Synthesizing Conversations from Unlabeled Documents using Automatic Response Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel approach to synthesizing conversations from unlabeled documents using automatic response segmentation.
- The authors develop a system that can extract conversational structure from unstructured text and generate coherent dialogues.
- The method leverages large language models and techniques like response prediction and implicit dialogue modeling to create realistic conversations without the need for labeled training data.
Plain English Explanation
In this paper, the researchers present a way to generate natural-sounding conversations from documents that don't have any labeled dialogue structure. Typically, creating conversational AI systems requires a lot of annotated training data, where conversations are broken down into individual responses and turns. However, this can be time-consuming and expensive to gather.
The key idea behind this work is to automatically identify conversational structure within unstructured text, such as articles or books, and then use that to train a system to generate new dialogues. The system relies on large language models, which are powerful AI systems trained on vast amounts of text data. By learning patterns in how people respond to each other, the model can then predict plausible back-and-forth exchanges, even without an explicit dialogue dataset.
This approach has several benefits. It allows for the creation of conversational systems without the need for painstakingly labeled training data. And the generated dialogues can be more diverse and natural-sounding than those produced by more traditional methods. This could be useful for applications like interactive storytelling, open-domain chatbots, or even language learning tools.
Technical Explanation
The core of the researchers' approach is a response segmentation model that can identify individual conversational turns within a piece of unstructured text. This model is trained on a large corpus of unlabeled documents, using techniques like response prediction and implicit dialogue modeling to learn patterns of how people respond to each other.
Once the model has been trained to segment the text into conversational exchanges, the researchers then use a dialogue generation module to create new, coherent dialogues. This module leverages the response segmentation model, along with language modeling techniques, to predict plausible next responses and stitch them together into multi-turn conversations.
The researchers evaluate their system on a variety of datasets, including open-domain discussions and task-oriented dialogues. They find that the generated conversations are rated as more natural and engaging than those produced by baseline methods that do not use their automatic response segmentation approach.
Critical Analysis
One of the key strengths of this work is its ability to generate conversational data without relying on labeled training examples. This is an important advancement, as the collection and annotation of dialogue datasets can be extremely resource-intensive. By tapping into the wealth of unlabeled text data available, the researchers have found a way to sidestep this bottleneck.
However, the paper does note some limitations of the approach. For example, the generated dialogues may still contain some coherence issues or factual inconsistencies, as the model does not have a strong understanding of the semantics or context of the conversation. Additionally, the system may struggle to capture the nuances of natural human interaction, such as tone, emotion, and social dynamics.
Further research could explore ways to address these limitations, such as by incorporating more contextual information or modeling higher-level discourse patterns. Integrating this response segmentation approach with other dialogue generation techniques could also lead to even more realistic and engaging conversational AI systems.
Conclusion
Overall, this paper presents a novel and promising approach to synthesizing natural conversations from unlabeled text data. By automatically identifying conversational structure and using it to train language models, the researchers have demonstrated a way to generate diverse and coherent dialogues without the need for extensive manual labeling.
While the technique still has room for improvement, it represents an important step forward in the field of conversational data generation. As language models and other AI technologies continue to advance, approaches like this could enable the creation of more engaging and natural-sounding conversational interfaces across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Synthesizing Conversations from Unlabeled Documents using Automatic Response Segmentation
Fanyou Wu, Weijie Xu, Chandan K. Reddy, Srinivasan H. Sengamedu
In this study, we tackle the challenge of inadequate and costly training data that has hindered the development of conversational question answering (ConvQA) systems. Enterprises have a large corpus of diverse internal documents. Instead of relying on a searching engine, a more compelling approach for people to comprehend these documents is to create a dialogue system. In this paper, we propose a robust dialog synthesising method. We learn the segmentation of data for the dialog task instead of using segmenting at sentence boundaries. The synthetic dataset generated by our proposed method achieves superior quality when compared to WikiDialog, as assessed through machine and human evaluations. By employing our inpainted data for ConvQA retrieval system pre-training, we observed a notable improvement in performance across OR-QuAC benchmarks.
Read more6/7/2024
📊
0
A Survey on Recent Advances in Conversational Data Generation
Heydar Soudani, Roxana Petcu, Evangelos Kanoulas, Faegheh Hasibi
Recent advancements in conversational systems have significantly enhanced human-machine interactions across various domains. However, training these systems is challenging due to the scarcity of specialized dialogue data. Traditionally, conversational datasets were created through crowdsourcing, but this method has proven costly, limited in scale, and labor-intensive. As a solution, the development of synthetic dialogue data has emerged, utilizing techniques to augment existing datasets or convert textual resources into conversational formats, providing a more efficient and scalable approach to dataset creation. In this survey, we offer a systematic and comprehensive review of multi-turn conversational data generation, focusing on three types of dialogue systems: open domain, task-oriented, and information-seeking. We categorize the existing research based on key components like seed data creation, utterance generation, and quality filtering methods, and introduce a general framework that outlines the main principles of conversation data generation systems. Additionally, we examine the evaluation metrics and methods for assessing synthetic conversational data, address current challenges in the field, and explore potential directions for future research. Our goal is to accelerate progress for researchers and practitioners by presenting an overview of state-of-the-art methods and highlighting opportunities to further research in this area.
Read more5/24/2024
0
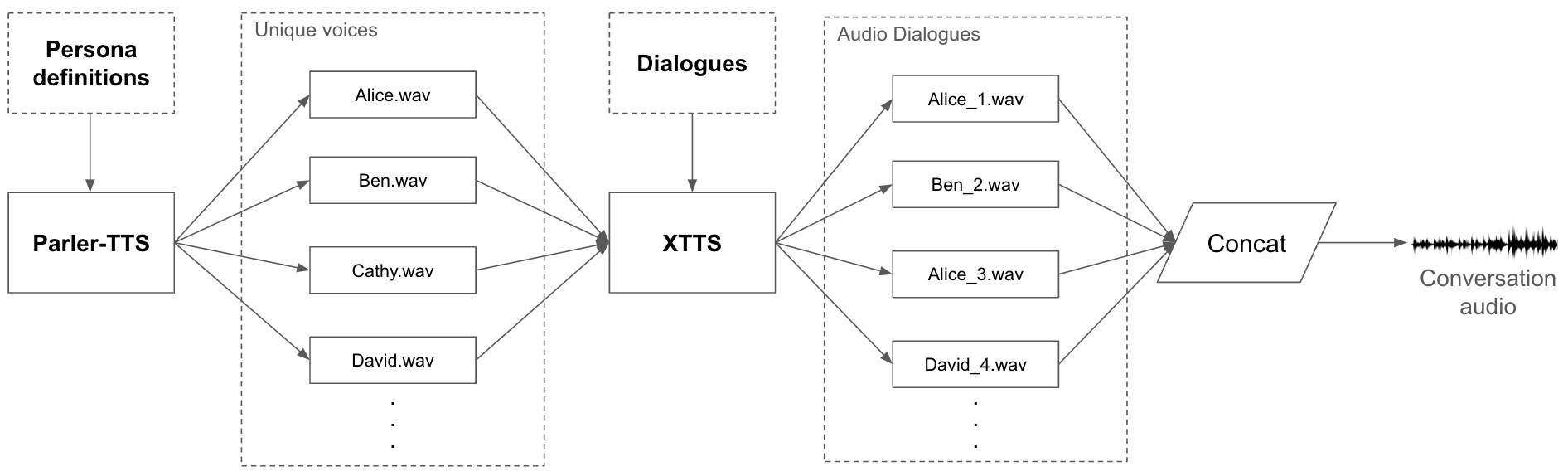
A Framework for Synthetic Audio Conversations Generation using Large Language Models
Kaung Myat Kyaw, Jonathan Hoyin Chan
In this paper, we introduce ConversaSynth, a framework designed to generate synthetic conversation audio using large language models (LLMs) with multiple persona settings. The framework first creates diverse and coherent text-based dialogues across various topics, which are then converted into audio using text-to-speech (TTS) systems. Our experiments demonstrate that ConversaSynth effectively generates highquality synthetic audio datasets, which can significantly enhance the training and evaluation of models for audio tagging, audio classification, and multi-speaker speech recognition. The results indicate that the synthetic datasets generated by ConversaSynth exhibit substantial diversity and realism, making them suitable for developing robust, adaptable audio-based AI systems.
Read more9/4/2024
0
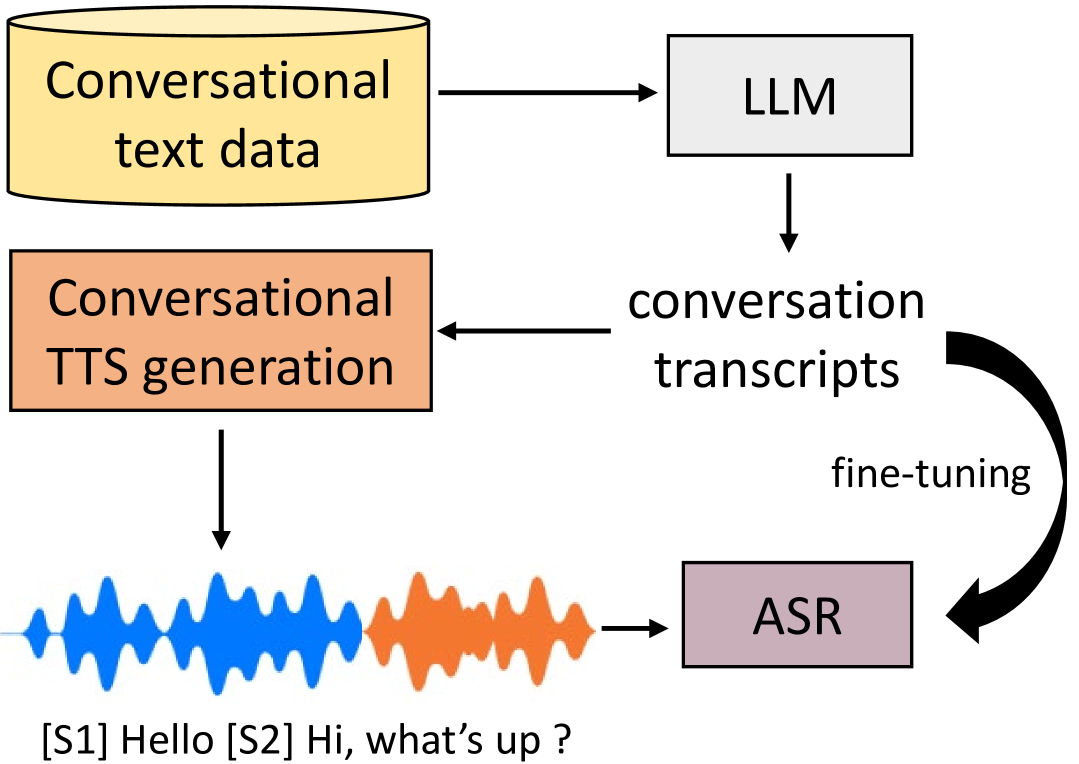
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024