The Trembling-Hand Problem for LTLf Planning

0
🧪
Sign in to get full access
Overview
- This paper examines the problem of an agent trying to achieve a goal over time, but with the potential for mistakes or imprecision in its actions due to a "trembling hand".
- The authors study this "trembling-hand" problem in the context of reasoning about actions and planning for temporally extended goals expressed in Linear Temporal Logic on finite traces (LTLf).
- The goal is to synthesize a strategy (or plan) that maximizes the probability of satisfying the LTLf goal, despite the agent's potential mistakes.
- The authors consider both deterministic and nondeterministic (adversarial) environments.
Plain English Explanation
Imagine you're trying to complete a task over time, but your hand shakes a little, so you might accidentally do the wrong thing sometimes. This paper looks at how to plan for that situation, specifically when the task is expressed as a temporal logic goal that needs to be achieved.
The key idea is to find a plan (or strategy) that has the best chance of satisfying the goal, even though the agent might make some unintended mistakes along the way due to the "trembling hand" problem. This is important in many real-world situations where agents (like robots or autonomous systems) need to reliably achieve complex goals over time.
The paper considers two different types of environments: deterministic, where the outcomes of actions are known, and nondeterministic (or adversarial), where there's uncertainty or even an adversary trying to interfere. For each case, the authors propose solution techniques using Markov Decision Processes to model the problem and find the best plan.
Technical Explanation
The key technical contribution of this paper is the formulation and solution of the "trembling-hand" problem in the context of reasoning about actions and planning for temporally extended goals expressed in Linear Temporal Logic on finite traces (LTLf).
In this problem, the agent aims to achieve its LTLf goal, but with a certain probability of accidentally performing unintended actions due to faults or imprecision in its action selection mechanism. The authors propose solution techniques for both deterministic and nondeterministic (adversarial) domains.
For the deterministic case, the authors model the problem using a Markov Decision Process (MDP) and provide an algorithm to synthesize an optimal strategy that maximizes the probability of satisfying the LTLf goal.
For the nondeterministic case, the authors introduce Markov Decision Processes with Set-valued Transitions (MDPSTs) to capture both the environmental nondeterminism and the agent's potential action instruction errors. They then present an algorithm to find the optimal strategy in this setting.
The authors formally prove the correctness of their solution techniques and demonstrate their effectiveness through experimental evaluation on a proof-of-concept implementation.
Critical Analysis
The paper presents a novel and relevant problem formulation, addressing the practical challenge of achieving temporally extended goals in the face of potential action execution errors. The proposed solutions, based on MDPs and MDPSTs, are technically sound and the experimental results suggest the approaches are effective.
However, the paper does not discuss potential limitations or caveats of the proposed techniques. For example, it is unclear how the methods would scale to larger, more complex problem instances, or how sensitive the solutions are to the specific probability distributions assumed for the "trembling hand" errors.
Additionally, the paper does not compare or contextualize the proposed approaches within the broader literature on planning under uncertainty or temporally extended goal reasoning. Situating the work more firmly within this related research could help readers better understand the novelty and significance of the contributions.
Conclusion
This paper introduces an important problem, the "trembling-hand" problem, in the context of planning for temporally extended goals expressed in LTLf. The authors propose solution techniques based on Markov Decision Processes, both for deterministic and nondeterministic environments, and demonstrate the effectiveness of their approaches through experiments.
The work highlights the practical challenges of reliable goal achievement in the face of potential action execution errors, which is a crucial consideration for many real-world autonomous systems and robotics applications. While the paper presents a solid technical foundation, further research is needed to fully understand the limitations and scaling potential of the proposed methods, as well as to contextualize the contributions within the broader literature on planning under uncertainty and temporal logic reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
The Trembling-Hand Problem for LTLf Planning
Pian Yu, Shufang Zhu, Giuseppe De Giacomo, Marta Kwiatkowska, Moshe Vardi
Consider an agent acting to achieve its temporal goal, but with a trembling hand. In this case, the agent may mistakenly instruct, with a certain (typically small) probability, actions that are not intended due to faults or imprecision in its action selection mechanism, thereby leading to possible goal failure. We study the trembling-hand problem in the context of reasoning about actions and planning for temporally extended goals expressed in Linear Temporal Logic on finite traces (LTLf), where we want to synthesize a strategy (aka plan) that maximizes the probability of satisfying the LTLf goal in spite of the trembling hand. We consider both deterministic and nondeterministic (adversarial) domains. We propose solution techniques for both cases by relying respectively on Markov Decision Processes and on Markov Decision Processes with Set-valued Transitions with LTLf objectives, where the set-valued probabilistic transitions capture both the nondeterminism from the environment and the possible action instruction errors from the agent. We formally show the correctness of our solution techniques and demonstrate their effectiveness experimentally through a proof-of-concept implementation.
Read more4/26/2024
✨
0
Prioritize Team Actions: Multi-Agent Temporal Logic Task Planning with Ordering Constraints
Bowen Ye, Jianing Zhao, Shaoyuan Li, Xiang Yin
In this paper, we investigate the problem of linear temporal logic (LTL) path planning for multi-agent systems, introducing the new concept of emph{ordering constraints}. Specifically, we consider a generic objective function that is defined for the path of each individual agent. The primary objective is to find a global plan for the team of agents, ensuring they collectively meet the specified LTL requirements. Simultaneously, we aim to maintain a pre-determined order in the values of the objective function for each agent, which we refer to as the ordering constraints. This new requirement stems from scenarios like security-aware planning, where relative orders outweigh absolute values in importance. We present an efficient algorithm to solve this problem, supported by proofs of correctness that demonstrate the optimality of our solution. Additionally, we provide a case study in security-aware path planning to illustrate the practicality and effectiveness of our proposed approach.
Read more4/9/2024
⚙️
0
Non-Deterministic Planning for Hyperproperty Verification
Raven Beutner, Bernd Finkbeiner
Non-deterministic planning aims to find a policy that achieves a given objective in an environment where actions have uncertain effects, and the agent - potentially - only observes parts of the current state. Hyperproperties are properties that relate multiple paths of a system and can, e.g., capture security and information-flow policies. Popular logics for expressing temporal hyperproperties - such as HyperLTL - extend LTL by offering selective quantification over executions of a system. In this paper, we show that planning offers a powerful intermediate language for the automated verification of hyperproperties. Concretely, we present an algorithm that, given a HyperLTL verification problem, constructs a non-deterministic multi-agent planning instance (in the form of a QDec-POMDP) that, when admitting a plan, implies the satisfaction of the verification problem. We show that for large fragments of HyperLTL, the resulting planning instance corresponds to a classical, FOND, or POND planning problem. We implement our encoding in a prototype verification tool and report on encouraging experimental results.
Read more5/24/2024
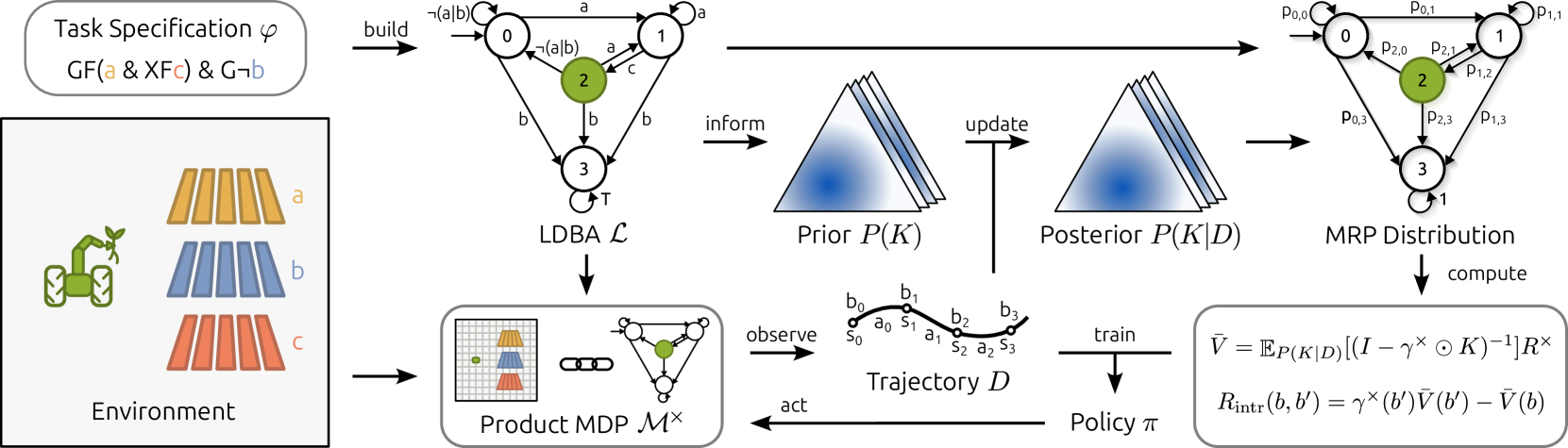
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024