Towards stable training of parallel continual learning

0

Sign in to get full access
Overview
- This paper proposes a new approach to training parallel continual learning (PCL) models, which are a type of machine learning model that can learn new tasks sequentially without forgetting previous knowledge.
- The key challenges in PCL training include stability issues and a lack of principled ways to allocate model capacity.
- The authors present a technique called Stable Training in Parallel Continual Learning (STPCL) that aims to address these challenges.
Plain English Explanation
Machine learning models are often trained on a single task and struggle to learn new tasks without forgetting what they've learned before. Continual learning techniques try to address this by allowing models to learn new tasks sequentially while retaining knowledge from previous tasks.
Parallel continual learning (PCL) is a specific type of continual learning where multiple tasks are learned simultaneously. This can be more efficient than learning tasks one-by-one, but it also introduces new challenges around model stability and how to allocate limited model capacity between the different tasks.
The authors of this paper propose a new training approach called Stable Training in Parallel Continual Learning (STPCL) that aims to address these challenges. STPCL uses specialized techniques to maintain model stability and dynamically adjust the capacity allocated to each task during training.
Technical Explanation
The key aspects of the STPCL approach are:
-
Stability Regularization: The authors introduce a new regularization term that encourages the model to learn new tasks without significantly disrupting its performance on previous tasks. This helps maintain stability throughout the training process.
-
Dynamic Task Allocation: STPCL dynamically adjusts the capacity (i.e., the number of model parameters) allocated to each task during training. This helps ensure that tasks receive the appropriate amount of resources as training progresses.
-
Efficient Parallelization: The authors designed STPCL to be highly parallelizable, allowing multiple tasks to be trained simultaneously on different hardware resources. This improves training efficiency compared to sequential continual learning approaches.
The paper evaluates STPCL on several benchmark continual learning datasets and demonstrates that it outperforms existing PCL methods in terms of both stability and overall task performance. The authors also provide analysis on the importance of the stability regularization and dynamic task allocation components.
Critical Analysis
The authors acknowledge that STPCL, like other continual learning approaches, still faces challenges in scaling to extremely long sequences of tasks or dealing with significant task interference. Additionally, the dynamic task allocation scheme relies on having a priori knowledge of the task distribution, which may not always be available in real-world scenarios.
Further research could explore ways to make the task allocation more adaptive and robust to unknown task distributions. Convergence in continual learning with adaptive methods is an active area of research that could provide insights.
The authors also note that STPCL, while improving stability compared to previous PCL methods, still experiences some degree of "stability gap" - the gap between performance on initial and later tasks. Investigating techniques to overcome this stability gap could further enhance the effectiveness of PCL approaches.
Conclusion
This paper presents a novel training approach for parallel continual learning (PCL) models that addresses key challenges around stability and task allocation. The Stable Training in Parallel Continual Learning (STPCL) method introduces specialized techniques to maintain model stability and dynamically adjust the capacity dedicated to each task during training.
The authors demonstrate that STPCL outperforms existing PCL methods on benchmark datasets, suggesting it is a promising step forward in developing more robust and efficient continual learning systems. As the field of continual learning with pre-trained models continues to evolve, techniques like STPCL that can learn it or leave it will become increasingly important for enabling AI systems to continuously adapt and expand their capabilities over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards stable training of parallel continual learning
Li Yuepan, Fan Lyu, Yuyang Li, Wei Feng, Guangcan Liu, Fanhua Shang
Parallel Continual Learning (PCL) tasks investigate the training methods for continual learning with multi-source input, where data from different tasks are learned as they arrive. PCL offers high training efficiency and is well-suited for complex multi-source data systems, such as autonomous vehicles equipped with multiple sensors. However, at any time, multiple tasks need to be trained simultaneously, leading to severe training instability in PCL. This instability manifests during both forward and backward propagation, where features are entangled and gradients are conflict. This paper introduces Stable Parallel Continual Learning (SPCL), a novel approach that enhances the training stability of PCL for both forward and backward propagation. For the forward propagation, we apply Doubly-block Toeplit (DBT) Matrix based orthogonality constraints to network parameters to ensure stable and consistent propagation. For the backward propagation, we employ orthogonal decomposition for gradient management stabilizes backpropagation and mitigates gradient conflicts across tasks. By optimizing gradients by ensuring orthogonality and minimizing the condition number, SPCL effectively stabilizing the gradient descent in complex optimization tasks. Experimental results demonstrate that SPCL outperforms state-of-the-art methjods and achieve better training stability.
Read more7/12/2024
0
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
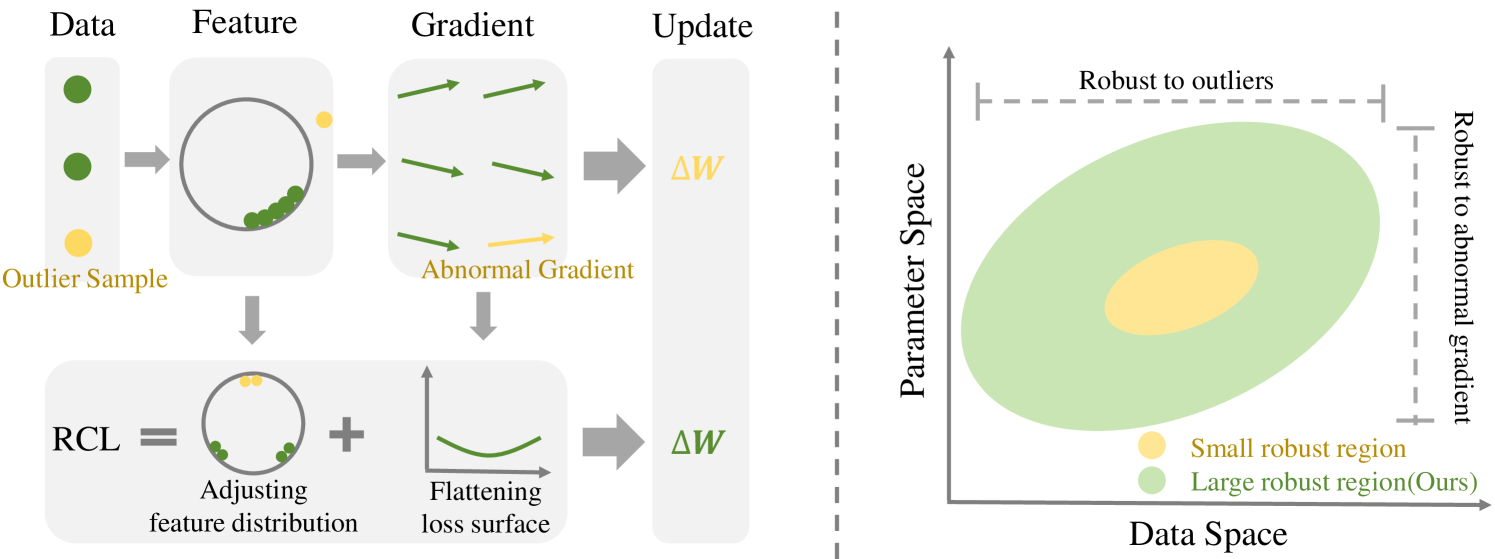
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Read more5/28/2024
0
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jingren Liu, Zhong Ji, YunLong Yu, Jiale Cao, Yanwei Pang, Jungong Han, Xuelong Li
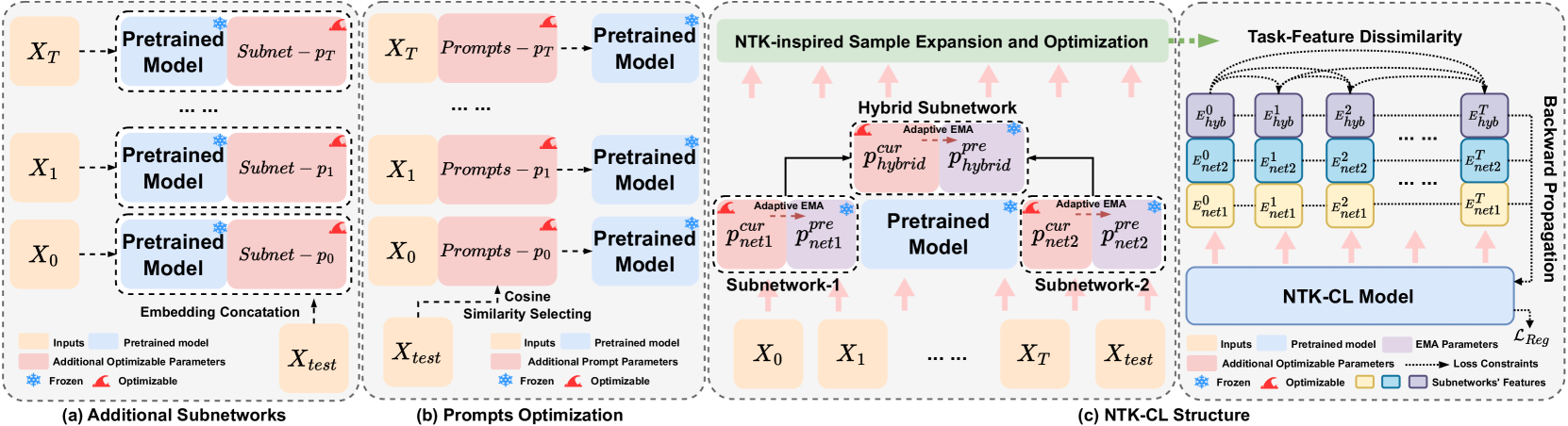
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Read more7/25/2024
0
On the Convergence of Continual Learning with Adaptive Methods
Seungyub Han, Yeongmo Kim, Taehyun Cho, Jungwoo Lee
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
Read more4/16/2024