TOPFORMER: Topology-Aware Authorship Attribution of Deepfake Texts with Diverse Writing Styles

0
🔮
Sign in to get full access
Overview
- Recent advances in Large Language Models (LLMs) have enabled the generation of open-ended high-quality texts that are difficult to distinguish from human-written texts, known as "deepfake texts".
- There are currently over 72,000 text generation models available, making it easy for those with malicious intent to generate harmful texts and disinformation at scale.
- To address this problem, a computational method to determine if a given text is a deepfake or not is needed, a task known as "Authorship Attribution (AA)".
- The authors propose a model called TopFormer that improves on existing AA solutions by capturing more linguistic patterns in deepfake texts using a Topological Data Analysis (TDA) layer in a Transformer-based architecture.
Plain English Explanation
Large language models have become incredibly advanced, allowing them to generate human-like text that is hard to distinguish from text written by a person. This is a problem because bad actors can use these models to quickly create massive amounts of fake or misleading information.
To tackle this issue, researchers are working on ways to automatically detect when text was generated by a machine rather than a human. This process is called "authorship attribution," and it involves not only identifying if a text is fake, but also pinpointing which specific language model was used to generate it.
The researchers in this study developed a new model called TopFormer that builds on previous approaches. TopFormer uses a special technique called Topological Data Analysis (TDA) to capture the unique linguistic structures and patterns found in machine-generated texts. By combining this TDA analysis with the contextual understanding of a Transformer-based language model, TopFormer was able to outperform other authorship attribution methods, correctly identifying the source of the text with up to a 7% higher accuracy.
Technical Explanation
The authors propose a Transformer-based model called TopFormer that improves on existing Authorship Attribution (AA) solutions by incorporating a Topological Data Analysis (TDA) layer. This allows TopFormer to capture more detailed linguistic patterns and structures in machine-generated "deepfake texts".
The key elements of the TopFormer architecture are:
- A Transformer-based backbone that learns contextual representations, capturing semantic and syntactic linguistic features.
- A TDA layer that extracts shape and structural features from the pooled output of the Transformer, complementing the contextual understanding.
- The combination of the Transformer's contextual representations and the TDA-derived structural features as input to the final classification layers.
The authors evaluate TopFormer on three different datasets, and show that it outperforms all baseline models, achieving up to a 7% increase in Macro F1 score for the authorship attribution task. This demonstrates the benefits of incorporating TDA analysis when dealing with imbalanced and multi-style datasets, as it allows the model to better capture the unique linguistic characteristics of machine-generated text.
Critical Analysis
The paper provides a compelling approach to the important problem of detecting and attributing authorship of machine-generated text. However, a few potential limitations and areas for further research are worth noting:
- The evaluation was limited to three specific datasets, and it's unclear how well TopFormer would generalize to other datasets or real-world scenarios with more diverse text styles and genres.
- The paper does not delve into the limitations of large language models (LLMs) that could lead to false attribution, such as model biases or the potential for LLMs to inadvertently "mimic" the writing styles of their training data.
- While the TDA layer appears to provide valuable structural features, the specific interpretability and explainability of these features are not explored in depth, which could limit the practical applicability of the approach.
Further research could explore the robustness of TopFormer on a wider range of datasets, investigate potential LLM limitations that could impact authorship attribution, and provide more insight into the linguistic patterns captured by the TDA layer.
Conclusion
The authors have developed a novel Transformer-based model called TopFormer that leverages Topological Data Analysis to improve the task of authorship attribution for machine-generated texts, or "deepfakes." By capturing both contextual representations and structural features, TopFormer outperforms existing solutions, demonstrating the benefits of incorporating TDA analysis when dealing with the complex linguistic patterns found in LLM-generated content.
As the proliferation of high-quality text generation models continues, the ability to reliably detect and attribute authorship of such texts will become increasingly crucial for mitigating the spread of harmful disinformation. The TopFormer approach represents an important step forward in this direction, with the potential for further refinement and real-world application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
TOPFORMER: Topology-Aware Authorship Attribution of Deepfake Texts with Diverse Writing Styles
Adaku Uchendu, Thai Le, Dongwon Lee
Recent advances in Large Language Models (LLMs) have enabled the generation of open-ended high-quality texts, that are non-trivial to distinguish from human-written texts. We refer to such LLM-generated texts as deepfake texts. There are currently over 72K text generation models in the huggingface model repo. As such, users with malicious intent can easily use these open-sourced LLMs to generate harmful texts and dis/misinformation at scale. To mitigate this problem, a computational method to determine if a given text is a deepfake text or not is desired--i.e., Turing Test (TT). In particular, in this work, we investigate the more general version of the problem, known as Authorship Attribution (AA), in a multi-class setting--i.e., not only determining if a given text is a deepfake text or not but also being able to pinpoint which LLM is the author. We propose TopFormer to improve existing AA solutions by capturing more linguistic patterns in deepfake texts by including a Topological Data Analysis (TDA) layer in the Transformer-based model. We show the benefits of having a TDA layer when dealing with imbalanced, and multi-style datasets, by extracting TDA features from the reshaped $pooled_output$ of our backbone as input. This Transformer-based model captures contextual representations (i.e., semantic and syntactic linguistic features), while TDA captures the shape and structure of data (i.e., linguistic structures). Finally, TopFormer, outperforms all baselines in all 3 datasets, achieving up to 7% increase in Macro F1 score.
Read more4/10/2024
🔎
0
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
Read more5/22/2024
0
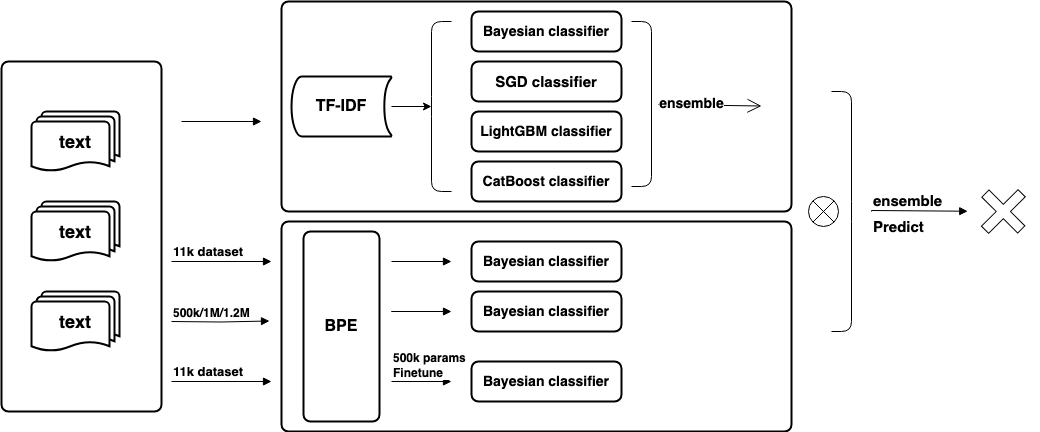
Enhancing Text Authenticity: A Novel Hybrid Approach for AI-Generated Text Detection
Ye Zhang, Qian Leng, Mengran Zhu, Rui Ding, Yue Wu, Jintong Song, Yulu Gong
The rapid advancement of Large Language Models (LLMs) has ushered in an era where AI-generated text is increasingly indistinguishable from human-generated content. Detecting AI-generated text has become imperative to combat misinformation, ensure content authenticity, and safeguard against malicious uses of AI. In this paper, we propose a novel hybrid approach that combines traditional TF-IDF techniques with advanced machine learning models, including Bayesian classifiers, Stochastic Gradient Descent (SGD), Categorical Gradient Boosting (CatBoost), and 12 instances of Deberta-v3-large models. Our approach aims to address the challenges associated with detecting AI-generated text by leveraging the strengths of both traditional feature extraction methods and state-of-the-art deep learning models. Through extensive experiments on a comprehensive dataset, we demonstrate the effectiveness of our proposed method in accurately distinguishing between human and AI-generated text. Our approach achieves superior performance compared to existing methods. This research contributes to the advancement of AI-generated text detection techniques and lays the foundation for developing robust solutions to mitigate the challenges posed by AI-generated content.
Read more6/12/2024
🧠
0
Benchmarking Advanced Text Anonymisation Methods: A Comparative Study on Novel and Traditional Approaches
Dimitris Asimopoulos, Ilias Siniosoglou, Vasileios Argyriou, Thomai Karamitsou, Eleftherios Fountoukidis, Sotirios K. Goudos, Ioannis D. Moscholios, Konstantinos E. Psannis, Panagiotis Sarigiannidis
In the realm of data privacy, the ability to effectively anonymise text is paramount. With the proliferation of deep learning and, in particular, transformer architectures, there is a burgeoning interest in leveraging these advanced models for text anonymisation tasks. This paper presents a comprehensive benchmarking study comparing the performance of transformer-based models and Large Language Models(LLM) against traditional architectures for text anonymisation. Utilising the CoNLL-2003 dataset, known for its robustness and diversity, we evaluate several models. Our results showcase the strengths and weaknesses of each approach, offering a clear perspective on the efficacy of modern versus traditional methods. Notably, while modern models exhibit advanced capabilities in capturing con textual nuances, certain traditional architectures still keep high performance. This work aims to guide researchers in selecting the most suitable model for their anonymisation needs, while also shedding light on potential paths for future advancements in the field.
Read more4/24/2024