Transfer Learning from Whisper for Microscopic Intelligibility Prediction

0
Sign in to get full access
Overview
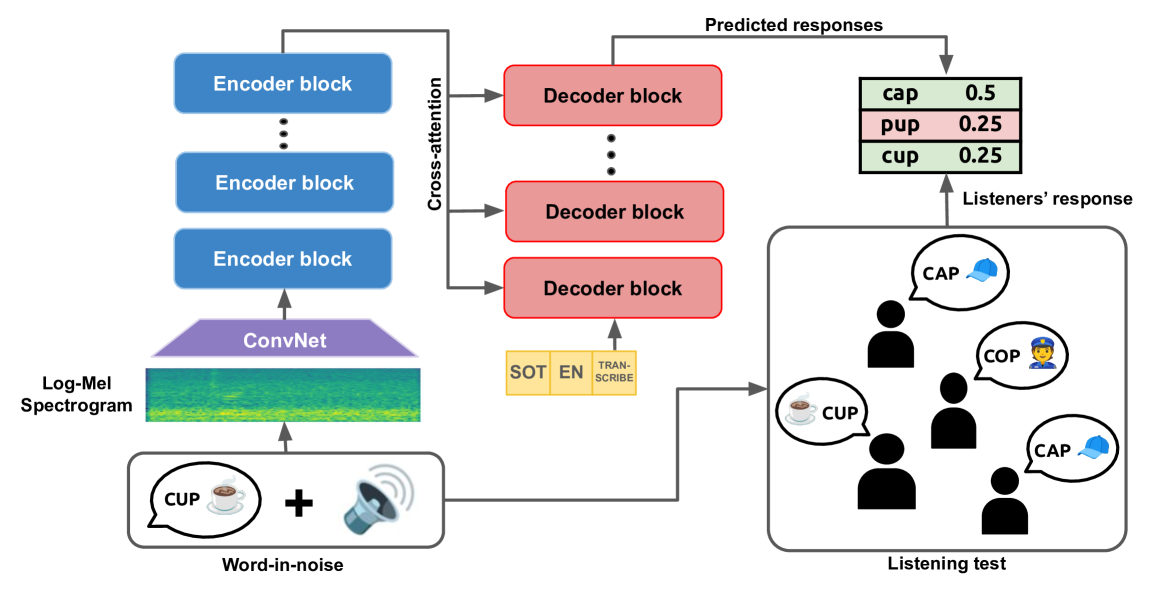
- This paper explores using a pre-trained speech recognition model, Whisper, to improve the prediction of microscopic intelligibility.
- The researchers aim to leverage the capabilities of Whisper, which has been trained on a large and diverse dataset of audio, to enhance the performance of a model tasked with predicting the intelligibility of speech heard through a microscope.
- This approach could have applications in fields like hearing aid development and medical diagnosis, where accurately assessing speech intelligibility is crucial.
Plain English Explanation
In this study, the researchers wanted to see if they could use a powerful speech recognition model called Whisper to help predict how intelligible speech would be when heard through a microscope. Microscopes are often used in medical and scientific settings, but the audio quality can sometimes make it hard to understand what's being said.
The researchers thought that by taking the Whisper model, which has been trained on a huge amount of audio data, they might be able to use its capabilities to better predict how intelligible the speech would be in a microscope. This could be really useful for things like developing better hearing aids or helping doctors and researchers understand what patients or research subjects are saying more accurately.
Technical Explanation
The researchers used a technique called transfer learning to adapt the Whisper model to the task of predicting microscopic speech intelligibility. Transfer learning allows you to take a model that has been trained on one task (in this case, general speech recognition) and fine-tune it to perform well on a different but related task (predicting microscopic intelligibility).
The researchers first pre-trained the Whisper model on a large dataset of audio recordings. They then took the pre-trained model and further trained it on a dataset of speech samples recorded through a microscope, along with human ratings of the intelligibility of those samples. By doing this, the model was able to learn the specific patterns and features that are important for predicting microscopic intelligibility.
The researchers compared the performance of their transfer learning approach to other machine learning models that were trained from scratch on the microscopic intelligibility dataset. They found that the transfer learning model significantly outperformed the other models, demonstrating the power of leveraging a pre-trained model like Whisper to tackle a specialized task.
Critical Analysis
One potential limitation of this study is the relatively small size of the microscopic intelligibility dataset used for fine-tuning the Whisper model. With more data, the model may be able to learn even more nuanced patterns and further improve its predictive performance.
Additionally, the researchers did not explore how the Whisper model's performance might vary across different types of microscopes or recording conditions. It would be interesting to see how well the transfer learning approach generalizes to a wider range of microscopic speech scenarios.
Overall, this research demonstrates the potential of using large language models like Whisper for specialized tasks and highlights the value of transfer learning as a powerful technique for leveraging pre-trained models. Further exploration of these approaches could lead to significant improvements in interpreting end-to-end deep learning models in various domains.
Conclusion
This paper presents a novel approach to improving the prediction of microscopic speech intelligibility by leveraging a pre-trained speech recognition model, Whisper, through transfer learning. The results show that this transfer learning technique can significantly outperform models trained from scratch on the microscopic intelligibility dataset, suggesting that it may have valuable applications in fields like hearing aid development and medical diagnosis where accurate speech intelligibility assessment is crucial. While the study has some limitations, it demonstrates the power of adapting large, general-purpose language models to specialized tasks and highlights the potential of these approaches to advance our understanding and application of deep learning in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transfer Learning from Whisper for Microscopic Intelligibility Prediction
Paul Best, Santiago Cuervo, Ricard Marxer
Macroscopic intelligibility models predict the expected human word-error-rate for a given speech-in-noise stimulus. In contrast, microscopic intelligibility models aim to make fine-grained predictions about listeners' perception, e.g. predicting phonetic or lexical responses. State-of-the-art macroscopic models use transfer learning from large scale deep learning models for speech processing, whereas such methods have rarely been used for microscopic modeling. In this paper, we study the use of transfer learning from Whisper, a state-of-the-art deep learning model for automatic speech recognition, for microscopic intelligibility prediction at the level of lexical responses. Our method outperforms the considered baselines, even in a zero-shot setup, and yields a relative improvement of up to 66% when fine-tuned to predict listeners' responses. Our results showcase the promise of large scale deep learning based methods for microscopic intelligibility prediction.
Read more4/3/2024

0
Self-Supervised Models in Automatic Whispered Speech Recognition
Aref Farhadipour, Homa Asadi, Volker Dellwo
In automatic speech recognition, any factor that alters the acoustic properties of speech can pose a challenge to the system's performance. This paper presents a novel approach for automatic whispered speech recognition in the Irish dialect using the self-supervised WavLM model. Conventional automatic speech recognition systems often fail to accurately recognise whispered speech due to its distinct acoustic properties and the scarcity of relevant training data. To address this challenge, we utilized a pre-trained WavLM model, fine-tuned with a combination of whispered and normal speech data from the wTIMIT and CHAINS datasets, which include the English language in Singaporean and Irish dialects, respectively. Our baseline evaluation with the OpenAI Whisper model highlighted its limitations, achieving a Word Error Rate (WER) of 18.8% on whispered speech. In contrast, the proposed WavLM-based system significantly improved performance, achieving a WER of 9.22%. These results demonstrate the efficacy of our approach in recognising whispered speech and underscore the importance of tailored acoustic modeling for robust automatic speech recognition systems. This study provides valuable insights into developing effective automatic speech recognition solutions for challenging speech affected by whisper and dialect. The source codes for this paper are freely available.
Read more8/1/2024

0
Cross-Lingual Transfer Learning for Speech Translation
Rao Ma, Yassir Fathullah, Mengjie Qian, Siyuan Tang, Mark Gales, Kate Knill
There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.
Read more7/2/2024
0
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Read more5/3/2024