Towards Improving NAM-to-Speech Synthesis Intelligibility using Self-Supervised Speech Models

0

Sign in to get full access
Overview
- Improving the intelligibility of non-audible murmur (NAM) to speech synthesis using self-supervised speech models.
- NAM is a type of speech signal captured from the vibrations of the vocal tract without the acoustic excitation of the vocal folds.
- Self-supervised speech models can help enhance the intelligibility of NAM-to-speech synthesis.
Plain English Explanation
The paper explores ways to make non-audible murmur (NAM) to speech synthesis more intelligible. NAM is a type of speech signal captured from the movements of the vocal tract without the typical vocal fold vibrations. This makes it difficult to understand compared to normal speech.
The researchers investigate using self-supervised speech models to enhance the intelligibility of NAM-to-speech synthesis. Self-supervised models can learn useful speech representations without needing fully labeled training data. By leveraging these models, the researchers aim to improve the clarity and understandability of synthesized speech from NAM signals.
Technical Explanation
The paper proposes using self-supervised speech models to enhance the intelligibility of NAM-to-speech synthesis. The key ideas are:
- Leveraging self-supervised pre-trained speech models to extract rich speech representations from NAM signals.
- Finetuning these pre-trained models on NAM-speech pairs to adapt the representations for the NAM-to-speech task.
- Incorporating the self-supervised speech representations into a NAM-to-speech synthesis pipeline to improve the quality and intelligibility of the synthesized speech.
The paper evaluates the proposed approach on a NAM-to-speech dataset, demonstrating improvements in subjective and objective measures of intelligibility compared to baseline methods.
Critical Analysis
The paper presents a promising approach to improving NAM-to-speech synthesis, but a few potential limitations and areas for further research are worth noting:
- The experiments are conducted on a relatively small dataset, so the scalability and generalization of the findings to larger and more diverse datasets remains to be seen.
- The paper does not provide detailed comparisons to state-of-the-art methods for improving accented speech recognition, which could offer additional insights.
- Further research could explore the integration of phonetic-enhanced language modeling or other complementary techniques to further boost the intelligibility of NAM-to-speech synthesis.
Conclusion
This paper demonstrates the potential of leveraging self-supervised speech models to enhance the intelligibility of NAM-to-speech synthesis. By extracting rich speech representations and finetuning them for the NAM-to-speech task, the researchers were able to improve the quality and understandability of the synthesized speech. While the results are promising, further research is needed to fully realize the potential of this approach and address its limitations. Overall, this work contributes to the ongoing efforts to improve speech synthesis for non-standard speech signals, which could have important applications in assistive technologies and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Improving NAM-to-Speech Synthesis Intelligibility using Self-Supervised Speech Models
Neil Shah, Shirish Karande, Vineet Gandhi
We propose a novel approach to significantly improve the intelligibility in the Non-Audible Murmur (NAM)-to-speech conversion task, leveraging self-supervision and sequence-to-sequence (Seq2Seq) learning techniques. Unlike conventional methods that explicitly record ground-truth speech, our methodology relies on self-supervision and speech-to-speech synthesis to simulate ground-truth speech. Despite utilizing simulated speech, our method surpasses the current state-of-the-art (SOTA) by 29.08% improvement in the Mel-Cepstral Distortion (MCD) metric. Additionally, we present error rates and demonstrate our model's proficiency to synthesize speech in novel voices of interest. Moreover, we present a methodology for augmenting the existing CSTR NAM TIMIT Plus corpus, setting a benchmark with a Word Error Rate (WER) of 42.57% to gauge the intelligibility of the synthesized speech. Speech samples can be found at https://nam2speech.github.io/NAM2Speech/
Read more7/29/2024

0
Self-Supervised Models in Automatic Whispered Speech Recognition
Aref Farhadipour, Homa Asadi, Volker Dellwo
In automatic speech recognition, any factor that alters the acoustic properties of speech can pose a challenge to the system's performance. This paper presents a novel approach for automatic whispered speech recognition in the Irish dialect using the self-supervised WavLM model. Conventional automatic speech recognition systems often fail to accurately recognise whispered speech due to its distinct acoustic properties and the scarcity of relevant training data. To address this challenge, we utilized a pre-trained WavLM model, fine-tuned with a combination of whispered and normal speech data from the wTIMIT and CHAINS datasets, which include the English language in Singaporean and Irish dialects, respectively. Our baseline evaluation with the OpenAI Whisper model highlighted its limitations, achieving a Word Error Rate (WER) of 18.8% on whispered speech. In contrast, the proposed WavLM-based system significantly improved performance, achieving a WER of 9.22%. These results demonstrate the efficacy of our approach in recognising whispered speech and underscore the importance of tailored acoustic modeling for robust automatic speech recognition systems. This study provides valuable insights into developing effective automatic speech recognition solutions for challenging speech affected by whisper and dialect. The source codes for this paper are freely available.
Read more8/1/2024
0
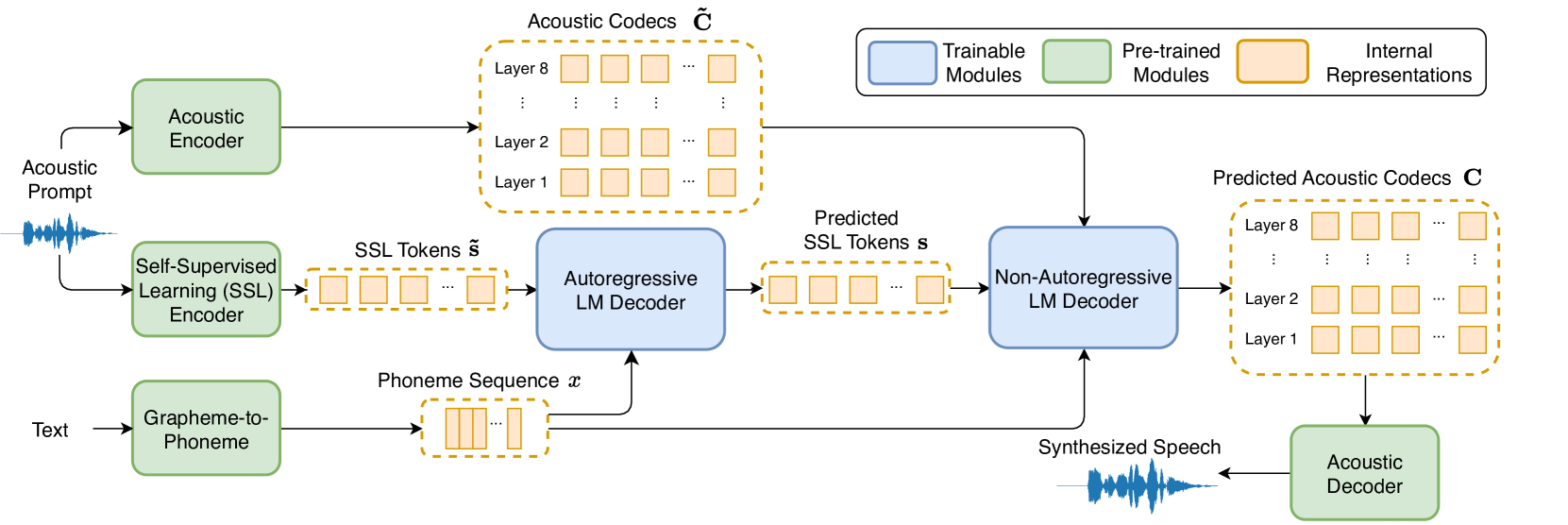
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024
0
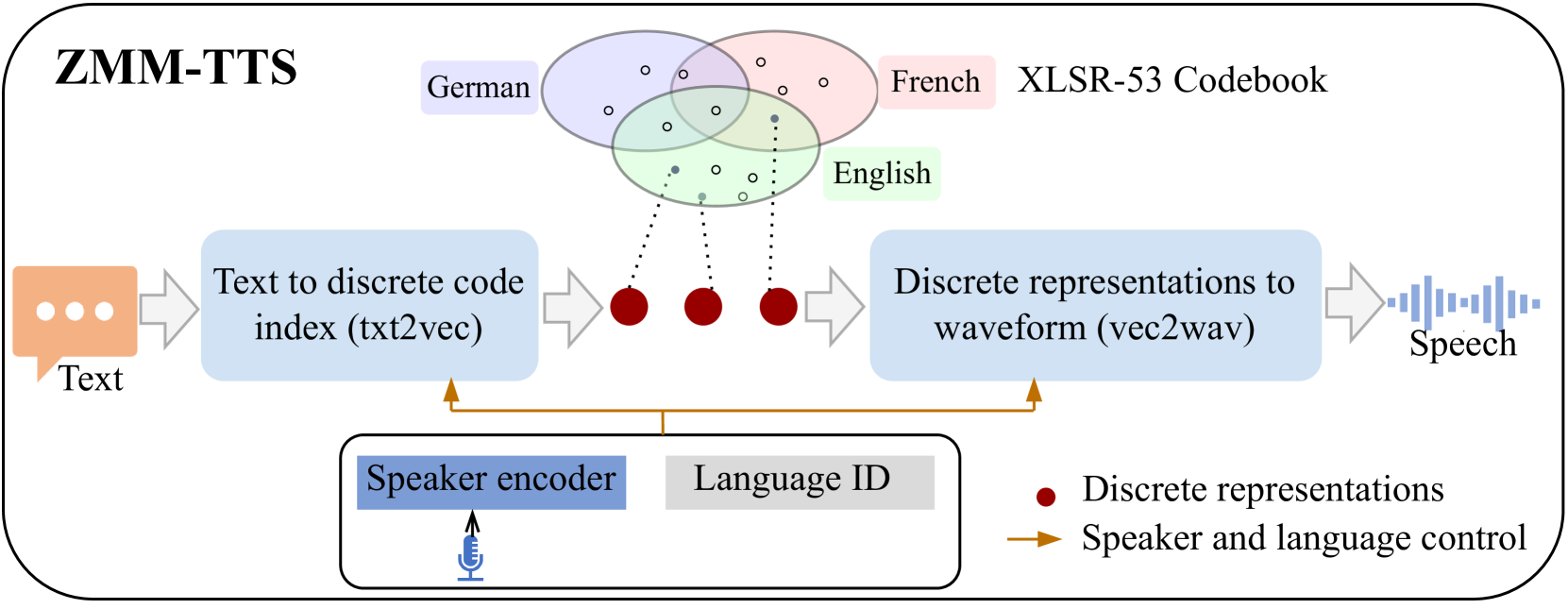
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024