Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models

0

Sign in to get full access
Overview
- This paper explores the impact of order and token sensitivity in large language models, which are AI systems trained on vast amounts of text data to generate human-like language.
- The researchers investigate how the order of input tokens and the choice of specific tokens can influence the model's predictions, revealing potential selection biases.
- By studying these biases, the researchers aim to gain a better understanding of how large language models work and how they can be improved.
Plain English Explanation
Large language models, like the ones used in chatbots and virtual assistants, are trained on huge datasets of text from the internet. This allows them to generate human-like language, but it also means they can pick up on subtle biases in the data.
This paper looks at two types of biases in these models:
By studying these biases, the researchers hope to understand how large language models work under the hood and find ways to make them more reliable and less biased. This could lead to better chatbots, writing assistants, and other language-based AI tools that are more accurate and fair.
Technical Explanation
The researchers conducted a series of experiments to investigate order and token sensitivity in large language models. They used models like GPT-3, which are trained on massive amounts of online text, and tested how the models' predictions changed when the order of words or the specific words used were altered.
For order sensitivity, they found that swapping the order of words in a sentence could significantly change the model's predictions, even if the overall meaning remained the same. This suggests the models are heavily dependent on the exact sequence of words.
Similarly, for token sensitivity, the researchers found that using synonymous words or paraphrasing a sentence led to different model outputs. This indicates the models are attuned to specific linguistic cues beyond just the semantic content.
These biases could lead to inconsistent or unreliable behavior in real-world applications of large language models. The researchers propose further studying these biases and developing techniques to mitigate position bias in large language models or compensate for selection biases under cognitive load.
Critical Analysis
The paper provides a thorough and thoughtful exploration of order and token sensitivity in large language models. The experimental approach is well-designed and the findings are clearly presented.
However, the paper does not delve deeply into the potential causes of these biases. It is possible that the models are overly reliant on surface-level linguistic cues due to limitations in their training data or architecture. Further research is needed to understand the underlying mechanisms driving these biases.
Additionally, the paper does not address the potential real-world implications of these biases, such as how they might impact the reliability of language-based AI systems in critical applications. More work is needed to quantify and mitigate label biases in large language models.
Overall, this paper makes an important contribution to our understanding of large language models, but there is still much to be explored in terms of strategic data ordering to enhance these models and instruction tuning to improve their performance.
Conclusion
This paper sheds light on the order and token sensitivity of large language models, revealing potential selection biases that could undermine the reliability and fairness of these AI systems. By studying these biases, the researchers aim to improve our fundamental understanding of how large language models work and pave the way for more robust and trustworthy language-based AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models
Sheng-Lun Wei, Cheng-Kuang Wu, Hen-Hsen Huang, Hsin-Hsi Chen
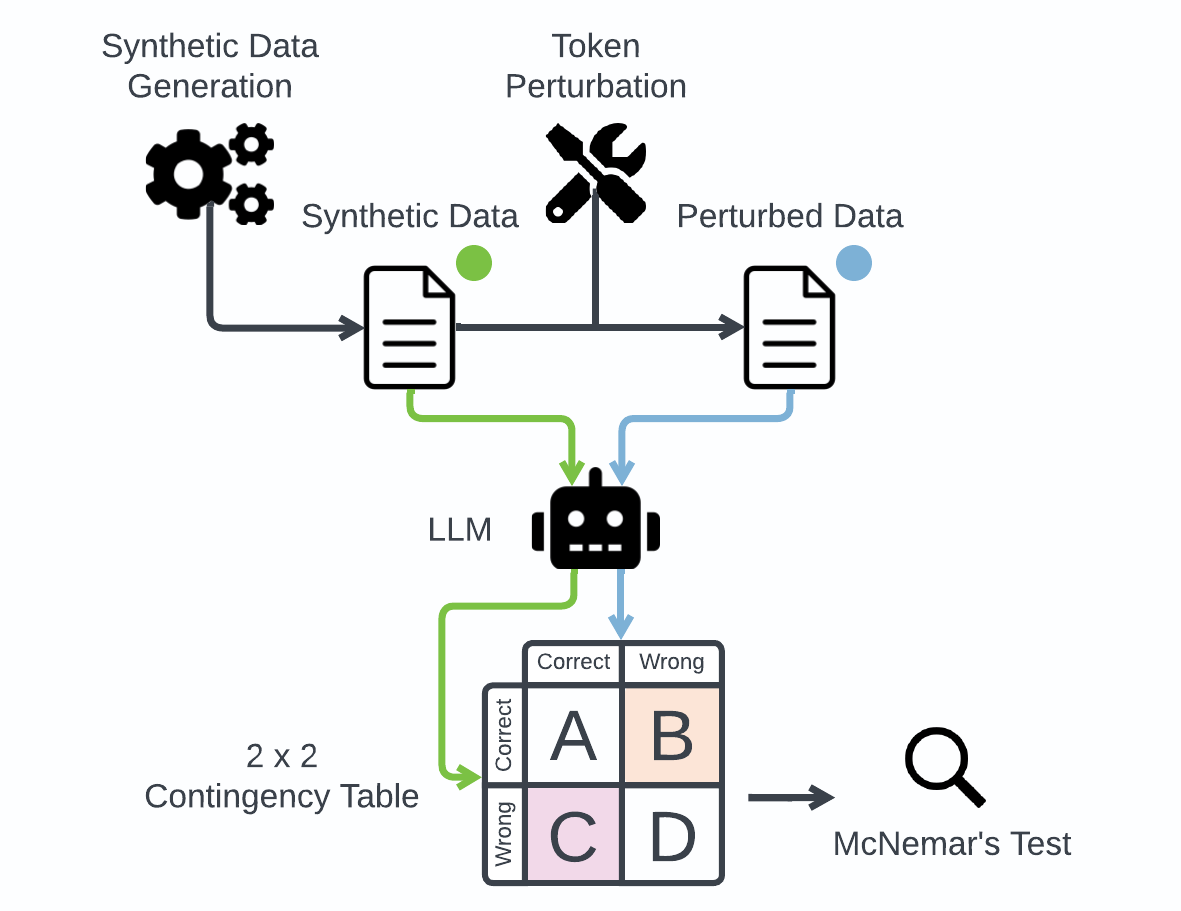
In this paper, we investigate the phenomena of selection biases in Large Language Models (LLMs), focusing on problems where models are tasked with choosing the optimal option from an ordered sequence. We delve into biases related to option order and token usage, which significantly impact LLMs' decision-making processes. We also quantify the impact of these biases through an extensive empirical analysis across multiple models and tasks. Furthermore, we propose mitigation strategies to enhance model performance. Our key contributions are threefold: 1) Precisely quantifying the influence of option order and token on LLMs, 2) Developing strategies to mitigate the impact of token and order sensitivity to enhance robustness, and 3) Offering a detailed analysis of sensitivity across models and tasks, which informs the creation of more stable and reliable LLM applications for selection problems.
Read more6/6/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
0
A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo J. Taylor, Dan Roth
This study introduces a hypothesis-testing framework to assess whether large language models (LLMs) possess genuine reasoning abilities or primarily depend on token bias. We go beyond evaluating LLMs on accuracy; rather, we aim to investigate their token bias in solving logical reasoning tasks. Specifically, we develop carefully controlled synthetic datasets, featuring conjunction fallacy and syllogistic problems. Our framework outlines a list of hypotheses where token biases are readily identifiable, with all null hypotheses assuming genuine reasoning capabilities of LLMs. The findings in this study suggest, with statistical guarantee, that most LLMs still struggle with logical reasoning. While they may perform well on classic problems, their success largely depends on recognizing superficial patterns with strong token bias, thereby raising concerns about their actual reasoning and generalization abilities.
Read more6/18/2024

1
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
Norah Alzahrani, Hisham Abdullah Alyahya, Yazeed Alnumay, Sultan Alrashed, Shaykhah Alsubaie, Yusef Almushaykeh, Faisal Mirza, Nouf Alotaibi, Nora Altwairesh, Areeb Alowisheq, M Saiful Bari, Haidar Khan
Large Language Model (LLM) leaderboards based on benchmark rankings are regularly used to guide practitioners in model selection. Often, the published leaderboard rankings are taken at face value - we show this is a (potentially costly) mistake. Under existing leaderboards, the relative performance of LLMs is highly sensitive to (often minute) details. We show that for popular multiple-choice question benchmarks (e.g., MMLU), minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions. We explain this phenomenon by conducting systematic experiments over three broad categories of benchmark perturbations and identifying the sources of this behavior. Our analysis results in several best-practice recommendations, including the advantage of a hybrid scoring method for answer selection. Our study highlights the dangers of relying on simple benchmark evaluations and charts the path for more robust evaluation schemes on the existing benchmarks. The code for this paper is available at https://github.com/National-Center-for-AI-Saudi-Arabia/lm-evaluation-harness.
Read more7/4/2024