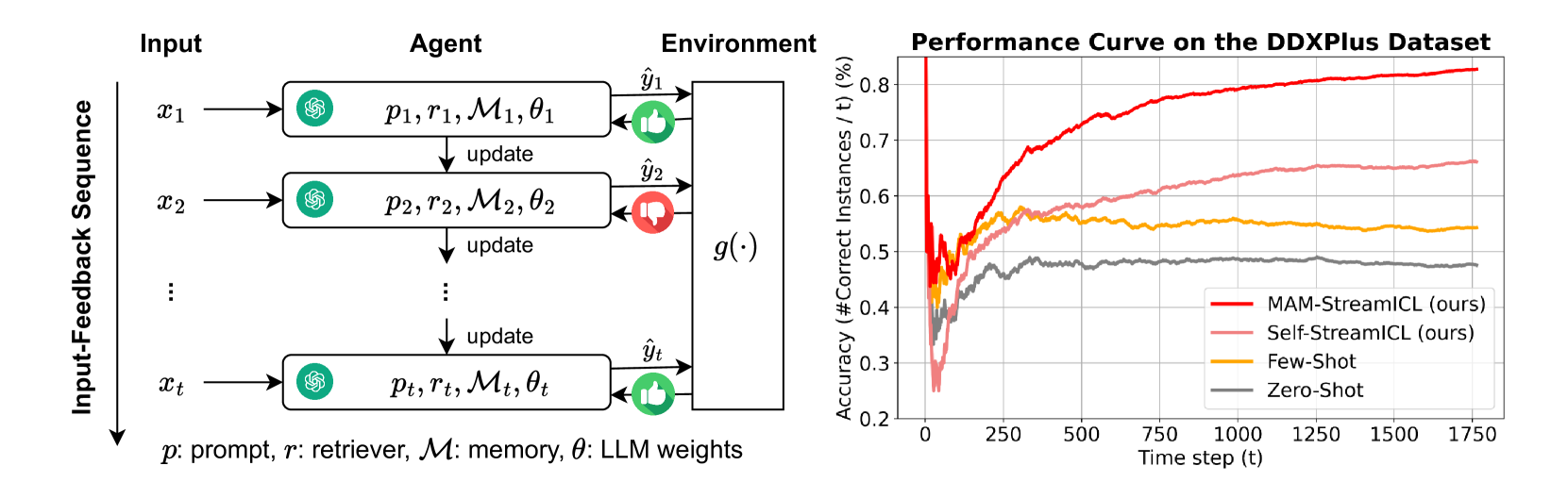
Recent works have shown that large language model (LLM) agents are able to improve themselves from experience, which is an important ability for continuous enhancement post-deployment. However, existing benchmarks primarily evaluate their innate capabilities and do not assess their ability to improve over time. To address this gap, we introduce StreamBench, a pioneering benchmark designed to evaluate the continuous improvement of LLM agents over an input-feedback sequence. StreamBench simulates an online learning environment where LLMs receive a continuous flow of feedback stream and iteratively enhance their performance. In addition, we propose several simple yet effective baselines for improving LLMs on StreamBench, and provide a comprehensive analysis to identify critical components that contribute to successful streaming strategies. Our work serves as a stepping stone towards developing effective online learning strategies for LLMs, paving the way for more adaptive AI systems in streaming scenarios.
Create account to get full access
Overview
- This paper introduces StreamBench, a benchmark for evaluating the continuous improvement of language agents over time.
- It addresses the challenge of assessing language models as they are iteratively updated and improved, rather than in a static evaluation.
- The authors propose a framework for simulating a stream of tasks and evaluating model performance as it evolves, with the goal of driving the development of language models that can continuously learn and improve.
Plain English Explanation
The paper discusses the challenge of evaluating language models like ChatGPT as they are constantly updated and improved over time. Typically, language models are evaluated on a fixed set of tasks, but this doesn't capture how they change and get better over time.
The researchers created a new benchmark called StreamBench that simulates a continuous stream of tasks. This allows them to assess how a language model's performance evolves as it is updated and improved. The goal is to drive the development of language models that can continuously learn and get better, rather than just performing well on a static set of tests.
By benchmarking in this dynamic way, the authors hope to spur progress towards language agents that can adapt and improve over time, rather than just being good at a fixed set of tasks. This connects to other recent work like Evaluating Large Language Models with Human Feedback and CS-Bench that are also exploring new ways to evaluate language models.
Technical Explanation
The core idea behind StreamBench is to simulate a continuous stream of tasks that a language model must adapt to over time. Rather than evaluating performance on a fixed set of tasks, the model is exposed to a sequence of tasks that evolve, requiring it to continuously learn and improve.
The paper outlines a framework for constructing this task stream, which includes:
- A pool of diverse tasks, ranging from language understanding to generation
- A process for dynamically generating new tasks and updating the pool over time
- Metrics for tracking model performance as it changes across the task stream
Importantly, the task stream is structured to encourage models to learn general capabilities that can transfer across a variety of domains, rather than just memorizing a fixed set of tasks.
The authors demonstrate the StreamBench framework through a series of experiments, showing how it can be used to evaluate different model update strategies and architectures. This includes looking at how models perform as the task distribution shifts over time, and how well they are able to leverage past learning to adapt to new challenges.
Critical Analysis
The StreamBench framework represents an important step forward in benchmarking language models, as it moves beyond static evaluation towards a more dynamic and realistic assessment of model capabilities.
However, the authors acknowledge that simulating a true continuous stream of tasks is a significant challenge, and the current instantiation may not fully capture the complexities of real-world model development. For example, the task update process is still relatively simplistic, and the authors note the need for more sophisticated approaches to task generation and distribution changes.
Additionally, while the framework is designed to encourage general learning, there are still open questions about how well these types of benchmarks correlate with downstream real-world performance. Further research is needed to understand the relationship between StreamBench results and a model's ability to adapt and improve in practical applications.
Overall, the StreamBench approach is a valuable contribution that pushes the field towards more rigorous and realistic evaluation of language models. As the authors suggest, continued work in this area could lead to important insights about the design of models and training processes that can truly learn and improve over time, rather than just optimizing for a fixed set of tasks. This aligns with the goals of other recent efforts like Evaluating LLMs at Evaluating Temporal Generalization and Automating Dataset Updates.
Conclusion
The StreamBench framework represents an important advance in benchmarking language models, shifting the focus from static evaluation to assessing continuous improvement over time. By simulating a dynamic stream of tasks, the authors aim to drive the development of language agents that can adapt and learn, rather than just excel at a fixed set of challenges.
While the current implementation has some limitations, the core ideas behind StreamBench point the way towards more realistic and impactful evaluation of language models. As the field continues to make rapid progress, tools like this will be essential for ensuring that models are developed with the ability to continuously learn and improve, rather than becoming obsolete as the world and user needs evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ViLCo-Bench: VIdeo Language COntinual learning Benchmark
Tianqi Tang, Shohreh Deldari, Hao Xue, Celso De Melo, Flora D. Salim
0
0
Video language continual learning involves continuously adapting to information from video and text inputs, enhancing a model's ability to handle new tasks while retaining prior knowledge. This field is a relatively under-explored area, and establishing appropriate datasets is crucial for facilitating communication and research in this field. In this study, we present the first dedicated benchmark, ViLCo-Bench, designed to evaluate continual learning models across a range of video-text tasks. The dataset comprises ten-minute-long videos and corresponding language queries collected from publicly available datasets. Additionally, we introduce a novel memory-efficient framework that incorporates self-supervised learning and mimics long-term and short-term memory effects. This framework addresses challenges including memory complexity from long video clips, natural language complexity from open queries, and text-video misalignment. We posit that ViLCo-Bench, with greater complexity compared to existing continual learning benchmarks, would serve as a critical tool for exploring the video-language domain, extending beyond conventional class-incremental tasks, and addressing complex and limited annotation issues. The curated data, evaluations, and our novel method are available at https://github.com/cruiseresearchgroup/ViLCo .
6/21/2024

clembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
Anne Beyer, Kranti Chalamalasetti, Sherzod Hakimov, Brielen Madureira, Philipp Sadler, David Schlangen
0
0
It has been established in recent work that Large Language Models (LLMs) can be prompted to self-play conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
6/3/2024
💬
Evaluating Large Language Models with Human Feedback: Establishing a Swedish Benchmark
Birger Moell
0
0
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have demonstrated significant capabilities across numerous applications. However, the performance of these models in languages with fewer resources, such as Swedish, remains under-explored. This study introduces a comprehensive human benchmark to assess the efficacy of prominent LLMs in understanding and generating Swedish language texts using forced choice ranking. We employ a modified version of the ChatbotArena benchmark, incorporating human feedback to evaluate eleven different models, including GPT-4, GPT-3.5, various Claude and Llama models, and bespoke models like Dolphin-2.9-llama3b-8b-flashback and BeagleCatMunin. These models were chosen based on their performance on LMSYS chatbot arena and the Scandeval benchmarks. We release the chatbotarena.se benchmark as a tool to improve our understanding of language model performance in Swedish with the hopes that it will be widely used. We aim to create a leaderboard once sufficient data has been collected and analysed.
5/24/2024
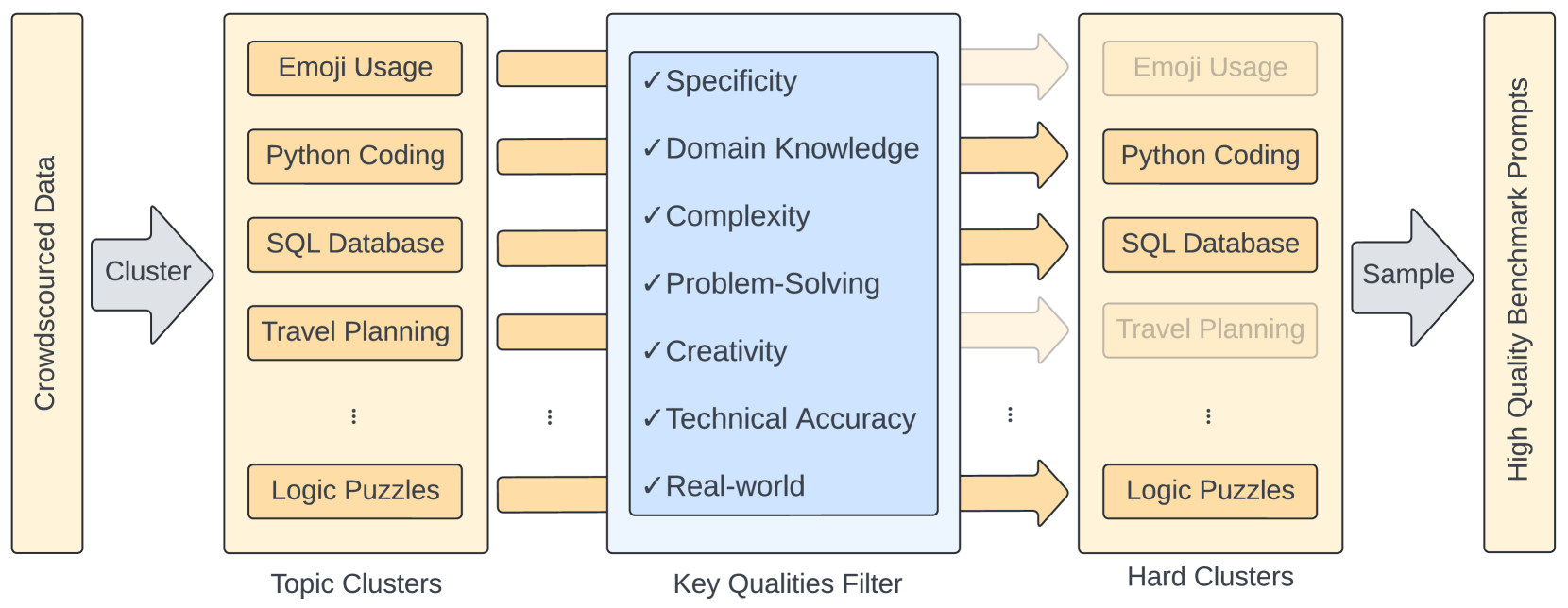
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica
0
0
The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
6/19/2024