Technical Report of NICE Challenge at CVPR 2024: Caption Re-ranking Evaluation Using Ensembled CLIP and Consensus Scores

0
Sign in to get full access
Overview
- This technical report explores a novel approach for caption re-ranking in the NICE Challenge at CVPR 2024.
- The method utilizes an ensemble of CLIP (Contrastive Language-Image Pre-training) models and consensus scoring to enhance image caption ranking.
- The report presents experimental results and insights that could improve performance in image captioning challenges.
Plain English Explanation
The researchers in this paper have developed a new way to rank and score image captions for a competition called the NICE Challenge at a major computer vision conference, CVPR 2024. Their approach combines multiple CLIP models, which are AI systems that can understand the relationship between images and text, and then uses a consensus scoring method to come up with the best captions for each image.
The key idea is that by using an ensemble of CLIP models rather than just one, and then looking for captions that score highly across all the models, they can identify the most accurate and appropriate captions for each image. This helps improve the performance of image captioning systems, which is an important task in computer vision and artificial intelligence.
The researchers tested their method on the NICE Challenge dataset and found that it outperformed other approaches. They explain the technical details of how their system works and provide insights that could help other researchers develop even better image captioning models in the future.
Technical Explanation
The proposed method in this technical report leverages an ensemble of CLIP models and a consensus scoring approach for caption re-ranking in the NICE Challenge at CVPR 2024.
The key steps of the method are:
-
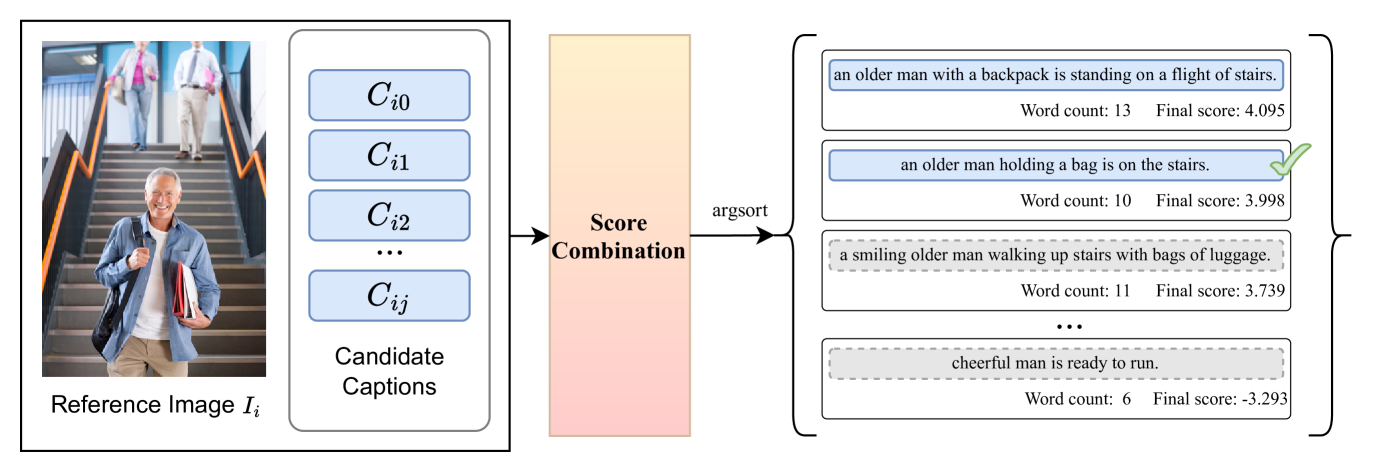
CLIP Ensemble: The researchers use multiple pre-trained CLIP models, each with its own unique characteristics and biases. This CLIP ensemble is used to generate image-text similarity scores for the candidate captions.
-
Consensus Scoring: To identify the most accurate captions, the method computes a consensus score by aggregating the scores from the individual CLIP models. Captions that score highly across the ensemble are ranked higher, as they are more likely to be consistent and reliable.
-
Caption Re-ranking: The final caption rankings are produced by re-ordering the candidate captions based on their consensus scores. This allows the most relevant and appropriate captions to be selected for each image.
The researchers conducted experiments on the NICE Challenge dataset and found that their ensemble CLIP and consensus scoring approach outperformed other caption re-ranking methods. They attribute the performance gains to the ability of the ensemble to capture diverse perspectives and the consensus scoring mechanism to identify the most reliable captions.
Critical Analysis
The proposed method offers a promising approach for improving image caption ranking in challenges like the NICE Challenge. The use of a CLIP ensemble and consensus scoring is a well-designed strategy to leverage the strengths of multiple pre-trained models and identify the most consistent and accurate captions.
However, the paper does not provide a detailed analysis of the individual CLIP models used in the ensemble, their architectural differences, or the rationale for their selection. Additionally, the impact of the number of CLIP models in the ensemble and the specific consensus scoring mechanism on the overall performance is not extensively explored.
Furthermore, the paper could have discussed the potential limitations or biases inherent in the CLIP models, and how they might affect the caption re-ranking process. For example, concerns have been raised about the biases present in CLIP models, which could influence the ranking of captions.
To further strengthen the research, future work could investigate the robustness of the method to different types of image-text datasets, as well as explore strategies for dynamically adapting the CLIP ensemble and consensus scoring based on the characteristics of the target task or dataset.
Conclusion
This technical report presents a novel approach for caption re-ranking in the NICE Challenge at CVPR 2024, leveraging an ensemble of CLIP models and consensus scoring. The experimental results demonstrate the effectiveness of this method in improving image captioning performance.
The key contributions of this work include the innovative use of a CLIP ensemble and consensus scoring, as well as the insights gained from the analysis of the captioning task. These findings could inform the development of more robust and accurate image captioning systems, with potential applications in various domains, such as visual understanding, content generation, and assistive technologies.
Overall, this research represents a valuable step forward in enhancing image captioning capabilities and advancing the state-of-the-art in computer vision and language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Technical Report of NICE Challenge at CVPR 2024: Caption Re-ranking Evaluation Using Ensembled CLIP and Consensus Scores
Kiyoon Jeong, Woojun Lee, Woongchan Nam, Minjeong Ma, Pilsung Kang
This report presents the ECO (Ensembled Clip score and cOnsensus score) pipeline from team DSBA LAB, which is a new framework used to evaluate and rank captions for a given image. ECO selects the most accurate caption describing image. It is made possible by combining an Ensembled CLIP score, which considers the semantic alignment between the image and captions, with a Consensus score that accounts for the essentialness of the captions. Using this framework, we achieved notable success in the CVPR 2024 Workshop Challenge on Caption Re-ranking Evaluation at the New Frontiers for Zero-Shot Image Captioning Evaluation (NICE). Specifically, we secured third place based on the CIDEr metric, second in both the SPICE and METEOR metrics, and first in the ROUGE-L and all BLEU Score metrics. The code and configuration for the ECO framework are available at https://github.com/DSBA-Lab/ECO .
Read more6/14/2024

0
The Solution for the CVPR2024 NICE Image Captioning Challenge
Longfei Huang, Shupeng Zhong, Xiangyu Wu, Ruoxuan Li
This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach achieves a CIDEr score of 234.11.
Read more4/30/2024

0
Updating CLIP to Prefer Descriptions Over Captions
Amir Zur, Elisa Kreiss, Karel D'Oosterlinck, Christopher Potts, Atticus Geiger
Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
Read more6/17/2024

0
Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization
Nicholas Moratelli, Davide Caffagni, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
The conventional training approach for image captioning involves pre-training a network using teacher forcing and subsequent fine-tuning with Self-Critical Sequence Training to maximize hand-crafted captioning metrics. However, when attempting to optimize modern and higher-quality metrics like CLIP-Score and PAC-Score, this training method often encounters instability and fails to acquire the genuine descriptive capabilities needed to produce fluent and informative captions. In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization (DiCO). Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. DiCO not only exhibits improved stability and enhanced quality in the generated captions but also aligns more closely with human preferences compared to existing methods, especially in modern metrics. Additionally, it maintains competitive performance in traditional metrics. Our source code and trained models are publicly available at https://github.com/aimagelab/DiCO.
Read more8/28/2024