Towards Verifiable Text Generation with Symbolic References
2311.09188
0
0
🛸
Abstract
LLMs are vulnerable to hallucinations, and thus their outputs generally require laborious human verification for high-stakes applications. To this end, we propose symbolically grounded generation (SymGen) as a simple approach for enabling easier manual validation of an LLM's output. SymGen prompts an LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format). The references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. Across a range of data-to-text and question-answering experiments, we find that LLMs are able to directly output text that makes use of accurate symbolic references while maintaining fluency and factuality. In a human study we further find that such annotations can streamline human verification of machine-generated text. Our code will be available at http://symgen.github.io.
Create account to get full access
Overview
- Large language models (LLMs) can generate human-like text, but their outputs often contain "hallucinations" or factual errors that require manual verification, especially for high-stakes applications.
- The researchers propose a technique called "symbolically grounded generation" (SymGen) to address this issue.
- SymGen prompts the LLM to interleave its output with explicit references to data fields, allowing for easier manual validation of the generated text.
- The researchers find that LLMs can successfully incorporate these symbolic references while maintaining fluency and factuality, and that the annotations can streamline human verification.
Plain English Explanation
The paper focuses on a challenge with large language models (LLMs) - they can sometimes generate text that includes made-up or incorrect information, known as "hallucinations." This is a problem, especially for important applications where the output needs to be 100% accurate.
To address this, the researchers developed a technique called "symbolically grounded generation" (SymGen). With SymGen, the LLM is prompted to include special markers or references in its output that point back to the original data sources. This allows human reviewers to quickly see where the information in the text is coming from, making it easier to verify that the LLM's output is accurate and truthful.
In their experiments, the researchers found that LLMs were able to successfully integrate these symbolic references into their text without losing coherence or factual correctness. And when humans reviewed the annotated text, they were able to validate the information more efficiently compared to text without the extra references.
Overall, this approach helps make LLM outputs more transparent and trustworthy, which is crucial for high-stakes applications like medical diagnosis or financial planning where mistakes could have serious consequences.
Technical Explanation
The researchers propose a technique called "symbolically grounded generation" (SymGen) to address the problem of hallucinations in large language models (LLMs). SymGen prompts the LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format).
These symbolic references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. For example, if the LLM generates text about a person's age, it might include a reference like "[AGE]" to indicate that this information came from the "age" field in the original data.
Across experiments on data-to-text generation and question-answering tasks, the researchers found that LLMs were able to successfully incorporate these symbolic references while maintaining fluency and factuality in the output. In a human study, they further demonstrated that the annotated text streamlined the process of verifying the accuracy of the LLM's outputs.
This work builds on prior research on techniques like code-aware prompting, knowledge-grounded text generation, and retrieval-augmented generation to reduce hallucinations in LLMs. By making the provenance of the text more transparent, SymGen represents a simple yet effective approach to enable easier manual validation of LLM outputs, which is crucial for high-stakes applications.
Critical Analysis
The researchers acknowledge some limitations of their work. For example, they note that SymGen may not be suitable for all types of generation tasks, such as open-ended creative writing. Additionally, the effectiveness of SymGen may depend on the quality and completeness of the conditioning data, which could be a challenge in real-world scenarios.
While the human study demonstrated the benefits of SymGen for streamlining verification, it would be valuable to further investigate the scalability and robustness of this approach as the size and complexity of the generated text increases. There may also be opportunities to explore more automated techniques for verifying LLM outputs, building on related research in deciphering textual authenticity.
Overall, the SymGen approach represents a promising step towards making LLM outputs more transparent and trustworthy. However, as with any technology, continued research and refinement will be necessary to address the evolving challenges and requirements of high-stakes applications.
Conclusion
The paper presents a technique called "symbolically grounded generation" (SymGen) to address the problem of hallucinations in large language models (LLMs). By prompting LLMs to interleave their outputs with explicit symbolic references to the underlying data, SymGen makes it easier for human reviewers to verify the accuracy and provenance of the generated text.
The researchers' experiments demonstrate that LLMs can successfully incorporate these symbolic references while maintaining fluency and factuality, and that the annotated text can streamline the human verification process. This work represents an important step towards enabling the safe and trustworthy deployment of LLMs in high-stakes applications where reliability is crucial.
As the capabilities of LLMs continue to advance, techniques like SymGen will become increasingly valuable in bridging the gap between the power of these models and the need for reliable, verifiable outputs. The research community's continued efforts to address the challenges of hallucination and transparency will be key to unlocking the full potential of large language models for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Specify What? Enhancing Neural Specification Synthesis by Symbolic Methods
George Granberry, Wolfgang Ahrendt, Moa Johansson
0
0
We investigate how combinations of Large Language Models (LLMs) and symbolic analyses can be used to synthesise specifications of C programs. The LLM prompts are augmented with outputs from two formal methods tools in the Frama-C ecosystem, Pathcrawler and EVA, to produce C program annotations in the specification language ACSL. We demonstrate how the addition of symbolic analysis to the workflow impacts the quality of annotations: information about input/output examples from Pathcrawler produce more context-aware annotations, while the inclusion of EVA reports yields annotations more attuned to runtime errors. In addition, we show that the method infers rather the programs intent than its behaviour, by generating specifications for buggy programs and observing robustness of the result against bugs.
6/26/2024

SymbolicAI: A framework for logic-based approaches combining generative models and solvers
Marius-Constantin Dinu, Claudiu Leoveanu-Condrei, Markus Holzleitner, Werner Zellinger, Sepp Hochreiter
0
0
We introduce SymbolicAI, a versatile and modular framework employing a logic-based approach to concept learning and flow management in generative processes. SymbolicAI enables the seamless integration of generative models with a diverse range of solvers by treating large language models (LLMs) as semantic parsers that execute tasks based on both natural and formal language instructions, thus bridging the gap between symbolic reasoning and generative AI. We leverage probabilistic programming principles to tackle complex tasks, and utilize differentiable and classical programming paradigms with their respective strengths. The framework introduces a set of polymorphic, compositional, and self-referential operations for multi-modal data that connects multi-step generative processes and aligns their outputs with user objectives in complex workflows. As a result, we can transition between the capabilities of various foundation models with in-context learning capabilities and specialized, fine-tuned models or solvers proficient in addressing specific problems. Through these operations based on in-context learning our framework enables the creation and evaluation of explainable computational graphs. Finally, we introduce a quality measure and its empirical score for evaluating these computational graphs, and propose a benchmark that compares various state-of-the-art LLMs across a set of complex workflows. We refer to the empirical score as the Vector Embedding for Relational Trajectory Evaluation through Cross-similarity, or VERTEX score for short. The framework codebase and benchmark are linked below.
5/28/2024
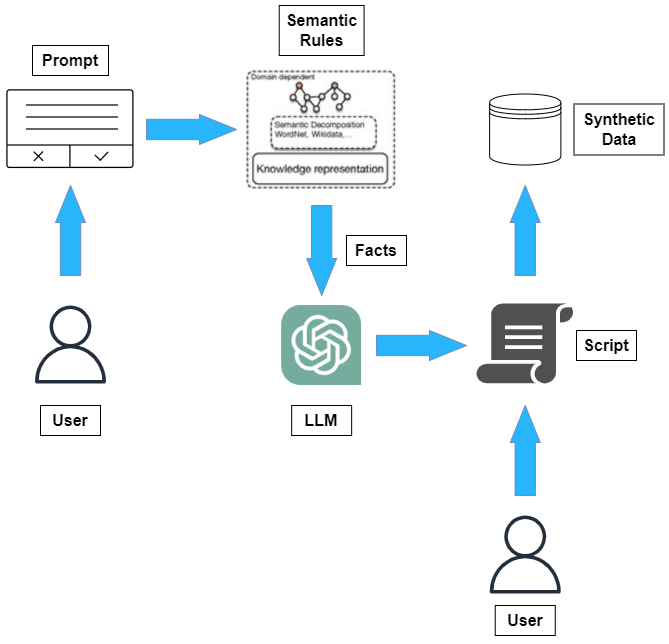
NeSy is alive and well: A LLM-driven symbolic approach for better code comment data generation and classification
Hanna Abi Akl
0
0
We present a neuro-symbolic (NeSy) workflow combining a symbolic-based learning technique with a large language model (LLM) agent to generate synthetic data for code comment classification in the C programming language. We also show how generating controlled synthetic data using this workflow fixes some of the notable weaknesses of LLM-based generation and increases the performance of classical machine learning models on the code comment classification task. Our best model, a Neural Network, achieves a Macro-F1 score of 91.412% with an increase of 1.033% after data augmentation.
5/27/2024

SynCode: LLM Generation with Grammar Augmentation
Shubham Ugare, Tarun Suresh, Hangoo Kang, Sasa Misailovic, Gagandeep Singh
0
0
LLMs are widely used in complex AI applications. These applications underscore the need for LLM outputs to adhere to a specific format, for their integration with other components in the systems. Typically the format rules e.g., for data serialization formats such as JSON, YAML, or Code in Programming Language are expressed as context-free grammar (CFG). Due to the hallucinations and unreliability of LLMs, instructing LLMs to adhere to specified syntax becomes an increasingly important challenge. We present SynCode, a novel framework for efficient and general syntactical decoding with LLMs, to address this challenge. SynCode leverages the CFG of a formal language, utilizing an offline-constructed efficient lookup table called DFA mask store based on the discrete finite automaton (DFA) of the language grammar terminals. We demonstrate SynCode's soundness and completeness given the CFG of the formal language, presenting its ability to retain syntactically valid tokens while rejecting invalid ones. SynCode seamlessly integrates with any language defined by CFG, as evidenced by experiments focusing on generating JSON, Python, and Go outputs. Our experiments evaluating the effectiveness of SynCode for JSON generation demonstrate that SynCode eliminates all syntax errors and significantly outperforms state-of-the-art baselines. Furthermore, our results underscore how SynCode significantly reduces 96.07% of syntax errors in generated Python and Go code, showcasing its substantial impact on enhancing syntactical precision in LLM generation. Our code is available at https://github.com/uiuc-focal-lab/syncode
4/30/2024