Unraveling Code Clone Dynamics in Deep Learning Frameworks

0
Sign in to get full access
Overview
- This paper explores the dynamics of code clones in deep learning frameworks, which are identical or highly similar code segments that can have significant implications for software development and maintenance.
- The researchers conducted a large-scale empirical study to understand the prevalence, evolution, and impact of code clones in popular deep learning libraries like TensorFlow, PyTorch, and Keras.
- The findings provide insights into how code clones emerge, spread, and potentially introduce technical debt and maintenance challenges in complex, rapidly evolving deep learning codebases.
Plain English Explanation
When developers write code, they sometimes copy and paste similar chunks of code, known as "code clones." While this can save time in the short term, code clones can lead to long-term problems if they are not managed properly.
This paper looks at code clones in popular deep learning frameworks, which are software libraries used to build and train artificial intelligence models. The researchers examined how these clones arise, change over time, and impact the overall health and maintainability of the codebase.
They found that code clones are quite common in deep learning frameworks, and that they can spread and evolve in complex ways as the libraries are updated and expanded. This can create technical debt, where the original code becomes harder to understand and modify over time.
The insights from this research can help developers better manage and mitigate the risks of code clones as they work on building and maintaining these powerful AI tools. By understanding the dynamics of code clones, they can make more informed decisions about when to refactor or consolidate similar code segments, ultimately leading to cleaner, more maintainable deep learning codebases.
Technical Explanation
The researchers conducted a large-scale empirical study to understand the prevalence, evolution, and impact of code clones in popular deep learning libraries like TensorFlow, PyTorch, and Keras.
They used advanced clone detection techniques to identify similar code segments across multiple versions of these frameworks, tracking how the clones changed over time. The researchers also analyzed the structural properties of the clones, their distribution across the codebase, and their relationship to technical debt and maintenance challenges.
The findings reveal that code clones are quite common in deep learning frameworks, with a significant portion of the codebases consisting of duplicated or near-duplicated code. These clones tend to evolve and spread as the libraries are updated, with new clones being introduced and existing ones being modified or removed.
The researchers also found that code clones are often associated with increased technical debt, as the duplicated code becomes harder to understand and maintain over time. This can slow down development, increase the risk of bugs, and make it more difficult to implement changes or upgrades to the deep learning frameworks.
Critical Analysis
The paper provides a comprehensive and well-designed study on the dynamics of code clones in deep learning frameworks. The researchers used robust, state-of-the-art clone detection techniques and thoroughly analyzed the prevalence, evolution, and impact of these clones.
One potential limitation of the study is that it focuses solely on three popular deep learning libraries (TensorFlow, PyTorch, and Keras). While these are among the most widely used frameworks, it would be valuable to extend the analysis to a broader range of deep learning codebases to see if the observed patterns and trends hold true across the field.
Additionally, the paper does not explore in-depth the specific factors or development practices that may contribute to the creation and spread of code clones in deep learning frameworks. Further research into the underlying causes and potential mitigations could provide more actionable insights for developers and maintainers.
Overall, this study offers a significant contribution to our understanding of the challenges posed by code clones in complex, rapidly evolving deep learning codebases. The findings highlight the importance of proactively managing and addressing code duplication to ensure the long-term maintainability and sustainability of these critical AI tools.
Conclusion
This paper provides valuable insights into the prevalence, evolution, and impact of code clones in popular deep learning frameworks. The researchers' comprehensive analysis reveals that code duplication is a pervasive issue in these rapidly evolving codebases, with significant implications for technical debt and maintenance challenges.
The findings underscore the need for deep learning developers and framework maintainers to be mindful of code clones and to actively manage them throughout the software development lifecycle. By understanding the dynamics of code clones, they can make more informed decisions about refactoring, consolidation, and other strategies to improve the long-term health and maintainability of these critical AI tools.
Overall, this research contributes to a growing body of work on software engineering challenges in the context of machine learning and deep learning, highlighting the importance of holistic, cross-disciplinary approaches to building robust and sustainable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unraveling Code Clone Dynamics in Deep Learning Frameworks
Maram Assi, Safwat Hassan, Ying Zou
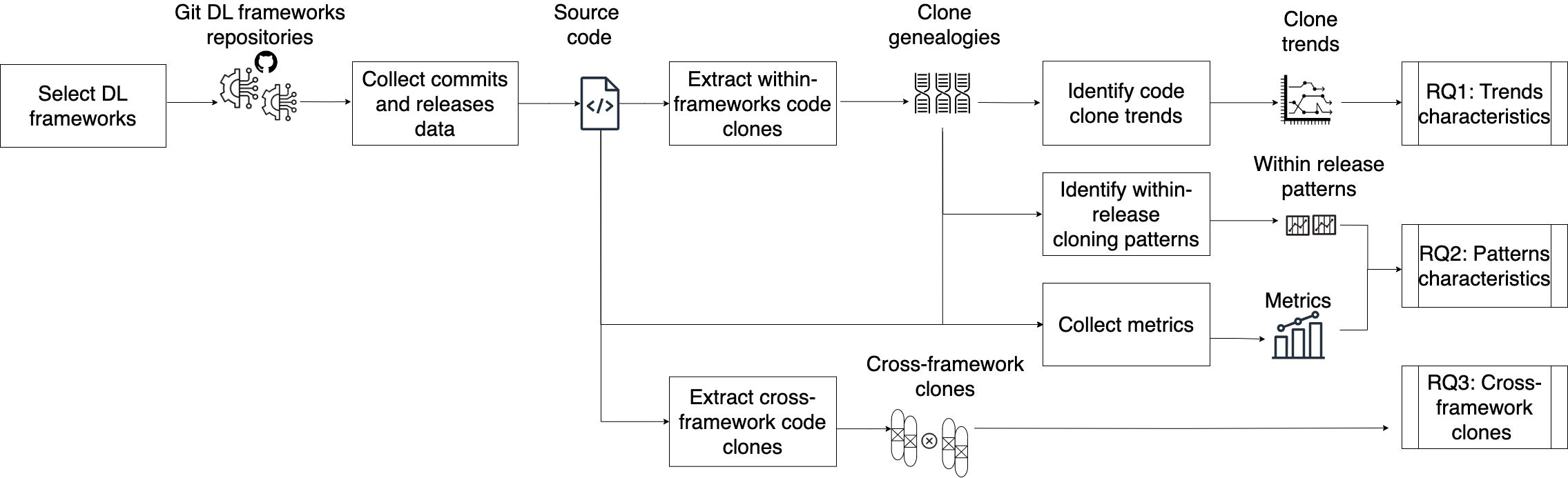
Deep Learning (DL) frameworks play a critical role in advancing artificial intelligence, and their rapid growth underscores the need for a comprehensive understanding of software quality and maintainability. DL frameworks, like other systems, are prone to code clones. Code clones refer to identical or highly similar source code fragments within the same project or even across different projects. Code cloning can have positive and negative implications for software development, influencing maintenance, readability, and bug propagation. In this paper, we aim to address the knowledge gap concerning the evolutionary dimension of code clones in DL frameworks and the extent of code reuse across these frameworks. We empirically analyze code clones in nine popular DL frameworks, i.e., TensorFlow, Paddle, PyTorch, Aesara, Ray, MXNet, Keras, Jax and BentoML, to investigate (1) the characteristics of the long-term code cloning evolution over releases in each framework, (2) the short-term, i.e., within-release, code cloning patterns and their influence on the long-term trends, and (3) the file-level code clones within the DL frameworks. Our findings reveal that DL frameworks adopt four distinct cloning trends and that these trends present some common and distinct characteristics. For instance, bug-fixing activities persistently happen in clones irrespective of the clone evolutionary trend but occur more in the Serpentine trend. Moreover, the within release level investigation demonstrates that short-term code cloning practices impact long-term cloning trends. The cross-framework code clone investigation reveals the presence of functional and architectural adaptation file-level cross-framework code clones across the nine studied frameworks. We provide insights that foster robust clone practices and collaborative maintenance in the development of DL frameworks.
Read more4/29/2024

0
DeepCodeProbe: Towards Understanding What Models Trained on Code Learn
Vahid Majdinasab, Amin Nikanjam, Foutse Khomh
Machine learning models trained on code and related artifacts offer valuable support for software maintenance but suffer from interpretability issues due to their complex internal variables. These concerns are particularly significant in safety-critical applications where the models' decision-making processes must be reliable. The specific features and representations learned by these models remain unclear, adding to the hesitancy in adopting them widely. To address these challenges, we introduce DeepCodeProbe, a probing approach that examines the syntax and representation learning abilities of ML models designed for software maintenance tasks. Our study applies DeepCodeProbe to state-of-the-art models for code clone detection, code summarization, and comment generation. Findings reveal that while small models capture abstract syntactic representations, their ability to fully grasp programming language syntax is limited. Increasing model capacity improves syntax learning but introduces trade-offs such as increased training time and overfitting. DeepCodeProbe also identifies specific code patterns the models learn from their training data. Additionally, we provide best practices for training models on code to enhance performance and interpretability, supported by an open-source replication package for broader application of DeepCodeProbe in interpreting other code-related models.
Read more7/15/2024
🔎
0
Advanced Detection of Source Code Clones via an Ensemble of Unsupervised Similarity Measures
Jorge Martinez-Gil
The capability of accurately determining code similarity is crucial in many tasks related to software development. For example, it might be essential to identify code duplicates for performing software maintenance. This research introduces a novel ensemble learning approach for code similarity assessment, combining the strengths of multiple unsupervised similarity measures. The key idea is that the strengths of a diverse set of similarity measures can complement each other and mitigate individual weaknesses, leading to improved performance. Preliminary results show that while Transformers-based CodeBERT and its variant GraphCodeBERT are undoubtedly the best option in the presence of abundant training data, in the case of specific small datasets (up to 500 samples), our ensemble achieves similar results, without prejudice to the interpretability of the resulting solution, and with a much lower associated carbon footprint due to training. The source code of this novel approach can be downloaded from https://github.com/jorge-martinez-gil/ensemble-codesim.
Read more5/6/2024

0
An Exploratory Study on Automatic Identification of Assumptions in the Development of Deep Learning Frameworks
Chen Yang, Peng Liang, Zinan Ma
Stakeholders constantly make assumptions in the development of deep learning (DL) frameworks. These assumptions are related to various types of software artifacts (e.g., requirements, design decisions, and technical debt) and can turn out to be invalid, leading to system failures. Existing approaches and tools for assumption management usually depend on manual identification of assumptions. However, assumptions are scattered in various sources (e.g., code comments, commits, and issues) of DL framework development, and manually identifying assumptions has high costs (e.g., time and resources). The objective of the study is to evaluate different classification models for the purpose of identification with respect to assumptions from the point of view of developers and users in the context of DL framework projects (i.e., issues, pull requests, and commits) on GitHub. We constructed a new and largest dataset (i.e., AssuEval) of assumptions collected from the TensorFlow and Keras repositories on GitHub; explored the performance of seven non-transformers based models (e.g., Support Vector Machine, Classification and Regression Trees), the ALBERT model, and three large language models (i.e., ChatGPT, Claude, and Gemini) for identifying assumptions on the AssuEval dataset. The study results show that ALBERT achieves the best performance (f1-score: 0.9584) for identifying assumptions on the AssuEval dataset, which is much better than the other models (the 2nd best f1-score is 0.8858, achieved by the Claude 3.5 Sonnet model). Though ChatGPT, Claude, and Gemini are popular large language models, we do not recommend using them to identify assumptions in DL framework development because of their low performance. This study provides researchers with the largest dataset of assumptions for further research and helps practitioners better understand assumptions and how to manage them in their projects.
Read more7/24/2024