Taming False Positives in Out-of-Distribution Detection with Human Feedback

0
Sign in to get full access
Overview
- This paper focuses on reducing false positives in out-of-distribution (OOD) detection, which is the ability to identify data that is significantly different from the training data.
- The authors propose a human-in-the-loop approach, where a human expert provides feedback to the model to improve its OOD detection capabilities.
- The key ideas include using human feedback to identify misclassified OOD samples, and then retraining the model to better distinguish OOD data from in-distribution data.
Plain English Explanation
Out-of-distribution (OOD) detection is an important task in machine learning, where the goal is to identify data that is very different from the examples the model was trained on. This is crucial for ensuring that AI systems behave safely and reliably in the real world, where they may encounter all kinds of unexpected inputs.
The problem is that current OOD detection methods can sometimes make mistakes, flagging in-distribution data as out-of-distribution (false positives). This can be frustrating and disrupt the user experience. To address this, the researchers in this paper propose involving a human expert in the loop.
The idea is that the human can provide feedback to the model when it makes a mistake, identifying samples that were incorrectly classified as OOD. The model can then use this feedback to learn from its errors and improve its ability to distinguish in-distribution and OOD data in the future. By incorporating human knowledge, the model can become better calibrated and reduce false positives.
The authors demonstrate that this human-in-the-loop approach leads to significant improvements in OOD detection performance, compared to models trained without the benefit of human feedback. This suggests that combining machine learning with human expertise can be a powerful way to build more robust and reliable AI systems.
Technical Explanation
The key components of the proposed human-in-the-loop OOD detection approach are:
-
OOD Detection Model: The authors use a gradient-regularized OOD detection model as the base architecture, which has been shown to perform well on OOD tasks.
-
Human Feedback: A human expert is asked to review samples that the model has flagged as OOD. The human provides binary feedback indicating whether the sample is truly OOD or not.
-
Feedback Integration: The model uses the human feedback to identify misclassified OOD samples. It then retrains itself to better distinguish in-distribution and OOD data, focusing on the problematic samples.
The authors evaluate their approach on several benchmark OOD detection datasets, including a more realistic benchmark that includes a more diverse set of OOD data. They show that the human-in-the-loop model significantly outperforms the baseline OOD detection model, reducing false positive rates by a large margin.
Critical Analysis
The authors acknowledge several limitations of their approach:
-
Human Effort: Relying on human feedback requires significant manual effort, which may limit the scalability of the approach. The authors suggest exploring ways to reduce the human burden, such as active learning techniques.
-
Biased Feedback: The human feedback may be biased or inconsistent, which could negatively impact the model's learning. The authors note the need for further research on mitigating the effects of biased human inputs.
-
Generalization: It's unclear how well the model would generalize to OOD data that is very different from the samples seen during the human feedback process. Further research is needed to understand the model's limits and failure modes.
Additionally, the authors do not address the fundamental challenges of OOD detection, such as the inherent difficulty of defining and detecting OOD data. The proposed approach may help mitigate some of these issues, but does not solve them entirely.
Conclusion
This paper presents a novel human-in-the-loop approach to improving out-of-distribution detection, a crucial capability for ensuring the reliability and safety of AI systems. By incorporating human feedback, the model is able to learn from its mistakes and significantly reduce false positive rates, an important step towards building more robust and trustworthy AI.
While the approach has some limitations, such as the reliance on human effort and potential biases, the results demonstrate the value of combining machine learning with human expertise. As AI systems become more pervasive in our lives, techniques like this that can enhance their robustness and reliability will be increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Taming False Positives in Out-of-Distribution Detection with Human Feedback
Harit Vishwakarma, Heguang Lin, Ramya Korlakai Vinayak
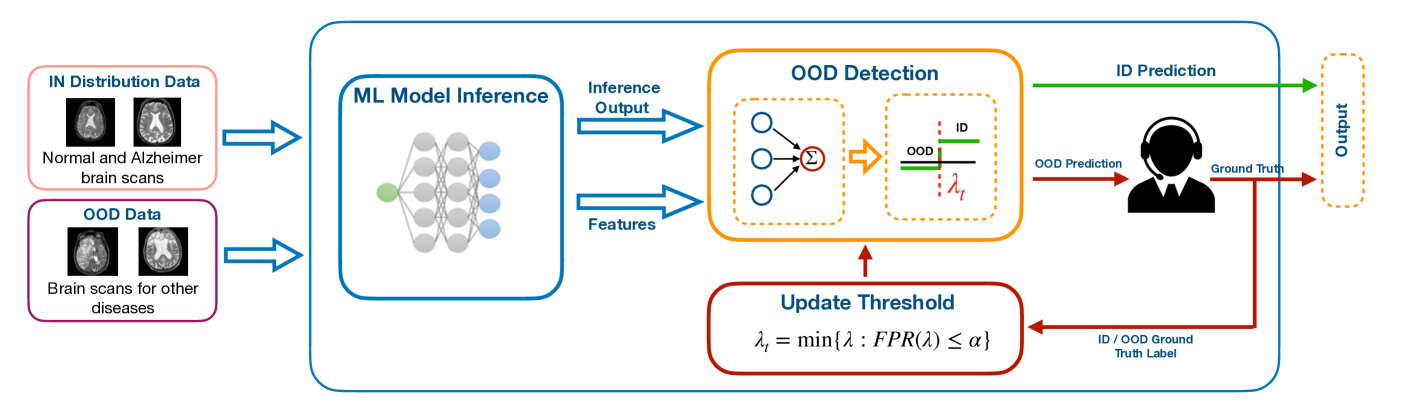
Robustness to out-of-distribution (OOD) samples is crucial for safely deploying machine learning models in the open world. Recent works have focused on designing scoring functions to quantify OOD uncertainty. Setting appropriate thresholds for these scoring functions for OOD detection is challenging as OOD samples are often unavailable up front. Typically, thresholds are set to achieve a desired true positive rate (TPR), e.g., $95%$ TPR. However, this can lead to very high false positive rates (FPR), ranging from 60 to 96%, as observed in the Open-OOD benchmark. In safety-critical real-life applications, e.g., medical diagnosis, controlling the FPR is essential when dealing with various OOD samples dynamically. To address these challenges, we propose a mathematically grounded OOD detection framework that leverages expert feedback to emph{safely} update the threshold on the fly. We provide theoretical results showing that it is guaranteed to meet the FPR constraint at all times while minimizing the use of human feedback. Another key feature of our framework is that it can work with any scoring function for OOD uncertainty quantification. Empirical evaluation of our system on synthetic and benchmark OOD datasets shows that our method can maintain FPR at most $5%$ while maximizing TPR.
Read more4/29/2024

0
Out-of-Distribution Learning with Human Feedback
Haoyue Bai, Xuefeng Du, Katie Rainey, Shibin Parameswaran, Yixuan Li
Out-of-distribution (OOD) learning often relies heavily on statistical approaches or predefined assumptions about OOD data distributions, hindering their efficacy in addressing multifaceted challenges of OOD generalization and OOD detection in real-world deployment environments. This paper presents a novel framework for OOD learning with human feedback, which can provide invaluable insights into the nature of OOD shifts and guide effective model adaptation. Our framework capitalizes on the freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. To harness such data, our key idea is to selectively provide human feedback and label a small number of informative samples from the wild data distribution, which are then used to train a multi-class classifier and an OOD detector. By exploiting human feedback, we enhance the robustness and reliability of machine learning models, equipping them with the capability to handle OOD scenarios with greater precision. We provide theoretical insights on the generalization error bounds to justify our algorithm. Extensive experiments show the superiority of our method, outperforming the current state-of-the-art by a significant margin.
Read more8/16/2024

0
Gradient-Regularized Out-of-Distribution Detection
Sina Sharifi, Taha Entesari, Bardia Safaei, Vishal M. Patel, Mahyar Fazlyab
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. Our code is available at https://github.com/o4lc/Greg-OOD.
Read more7/24/2024

0
Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
Read more6/5/2024