Global Optimality without Mixing Time Oracles in Average-reward RL via Multi-level Actor-Critic
2403.11925
0
0
Abstract
In the context of average-reward reinforcement learning, the requirement for oracle knowledge of the mixing time, a measure of the duration a Markov chain under a fixed policy needs to achieve its stationary distribution, poses a significant challenge for the global convergence of policy gradient methods. This requirement is particularly problematic due to the difficulty and expense of estimating mixing time in environments with large state spaces, leading to the necessity of impractically long trajectories for effective gradient estimation in practical applications. To address this limitation, we consider the Multi-level Actor-Critic (MAC) framework, which incorporates a Multi-level Monte-Carlo (MLMC) gradient estimator. With our approach, we effectively alleviate the dependency on mixing time knowledge, a first for average-reward MDPs global convergence. Furthermore, our approach exhibits the tightest available dependence of $mathcal{O}left( sqrt{tau_{mix}} right)$known from prior work. With a 2D grid world goal-reaching navigation experiment, we demonstrate that MAC outperforms the existing state-of-the-art policy gradient-based method for average reward settings.
Create account to get full access
Overview
- This paper proposes a new algorithm called "Multi-level Actor-Critic" for reinforcement learning (RL) in average-reward settings.
- The key innovation is that it can achieve global optimality without requiring a "mixing time oracle," which is a common assumption in prior RL algorithms.
- The algorithm is designed to be sample-efficient and scalable, making it potentially useful for real-world RL problems.
Plain English Explanation
The paper introduces a new reinforcement learning algorithm called "Multi-level Actor-Critic" that can find the best possible policy for an average-reward RL problem. This is significant because many previous RL algorithms required a special "mixing time oracle" to achieve global optimality, which can be difficult to obtain in practice.
The new algorithm works by maintaining multiple "actor" and "critic" components that interact in a hierarchical fashion. The actors explore the environment and propose actions, while the critics evaluate the quality of those actions and provide feedback to improve the actors. This multi-level structure allows the algorithm to converge to the globally optimal policy without needing the mixing time oracle.
Importantly, the authors also show that their algorithm is sample-efficient, meaning it can learn the optimal policy using a relatively small number of interactions with the environment. This is crucial for real-world RL applications, where data collection can be expensive or time-consuming.
By overcoming the need for a mixing time oracle and demonstrating sample efficiency, this new algorithm represents an important advance in the field of reinforcement learning. It could potentially enable RL to be applied to a wider range of problems, especially those involving long-term average rewards rather than episodic, finite-horizon settings.
Technical Explanation
The paper proposes a new algorithm called "Multi-level Actor-Critic" (MAC) for average-reward reinforcement learning. Unlike many previous RL algorithms, MAC does not require a "mixing time oracle" to achieve global optimality.
The key innovation of MAC is its hierarchical structure, which consists of multiple "actor" and "critic" components. The actors explore the environment and propose actions, while the critics evaluate the quality of those actions and provide feedback to improve the actors. This multi-level interaction allows the algorithm to converge to the globally optimal policy without needing the mixing time oracle.
Specifically, the authors prove that MAC achieves -finite-time convergence to the global optimum in the average-reward setting. They also show that MAC is sample-efficient, meaning it can learn the optimal policy using a relatively small number of interactions with the environment.
The proposed algorithm builds on ideas from several previous RL methods, including natural policy gradient and actor-critic approaches. However, the multi-level structure and the elimination of the mixing time oracle requirement are important innovations that distinguish MAC from these prior works.
Critical Analysis
The paper presents a well-designed and theoretically sound algorithm for average-reward reinforcement learning. The authors have carefully addressed the limitations of previous methods and demonstrated the advantages of their approach.
One potential caveat is that the theoretical analysis assumes access to certain oracles and parameters that may be difficult to obtain in practice. For example, the authors assume knowledge of the problem's horizon and the existence of a policy evaluation oracle. In real-world applications, these assumptions may be challenging to satisfy.
Additionally, the paper does not provide extensive experimental results, and it would be valuable to see how the algorithm performs on a range of benchmark tasks. This would help validate the practical efficacy of the approach and identify any potential limitations or implementation challenges.
Overall, the "Multi-level Actor-Critic" algorithm represents an important contribution to the field of reinforcement learning. By overcoming the need for a mixing time oracle, the authors have opened up new possibilities for applying RL to a broader set of problems, particularly those involving long-term average rewards. Further research and practical evaluation will be needed to fully assess the impact and versatility of this approach.
Conclusion
This paper introduces a novel reinforcement learning algorithm called "Multi-level Actor-Critic" (MAC) that can achieve global optimality in average-reward settings without requiring a mixing time oracle. The key innovation is the algorithm's hierarchical structure, which allows it to converge to the globally optimal policy through the interaction of multiple actor and critic components.
The authors have provided a strong theoretical foundation for MAC, proving its finite-time convergence and sample efficiency. This represents an important advance in the field of RL, as it overcomes a significant limitation of many previous algorithms and expands the potential applications of reinforcement learning.
While the paper acknowledges some practical challenges, such as the need for certain oracles and parameters, the "Multi-level Actor-Critic" approach holds significant promise for enabling more robust and scalable reinforcement learning in real-world environments. Further research and development in this area could lead to substantial improvements in the performance and deployability of RL systems across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
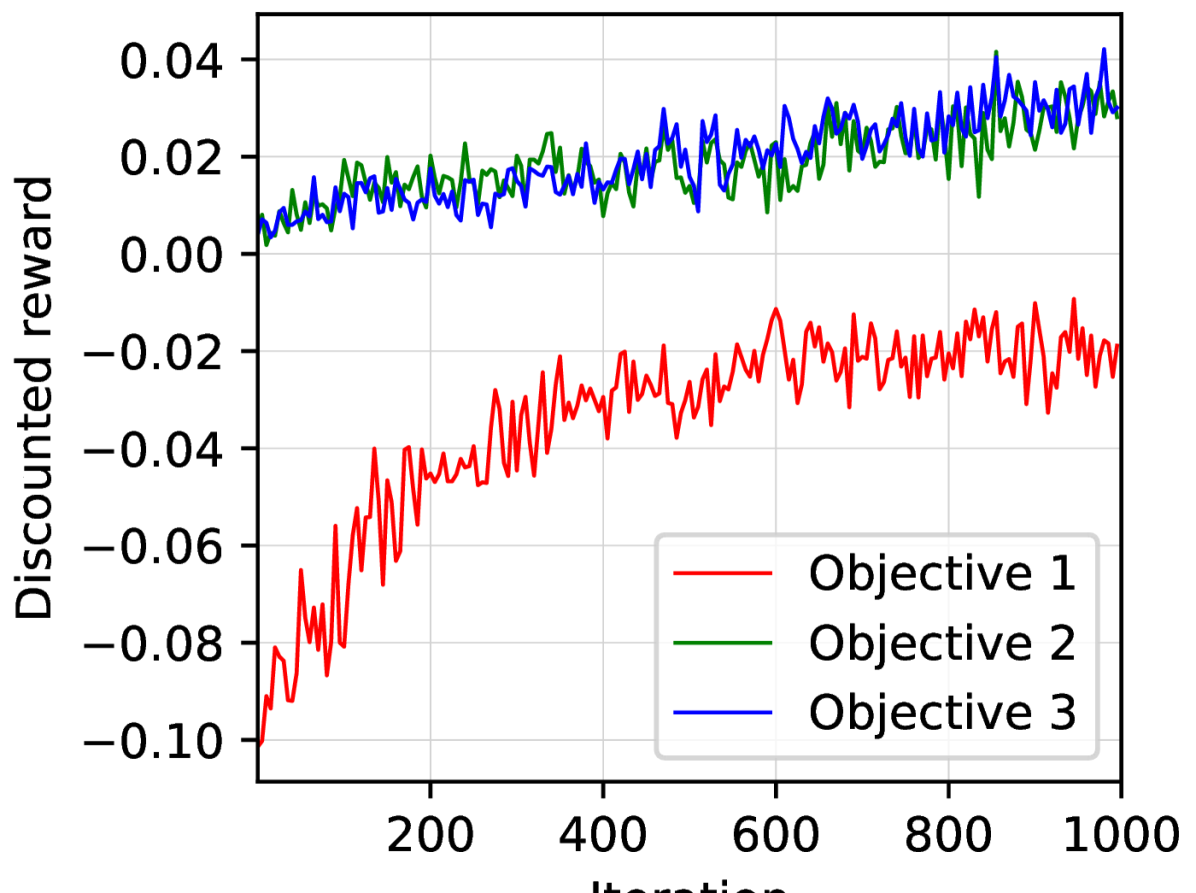
Finite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
Tianchen Zhou, FNU Hairi, Haibo Yang, Jia Liu, Tian Tong, Fan Yang, Michinari Momma, Yan Gao
0
0
Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
5/10/2024
🌿
Natural Policy Gradient and Actor Critic Methods for Constrained Multi-Task Reinforcement Learning
Sihan Zeng, Thinh T. Doan, Justin Romberg
0
0
Multi-task reinforcement learning (RL) aims to find a single policy that effectively solves multiple tasks at the same time. This paper presents a constrained formulation for multi-task RL where the goal is to maximize the average performance of the policy across tasks subject to bounds on the performance in each task. We consider solving this problem both in the centralized setting, where information for all tasks is accessible to a single server, and in the decentralized setting, where a network of agents, each given one task and observing local information, cooperate to find the solution of the globally constrained objective using local communication. We first propose a primal-dual algorithm that provably converges to the globally optimal solution of this constrained formulation under exact gradient evaluations. When the gradient is unknown, we further develop a sampled-based actor-critic algorithm that finds the optimal policy using online samples of state, action, and reward. Finally, we study the extension of the algorithm to the linear function approximation setting.
5/7/2024
⚙️
Two-Timescale Critic-Actor for Average Reward MDPs with Function Approximation
Prashansa Panda, Shalabh Bhatnagar
0
0
In recent years, there has been a lot of research activity focused on carrying out non-asymptotic convergence analyses for actor-critic algorithms. Recently a two-timescale critic-actor algorithm has been presented for the discounted cost setting in the look-up table case where the timescales of the actor and the critic are reversed and only asymptotic convergence shown. In our work, we present the first two-timescale critic-actor algorithm with function approximation in the long-run average reward setting and present the first finite-time non-asymptotic as well as asymptotic convergence analysis for such a scheme. We obtain optimal learning rates and prove that our algorithm achieves a sample complexity of $mathcal{tilde{O}}(epsilon^{-2.08})$ for the mean squared error of the critic to be upper bounded by $epsilon$ which is better than the one obtained for two-timescale actor-critic in a similar setting. A notable feature of our analysis is that unlike recent single-timescale actor-critic algorithms, we present a complete asymptotic convergence analysis of our scheme in addition to the finite-time bounds that we obtain and show that the (slower) critic recursion converges asymptotically to the attractor of an associated differential inclusion with actor parameters corresponding to local maxima of a perturbed average reward objective. We also show the results of numerical experiments on three benchmark settings and observe that our critic-actor algorithm performs on par and is in fact better than the other algorithms considered.
5/27/2024
🧠
Closing the Gap: Achieving Global Convergence (Last Iterate) of Actor-Critic under Markovian Sampling with Neural Network Parametrization
Mudit Gaur, Amrit Singh Bedi, Di Wang, Vaneet Aggarwal
0
0
The current state-of-the-art theoretical analysis of Actor-Critic (AC) algorithms significantly lags in addressing the practical aspects of AC implementations. This crucial gap needs bridging to bring the analysis in line with practical implementations of AC. To address this, we advocate for considering the MMCLG criteria: textbf{M}ulti-layer neural network parametrization for actor/critic, textbf{M}arkovian sampling, textbf{C}ontinuous state-action spaces, the performance of the textbf{L}ast iterate, and textbf{G}lobal optimality. These aspects are practically significant and have been largely overlooked in existing theoretical analyses of AC algorithms. In this work, we address these gaps by providing the first comprehensive theoretical analysis of AC algorithms that encompasses all five crucial practical aspects (covers MMCLG criteria). We establish global convergence sample complexity bounds of $tilde{mathcal{O}}left({epsilon^{-3}}right)$. We achieve this result through our novel use of the weak gradient domination property of MDP's and our unique analysis of the error in critic estimation.
6/12/2024