Truth is Universal: Robust Detection of Lies in LLMs

0

Sign in to get full access
Overview
- This paper explores the development of robust models to detect lies in large language models (LLMs).
- The researchers created datasets with true and false statements to train and evaluate models for detecting deception.
- They investigated supervised learning techniques to train models that can reliably identify lies in LLM outputs.
- The paper also explores the evolution of LLMs' latent representations and their ability to help humans verify truthfulness.
Plain English Explanation
The researchers in this paper wanted to create models that could reliably detect when large language models (LLMs) are generating false or deceptive information. To do this, they built datasets with both true and false statements, which they used to train and test their detection models.
The key insight is that there may be underlying patterns or "signatures" in the way LLMs generate truthful versus deceptive outputs, and that these signatures can be learned by supervised machine learning models. By training on the true/false datasets, the researchers hoped to develop models that could accurately identify lies in LLM outputs, even if the lies were subtle or convincing.
This research is important because as LLMs become more advanced and widely used, there is a growing risk of them being used to generate misinformation or propaganda. Developing reliable lie detection systems could help mitigate this risk and ensure that LLM-generated content is trustworthy. Additionally, the researchers explored how LLMs' internal representations evolve over time and how they can be leveraged to help humans verify the truthfulness of statements.
Technical Explanation
The researchers in this paper developed datasets with true and false statements to train and evaluate models for detecting deception in LLM outputs. They investigated supervised learning techniques to train models that could reliably identify lies, even in subtle or convincing cases.
The key technical insight is that there may be underlying "truthfulness signatures" in the way LLMs generate outputs, and that these signatures can be learned by machine learning models. By training on the true/false datasets, the researchers aimed to develop models that could accurately distinguish truthful from deceptive LLM outputs.
The paper also explored the evolution of LLMs' latent representations over time and how these representations can be used to help humans verify the truthfulness of statements.
Critical Analysis
The researchers acknowledge that their work is an initial exploration of this problem, and there are still many challenges and limitations to address. For example, the true/false datasets they created may not capture the full complexity and nuance of real-world deception, and the supervised learning techniques they used may not generalize well to new domains or evolving LLM capabilities.
Additionally, the paper does not address potential biases or other ethical concerns that may arise from deploying such lie detection systems, such as the risk of unfairly targeting certain groups or the potential for abuse by bad actors. Further research and careful consideration of these issues will be necessary as this technology develops.
That said, the researchers' overall approach of using supervised learning to detect deception in LLM outputs is a promising avenue for further exploration. As LLMs become more ubiquitous and influential, developing robust and reliable lie detection systems will be crucial for maintaining trust in AI-generated information.
Conclusion
This paper presents an initial exploration of using supervised learning to detect lies in LLM outputs. By developing datasets with true and false statements and training models to recognize underlying "truthfulness signatures," the researchers have shown the potential for building robust lie detection systems that can help ensure the trustworthiness of LLM-generated content.
While further research is needed to address the limitations and challenges identified in the paper, this work represents an important step towards the goal of honest and helpful large language models. As LLMs continue to advance and become more widely used, the ability to reliably detect and mitigate the spread of misinformation will be crucial for maintaining public trust in AI and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Truth is Universal: Robust Detection of Lies in LLMs
Lennart Burger, Fred A. Hamprecht, Boaz Nadler
Large Language Models (LLMs) have revolutionised natural language processing, exhibiting impressive human-like capabilities. In particular, LLMs are capable of lying, knowingly outputting false statements. Hence, it is of interest and importance to develop methods to detect when LLMs lie. Indeed, several authors trained classifiers to detect LLM lies based on their internal model activations. However, other researchers showed that these classifiers may fail to generalise, for example to negated statements. In this work, we aim to develop a robust method to detect when an LLM is lying. To this end, we make the following key contributions: (i) We demonstrate the existence of a two-dimensional subspace, along which the activation vectors of true and false statements can be separated. Notably, this finding is universal and holds for various LLMs, including Gemma-7B, LLaMA2-13B and LLaMA3-8B. Our analysis explains the generalisation failures observed in previous studies and sets the stage for more robust lie detection; (ii) Building upon (i), we construct an accurate LLM lie detector. Empirically, our proposed classifier achieves state-of-the-art performance, distinguishing simple true and false statements with 94% accuracy and detecting more complex real-world lies with 95% accuracy.
Read more7/19/2024
0
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
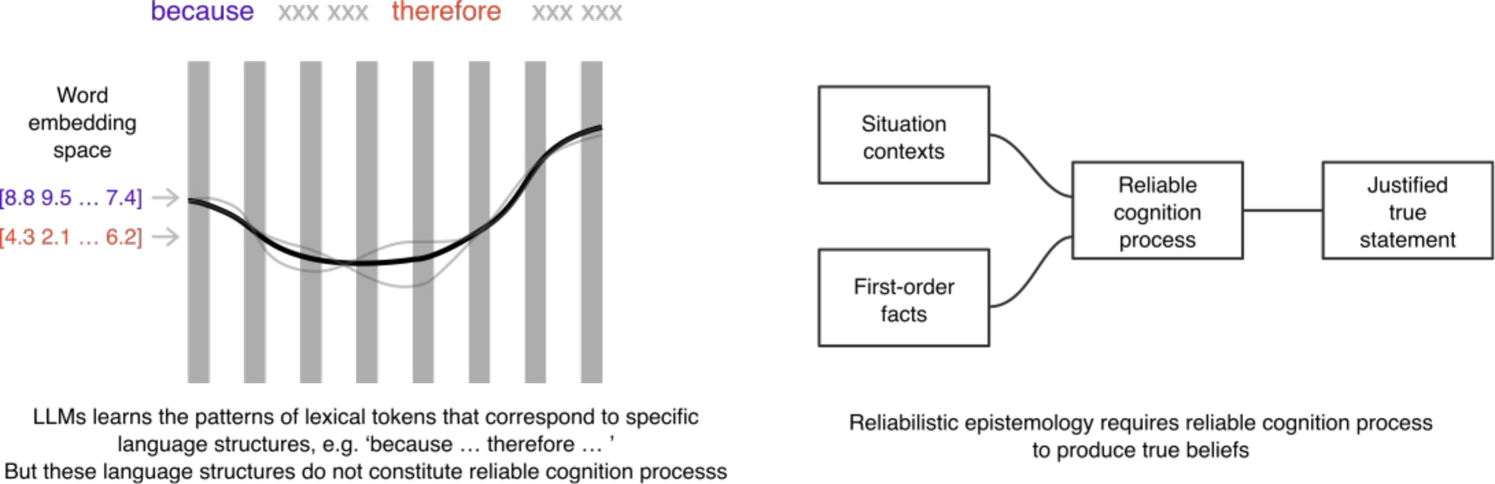
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024
💬
0
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets
Samuel Marks, Max Tegmark
Large Language Models (LLMs) have impressive capabilities, but are prone to outputting falsehoods. Recent work has developed techniques for inferring whether a LLM is telling the truth by training probes on the LLM's internal activations. However, this line of work is controversial, with some authors pointing out failures of these probes to generalize in basic ways, among other conceptual issues. In this work, we use high-quality datasets of simple true/false statements to study in detail the structure of LLM representations of truth, drawing on three lines of evidence: 1. Visualizations of LLM true/false statement representations, which reveal clear linear structure. 2. Transfer experiments in which probes trained on one dataset generalize to different datasets. 3. Causal evidence obtained by surgically intervening in a LLM's forward pass, causing it to treat false statements as true and vice versa. Overall, we present evidence that at sufficient scale, LLMs linearly represent the truth or falsehood of factual statements. We also show that simple difference-in-mean probes generalize as well as other probing techniques while identifying directions which are more causally implicated in model outputs.
Read more8/20/2024

0
On the Universal Truthfulness Hyperplane Inside LLMs
Junteng Liu, Shiqi Chen, Yu Cheng, Junxian He
While large language models (LLMs) have demonstrated remarkable abilities across various fields, hallucination remains a significant challenge. Recent studies have explored hallucinations through the lens of internal representations, proposing mechanisms to decipher LLMs' adherence to facts. However, these approaches often fail to generalize to out-of-distribution data, leading to concerns about whether internal representation patterns reflect fundamental factual awareness, or only overfit spurious correlations on the specific datasets. In this work, we investigate whether a universal truthfulness hyperplane that distinguishes the model's factually correct and incorrect outputs exists within the model. To this end, we scale up the number of training datasets and conduct an extensive evaluation -- we train the truthfulness hyperplane on a diverse collection of over 40 datasets and examine its cross-task, cross-domain, and in-domain generalization. Our results indicate that increasing the diversity of the training datasets significantly enhances the performance in all scenarios, while the volume of data samples plays a less critical role. This finding supports the optimistic hypothesis that a universal truthfulness hyperplane may indeed exist within the model, offering promising directions for future research.
Read more7/12/2024