Towards a Knowledge guided Multimodal Foundation Model for Spatio-Temporal Remote Sensing Applications

0
Sign in to get full access
Overview
- This paper proposes a knowledge-guided multimodal foundation model for spatio-temporal remote sensing applications.
- The model aims to leverage both visual and textual data to improve remote sensing tasks like classification, segmentation, and change detection.
- The key innovations include incorporating domain-specific knowledge and using a multimodal approach to enhance the model's understanding of remote sensing data.
Plain English Explanation
The researchers have developed a new type of artificial intelligence (AI) model that is designed to work with remote sensing data. Remote sensing involves using satellite or aerial imagery to study the Earth's surface and monitor changes over time.
The researchers wanted to create a model that could better understand and interpret this type of data, which often includes both visual information (the images) and textual information (metadata, captions, etc.). Their approach involves incorporating domain-specific knowledge about remote sensing into the AI model, as well as using a multimodal (combining visual and textual data) approach.
The goal is to create a more powerful and versatile AI model that can be used for a variety of remote sensing tasks, such as classifying different land cover types, detecting changes over time, and segmenting different features in the imagery. By incorporating domain knowledge and leveraging multiple data sources, the researchers hope to develop a model that can better understand and make sense of the complex and often dynamic remote sensing data.
Technical Explanation
The researchers propose a knowledge-guided multimodal foundation model for spatio-temporal remote sensing applications. The model consists of a visual encoder, a text encoder, and a fusion module that combines the visual and textual representations.
The visual encoder is a convolutional neural network (CNN) that takes in satellite or aerial imagery and extracts visual features. The text encoder is a transformer-based language model that processes associated metadata, captions, or other textual data.
The fusion module then combines the visual and textual representations using a series of attention mechanisms and feedforward layers. This allows the model to learn how visual and textual information are related and can be used together to improve performance on remote sensing tasks.
Additionally, the researchers incorporate domain-specific knowledge into the model, such as information about land cover types, geographic features, and spatio-temporal patterns. This knowledge is encoded as a set of embeddings that are used to guide the model's learning process and help it better understand the context and relationships within the remote sensing data.
The researchers evaluate their model on a variety of remote sensing benchmarks, including land cover classification, change detection, and object segmentation. They demonstrate that their knowledge-guided multimodal approach outperforms traditional unimodal and non-knowledge-guided models, highlighting the benefits of their proposed approach.
Critical Analysis
The researchers have presented an interesting and potentially impactful approach to developing more capable AI models for remote sensing applications. By incorporating domain-specific knowledge and using a multimodal fusion strategy, they aim to create a more comprehensive and versatile foundation model that can be applied to a variety of remote sensing tasks.
One potential limitation of the study is the reliance on the availability and quality of the domain knowledge used to guide the model. The researchers do not provide detailed information on how this knowledge was acquired or represented, which could be an important factor in the model's performance.
Additionally, the researchers' evaluation is primarily focused on benchmark tasks and datasets, which may not fully capture the real-world complexity and challenges of remote sensing applications. Further research and testing on more diverse and realistic datasets would be helpful to better understand the model's strengths, weaknesses, and potential for practical deployment.
Overall, the researchers' approach is promising and aligns with broader trends in AI research towards more unified and knowledge-rich models that can leverage multiple data sources and contextual information. As the field of remote sensing continues to evolve, this type of knowledge-guided multimodal approach may become increasingly important for developing more robust and adaptable AI solutions.
Conclusion
The paper presents a novel knowledge-guided multimodal foundation model for spatio-temporal remote sensing applications. By incorporating domain-specific knowledge and using a multimodal fusion strategy, the researchers aim to create a more comprehensive and versatile AI model that can be applied to a variety of remote sensing tasks.
The proposed approach shows promising results on benchmark datasets, and the researchers' focus on leveraging multiple data sources and contextual information aligns with broader trends in AI research. However, further research is needed to fully understand the model's strengths, weaknesses, and practical deployment potential, particularly in more diverse and realistic remote sensing scenarios.
Overall, this work represents an interesting and potentially impactful contribution to the field of remote sensing AI, with the potential to enable more powerful and adaptable solutions for a wide range of environmental monitoring and analysis applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards a Knowledge guided Multimodal Foundation Model for Spatio-Temporal Remote Sensing Applications
Praveen Ravirathinam, Ankush Khandelwal, Rahul Ghosh, Vipin Kumar
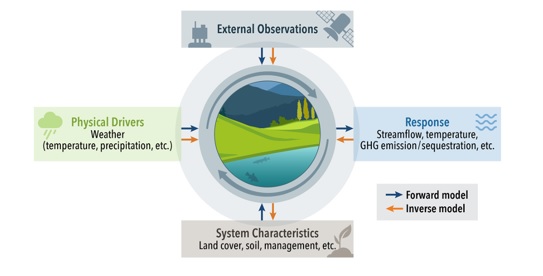
In recent years, there is increased interest in foundation models for geoscience due to vast amount of earth observing satellite imagery. Existing remote sensing foundation models make use of the various sources of spectral imagery to create large models pretrained on masked reconstruction task. The embeddings from these foundation models are then used for various downstream remote sensing applications. In this paper we propose a foundational modeling framework for remote sensing geoscience applications, that goes beyond these traditional single modality masked autoencoder family of foundation models. This framework leverages the knowledge guided principles that the spectral imagery captures the impact of the physical drivers on the environmental system, and that the relationship between them is governed by the characteristics of the system. Specifically, our method, called MultiModal Variable Step Forecasting (MM-VSF), uses mutlimodal data (spectral imagery and weather) as its input and a variable step forecasting task as its pretraining objective. In our evaluation we show forecasting of satellite imagery using weather can be used as an effective pretraining task for foundation models. We further show the effectiveness of the embeddings from MM-VSF on the downstream task of pixel wise crop mapping, when compared with a model trained in the traditional setting of single modality input and masked reconstruction based pretraining.
Read more7/30/2024
0
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
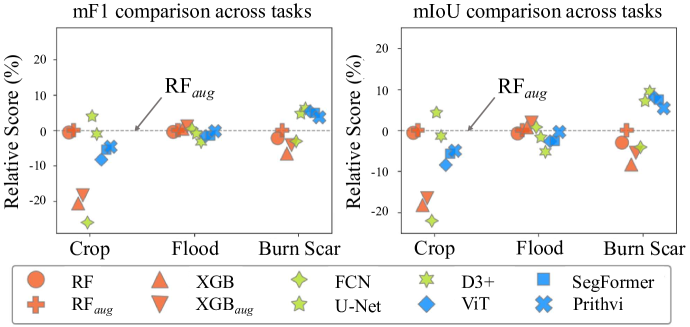
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
Read more4/19/2024
0
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Benedikt Blumenstiel, Viktoria Moor, Romeo Kienzler, Thomas Brunschwiler
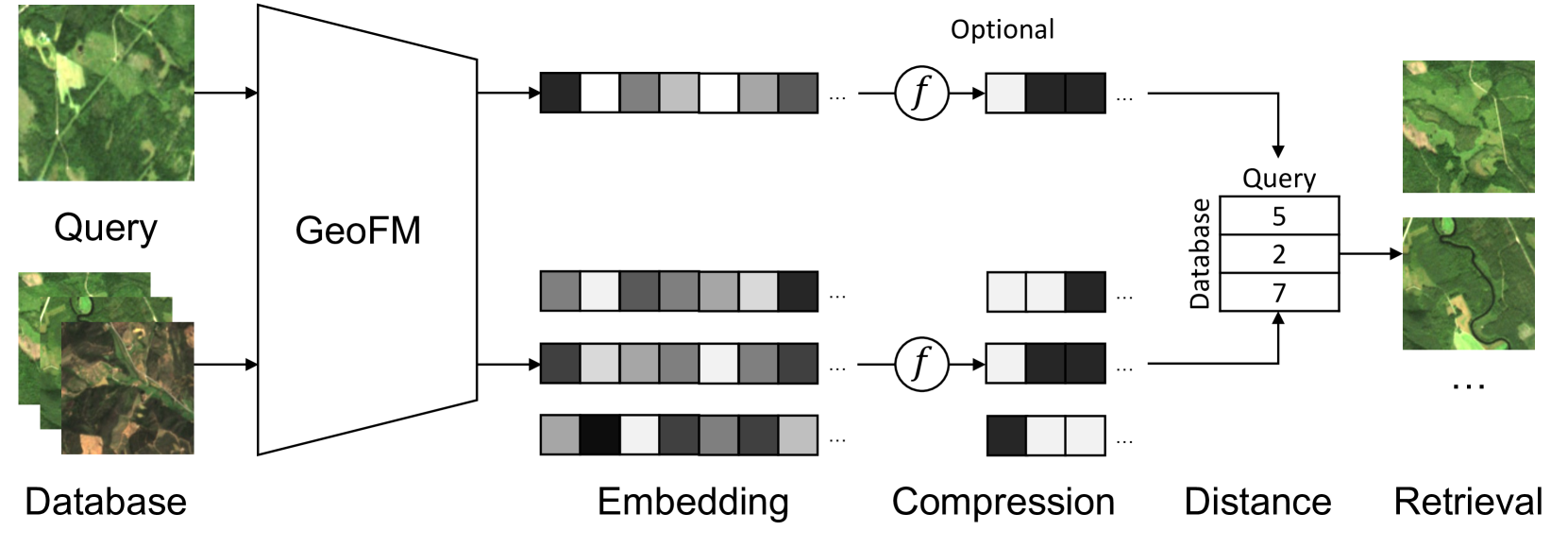
Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62% on BigEarthNet-43 and 44.51% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
Read more5/24/2024

0
One for All: Toward Unified Foundation Models for Earth Vision
Zhitong Xiong, Yi Wang, Fahong Zhang, Xiao Xiang Zhu
Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.
Read more5/29/2024