TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction

0

Sign in to get full access
Overview
- This paper presents a novel method called Transic for transferring simulated policies to the real world by learning from online corrections.
- The key idea is to use a human operator to provide real-time corrections to the agent's actions during deployment, and then use this feedback to fine-tune the policy and bridge the sim-to-real gap.
- The authors evaluate Transic on several robot manipulation tasks and show that it can outperform baselines that do not leverage online corrections.
Plain English Explanation
The researchers developed a new technique called Transic to help robots trained in simulation work better in the real world. The core idea is to have a human operator watch the robot and provide small corrections to its actions as it's operating. The robot then learns from these corrections to adjust its behavior and improve over time.
This is useful because it can be challenging to perfectly recreate the real world in a simulation. Even the best simulated environments will have some differences from reality. By having a human provide feedback, the robot can learn to adapt and overcome those differences.
The researchers tested Transic on various robotic manipulation tasks, like picking up and moving objects. They found that Transic allowed the robots to perform better in the real world compared to other methods that don't use the human feedback. This shows the potential for Transic to help bridge the gap between simulated robot training and real-world deployment.
Technical Explanation
The Transic: Sim-to-Real Policy Transfer by Learning from Online Correction paper proposes a novel method for transferring simulated robot policies to the real world. The key idea is to leverage human operators to provide real-time corrections to the agent's actions during deployment, and then use this feedback to fine-tune the policy and bridge the sim-to-real gap.
Specifically, the Transic framework consists of three main components:
- A neural network policy that maps observations to actions.
- A human-in-the-loop correction module that allows an operator to provide feedback on the agent's actions.
- A policy update module that uses the human corrections to fine-tune the neural network policy.
During deployment, the agent executes its policy in the real-world environment. The human operator observes the agent's actions and can provide corrective feedback by adjusting the agent's actions in real-time. This feedback is then used to update the neural network policy, allowing it to better match the true dynamics of the real-world environment.
The authors evaluate Transic on several robot manipulation tasks and show that it can outperform baselines that do not leverage online corrections from the human operator. They also demonstrate the effectiveness of Transic in bridging the sim-to-real gap and transferring skills learned in simulation to the real world.
Critical Analysis
The Transic method presented in the paper is a promising approach for improving the real-world performance of robots trained in simulation. By leveraging human feedback, the technique can help address the discrepancies between simulated and real-world environments that often hamper sim-to-real transfer.
However, the paper does not address some potential limitations of the Transic framework. For example, the reliance on a human operator may limit the scalability of the approach, as it requires constant supervision during deployment. Additionally, the quality and consistency of the human feedback may vary, which could introduce noise and bias into the policy updates.
Further research could explore ways to reduce the human oversight required, such as by developing more robust and autonomous correction mechanisms. Investigating the transfer learning capabilities of the Transic approach across different tasks and environments would also be valuable.
Overall, the Transic method represents an important step forward in bridging the sim-to-real gap, and the insights and techniques presented in the paper could inspire future advancements in this area.
Conclusion
The Transic paper introduces a novel approach for transferring simulated robot policies to the real world by leveraging online corrections from human operators. By incorporating this human feedback into the policy update process, the technique can help robots adapt to the discrepancies between simulation and reality, leading to improved real-world performance.
The authors' evaluations demonstrate the effectiveness of Transic on various robot manipulation tasks, highlighting its potential to enhance the deployment of robots trained in simulation. While the method has some limitations, the core ideas and insights presented in the paper represent a significant contribution to the field of sim-to-real transfer learning, and could inspire further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction
Yunfan Jiang, Chen Wang, Ruohan Zhang, Jiajun Wu, Li Fei-Fei
Learning in simulation and transferring the learned policy to the real world has the potential to enable generalist robots. The key challenge of this approach is to address simulation-to-reality (sim-to-real) gaps. Previous methods often require domain-specific knowledge a priori. We argue that a straightforward way to obtain such knowledge is by asking humans to observe and assist robot policy execution in the real world. The robots can then learn from humans to close various sim-to-real gaps. We propose TRANSIC, a data-driven approach to enable successful sim-to-real transfer based on a human-in-the-loop framework. TRANSIC allows humans to augment simulation policies to overcome various unmodeled sim-to-real gaps holistically through intervention and online correction. Residual policies can be learned from human corrections and integrated with simulation policies for autonomous execution. We show that our approach can achieve successful sim-to-real transfer in complex and contact-rich manipulation tasks such as furniture assembly. Through synergistic integration of policies learned in simulation and from humans, TRANSIC is effective as a holistic approach to addressing various, often coexisting sim-to-real gaps. It displays attractive properties such as scaling with human effort. Videos and code are available at https://transic-robot.github.io/
Read more9/23/2024

0
DrEureka: Language Model Guided Sim-To-Real Transfer
Yecheng Jason Ma, William Liang, Hung-Ju Wang, Sam Wang, Yuke Zhu, Linxi Fan, Osbert Bastani, Dinesh Jayaraman
Transferring policies learned in simulation to the real world is a promising strategy for acquiring robot skills at scale. However, sim-to-real approaches typically rely on manual design and tuning of the task reward function as well as the simulation physics parameters, rendering the process slow and human-labor intensive. In this paper, we investigate using Large Language Models (LLMs) to automate and accelerate sim-to-real design. Our LLM-guided sim-to-real approach, DrEureka, requires only the physics simulation for the target task and automatically constructs suitable reward functions and domain randomization distributions to support real-world transfer. We first demonstrate that our approach can discover sim-to-real configurations that are competitive with existing human-designed ones on quadruped locomotion and dexterous manipulation tasks. Then, we showcase that our approach is capable of solving novel robot tasks, such as quadruped balancing and walking atop a yoga ball, without iterative manual design.
Read more6/5/2024
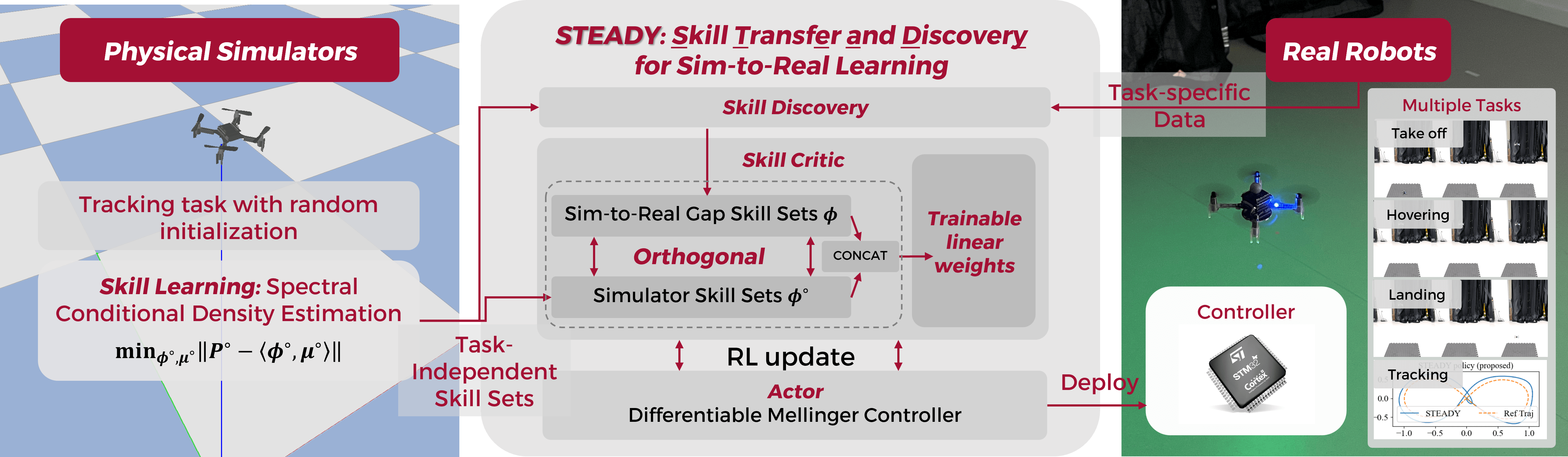
0
Skill Transfer and Discovery for Sim-to-Real Learning: A Representation-Based Viewpoint
Haitong Ma, Zhaolin Ren, Bo Dai, Na Li
We study sim-to-real skill transfer and discovery in the context of robotics control using representation learning. We draw inspiration from spectral decomposition of Markov decision processes. The spectral decomposition brings about representation that can linearly represent the state-action value function induced by any policies, thus can be regarded as skills. The skill representations are transferable across arbitrary tasks with the same transition dynamics. Moreover, to handle the sim-to-real gap in the dynamics, we propose a skill discovery algorithm that learns new skills caused by the sim-to-real gap from real-world data. We promote the discovery of new skills by enforcing orthogonal constraints between the skills to learn and the skills from simulators, and then synthesize the policy using the enlarged skill sets. We demonstrate our methodology by transferring quadrotor controllers from simulators to Crazyflie 2.1 quadrotors. We show that we can learn the skill representations from a single simulator task and transfer these to multiple different real-world tasks including hovering, taking off, landing and trajectory tracking. Our skill discovery approach helps narrow the sim-to-real gap and improve the real-world controller performance by up to 30.2%.
Read more4/9/2024

0
Sim-to-real Transfer of Deep Reinforcement Learning Agents for Online Coverage Path Planning
Arvi Jonnarth, Ola Johansson, Michael Felsberg
Sim-to-real transfer presents a difficult challenge, where models trained in simulation are to be deployed in the real world. The distribution shift between the two settings leads to biased representations of the dynamics, and thus to suboptimal predictions in the real-world environment. In this work, we tackle the challenge of sim-to-real transfer of reinforcement learning (RL) agents for coverage path planning (CPP). In CPP, the task is for a robot to find a path that covers every point of a confined area. Specifically, we consider the case where the environment is unknown, and the agent needs to plan the path online while mapping the environment. We bridge the sim-to-real gap through a semi-virtual environment, including a real robot and real-time aspects, while utilizing a simulated sensor and obstacles to enable environment randomization and automated episode resetting. We investigate what level of fine-tuning is needed for adapting to a realistic setting, comparing to an agent trained solely in simulation. We find that a high inference frequency allows first-order Markovian policies to transfer directly from simulation, while higher-order policies can be fine-tuned to further reduce the sim-to-real gap. Moreover, they can operate at a lower frequency, thus reducing computational requirements. In both cases, our approaches transfer state-of-the-art results from simulation to the real domain, where direct learning would take in the order of weeks with manual interaction, that is, it would be completely infeasible.
Read more8/20/2024