Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study with Linear Models

0
🛠️
Sign in to get full access
Overview
- Transformers can learn from demonstrations without updating their parameters, a process known as in-context learning (ICL).
- Recent research suggests Transformers may use Gradient Descent, a first-order optimization method, to perform ICL.
- This paper instead shows that Transformers learn to approximate higher-order optimization methods, such as Iterative Newton's Method, for ICL.
Plain English Explanation
Transformers are a type of artificial intelligence model that can learn new tasks by observing examples, without having to update their internal parameters. This process is known as in-context learning (ICL).
Previous research proposed that Transformers might be using a technique called Gradient Descent to learn from these examples. Gradient Descent is a common optimization method used in machine learning. However, this new paper suggests that Transformers are actually learning to use more advanced optimization methods, like Iterative Newton's Method.
The key insight is that Transformers and Iterative Newton's Method have a similar rate of convergence when solving linear regression problems. This means they both get to the same answer at roughly the same speed. In contrast, Gradient Descent is much slower.
The paper also shows that Transformers can learn well even on data that is difficult to optimize, where Gradient Descent struggles but Iterative Newton's Method succeeds. Finally, the researchers provide a mathematical proof that Transformers can implement multiple iterations of Newton's Method using just a few additional layers.
Technical Explanation
The researchers demonstrate that Transformers learn to approximate higher-order optimization methods, such as Iterative Newton's Method, to perform ICL, rather than using the first-order Gradient Descent method as previously proposed.
For in-context linear regression tasks, Transformers and Iterative Newton's Method exhibit a similar exponential convergence rate, which is much faster than the convergence of Gradient Descent. Empirically, the researchers show that the predictions from successive Transformer layers closely match the iterative steps of Newton's Method, with each middle layer roughly computing 3 iterations.
In contrast, Gradient Descent converges exponentially more slowly on these problems. The paper also shows that Transformers can learn in-context on ill-conditioned data, a setting where Gradient Descent struggles but Iterative Newton's Method succeeds.
To corroborate these empirical findings, the researchers prove that Transformers can implement
Critical Analysis
The paper provides compelling evidence that Transformers learn to approximate higher-order optimization methods, rather than using first-order Gradient Descent, for in-context learning tasks. This suggests that Transformers have more sophisticated learning capabilities than previously understood.
One potential limitation is that the analysis is focused on linear regression problems. It would be valuable to extend the research to more complex non-linear tasks and investigate whether Transformers employ similar higher-order optimization techniques in those settings.
Additionally, the paper does not explore the broader implications of Transformers' ability to learn higher-order optimization methods. Further research could investigate how this capability affects Transformers' performance on a wider range of machine learning problems and their potential applications in fields like scientific computing and numerical optimization.
Conclusion
This paper challenges the prevailing view that Transformers use Gradient Descent for in-context learning. Instead, it demonstrates that Transformers learn to approximate more advanced optimization methods, like Iterative Newton's Method, which allow them to learn more efficiently from demonstrations.
This discovery sheds new light on the underlying mechanisms of Transformers' impressive learning capabilities and opens up avenues for further research into how these models can be leveraged for a variety of machine learning tasks and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study with Linear Models
Deqing Fu, Tian-Qi Chen, Robin Jia, Vatsal Sharan
Transformers excel at in-context learning (ICL) -- learning from demonstrations without parameter updates -- but how they do so remains a mystery. Recent work suggests that Transformers may internally run Gradient Descent (GD), a first-order optimization method, to perform ICL. In this paper, we instead demonstrate that Transformers learn to approximate higher-order optimization methods for ICL. For in-context linear regression, Transformers share a similar convergence rate as Iterative Newton's Method; both are exponentially faster than GD. Empirically, predictions from successive Transformer layers closely match different iterations of Newton's Method linearly, with each middle layer roughly computing 3 iterations; thus, Transformers and Newton's method converge at roughly the same rate. In contrast, Gradient Descent converges exponentially more slowly. We also show that Transformers can learn in-context on ill-conditioned data, a setting where Gradient Descent struggles but Iterative Newton succeeds. Finally, to corroborate our empirical findings, we prove that Transformers can implement $k$ iterations of Newton's method with $k + mathcal{O}(1)$ layers.
Read more6/4/2024

0
Transformers are Minimax Optimal Nonparametric In-Context Learners
Juno Kim, Tai Nakamaki, Taiji Suzuki
In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we study the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error bounds for a transformer composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise $gamma$-smooth class. We show that sufficiently trained transformers can achieve -- and even improve upon -- the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the emph{pretraining} and emph{in-context} generalization gaps. Furthermore, we establish information-theoretic lower bounds for meta-learners w.r.t. both the number of tasks and in-context examples. These findings shed light on the roles of task diversity and representation learning for ICL.
Read more8/23/2024
🚀
0
Do pretrained Transformers Learn In-Context by Gradient Descent?
Lingfeng Shen, Aayush Mishra, Daniel Khashabi
The emergence of In-Context Learning (ICL) in LLMs remains a remarkable phenomenon that is partially understood. To explain ICL, recent studies have created theoretical connections to Gradient Descent (GD). We ask, do such connections hold up in actual pre-trained language models? We highlight the limiting assumptions in prior works that make their setup considerably different from the practical setup in which language models are trained. For example, their experimental verification uses emph{ICL objective} (training models explicitly for ICL), which differs from the emergent ICL in the wild. Furthermore, the theoretical hand-constructed weights used in these studies have properties that don't match those of real LLMs. We also look for evidence in real models. We observe that ICL and GD have different sensitivity to the order in which they observe demonstrations. Finally, we probe and compare the ICL vs. GD hypothesis in a natural setting. We conduct comprehensive empirical analyses on language models pre-trained on natural data (LLaMa-7B). Our comparisons of three performance metrics highlight the inconsistent behavior of ICL and GD as a function of various factors such as datasets, models, and the number of demonstrations. We observe that ICL and GD modify the output distribution of language models differently. These results indicate that emph{the equivalence between ICL and GD remains an open hypothesis} and calls for further studies.
Read more6/4/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
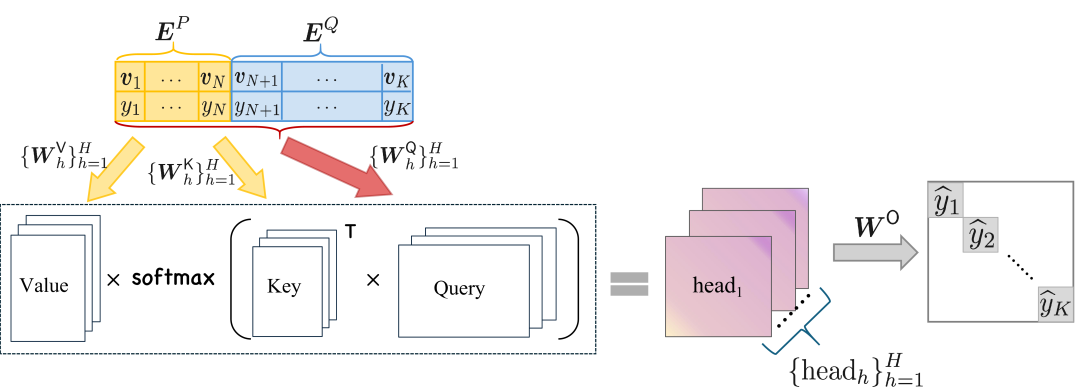
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more8/21/2024