VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
2404.16365
0
0
🌐
Abstract
Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new benchmark called VISLA (Variance and Invariance to Semantic and Lexical Alterations) to evaluate the semantic and lexical understanding of language models.
- VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, which can be used to assess both vision-language models (VLMs) and unimodal language models (ULMs).
- Evaluations of 34 VLMs and 20 ULMs reveal surprising difficulties in distinguishing between lexical and semantic variations, and that the spatial semantics encoded by language models are highly sensitive to lexical information.
- The text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders.
Plain English Explanation
Modern AI language models have made remarkable progress, but they still struggle with certain important details related to the meaning and structure of language. This paper introduces a new test called VISLA that is designed to evaluate how well these language models understand the semantic (meaning-related) and lexical (word-related) aspects of language.
The VISLA test presents sets of three sentences, each associated with an image. The task is to determine whether the sentences are semantically equivalent, semantically different, or just have different words but the same meaning. This test can be used to assess both language models that work with both text and images (vision-language models), as well as models that only work with text (unimodal language models).
When the researchers tested 34 vision-language models and 20 unimodal language models on the VISLA test, they found some surprising results. The models had a hard time distinguishing between changes in the meaning of sentences versus just changes in the words used. The models also seemed to be very sensitive to the specific words used when it came to understanding the spatial relationships and meanings encoded in the language.
Interestingly, the text encoding parts of the vision-language models were more sensitive to these semantic and lexical variations than the text-only language models. This suggests that the way these models learn from both text and images may give them a more nuanced understanding of language, but also makes them more easily confused by certain types of language changes.
Technical Explanation
The paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, which is designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image. This task can be used to assess both vision-language models (VLMs) and unimodal language models (ULMs).
The evaluation involved 34 VLMs and 20 ULMs, and revealed surprising difficulties in distinguishing between lexical and semantic variations. The spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Interestingly, the text encoders of VLMs demonstrated greater sensitivity to semantic and lexical variations than unimodal text encoders.
The paper makes several contributions, including:
- Unifying image-to-text and text-to-text retrieval tasks
- Providing an off-the-shelf evaluation without fine-tuning
- Assessing language models' semantic (in)variance in the presence of lexical alterations
The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. The VALOR framework could be used to further explore the semantics of language models' latent spaces.
Critical Analysis
The paper provides a thorough and well-designed evaluation of language models' understanding of semantic and lexical variations. However, there are a few potential limitations and areas for further research:
-
Scope of Evaluation: The evaluation is limited to a specific 3-way semantic (in)equivalence task. While this provides valuable insights, it may not capture the full breadth of language understanding required for real-world applications.
-
Generalization: The paper does not explore how the observed sensitivities to lexical information might generalize to other language understanding tasks or domains. Further research is needed to understand the broader implications of these findings.
-
Interpretation of Results: The reasons behind the observed differences in sensitivity between VLMs and ULMs are not fully explored. Additional analysis or experiments could help unpack the underlying mechanisms driving these differences.
-
Practical Implications: While the paper highlights important limitations in language models' understanding of semantic and lexical nuances, it does not provide clear guidance on how to address these issues in practice. Exploring potential mitigation strategies or architectural improvements could be a valuable next step.
Overall, the VISLA benchmark and the insights provided in this paper represent an important contribution to the ongoing efforts to better understand the capabilities and limitations of language models. As the field continues to advance, it will be crucial to maintain a critical and nuanced perspective on the strengths and weaknesses of these powerful AI systems.
Conclusion
This paper introduces the VISLA benchmark, a novel evaluation tool designed to assess the semantic and lexical understanding of language models. The results of testing 34 VLMs and 20 ULMs on VISLA reveal surprising difficulties in distinguishing between lexical and semantic variations, as well as a high sensitivity of spatial semantics to lexical information. Notably, the text encoders of VLMs demonstrate greater sensitivity to these nuances compared to unimodal text encoders.
The VISLA benchmark represents an important contribution to the ongoing efforts to better understand the capabilities and limitations of language models. By shedding light on areas where these models struggle with semantic and lexical complexities, the research highlights the need for continued advancements in language understanding. Further exploration of the underlying mechanisms and potential mitigation strategies could lead to significant improvements in the robustness and versatility of language AI systems, with far-reaching implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Simon Ging, Mar'ia A. Bravo, Thomas Brox
0
0
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
5/7/2024
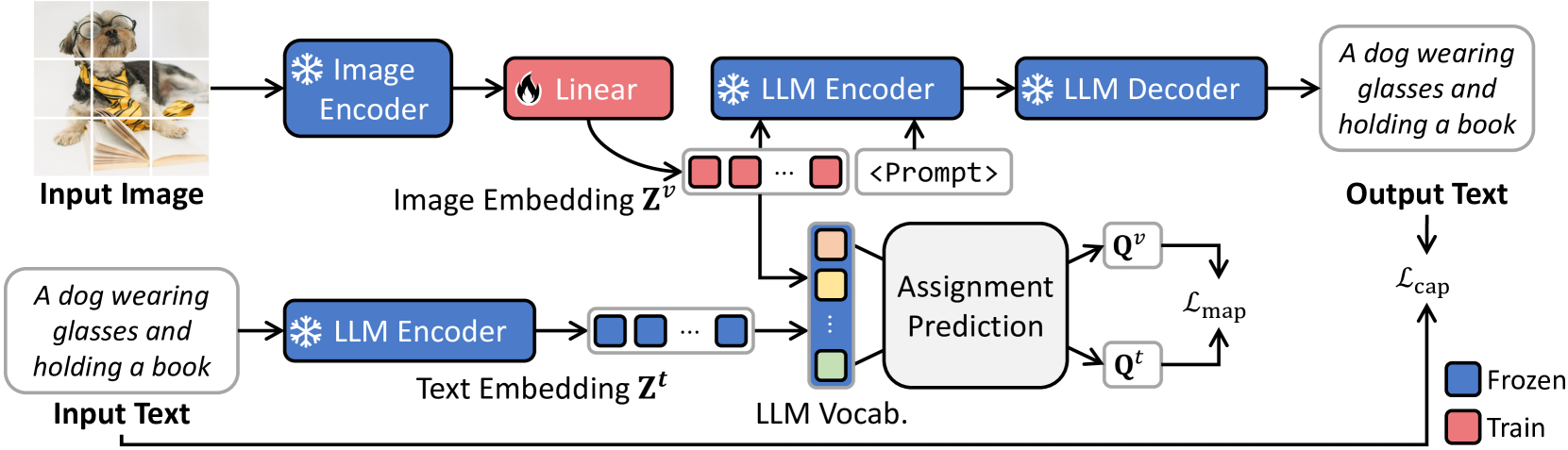
Bridging Vision and Language Spaces with Assignment Prediction
Jungin Park, Jiyoung Lee, Kwanghoon Sohn
0
0
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
4/16/2024
🤔
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
0
0
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
4/29/2024
⚙️
Revisiting a Pain in the Neck: Semantic Phrase Processing Benchmark for Language Models
Yang Liu, Melissa Xiaohui Qin, Hongming Li, Chao Huang
0
0
We introduce LexBench, a comprehensive evaluation suite enabled to test language models (LMs) on ten semantic phrase processing tasks. Unlike prior studies, it is the first work to propose a framework from the comparative perspective to model the general semantic phrase (i.e., lexical collocation) and three fine-grained semantic phrases, including idiomatic expression, noun compound, and verbal construction. Thanks to ourbenchmark, we assess the performance of 15 LMs across model architectures and parameter scales in classification, extraction, and interpretation tasks. Through the experiments, we first validate the scaling law and find that, as expected, large models excel better than the smaller ones in most tasks. Second, we investigate further through the scaling semantic relation categorization and find that few-shot LMs still lag behind vanilla fine-tuned models in the task. Third, through human evaluation, we find that the performance of strong models is comparable to the human level regarding semantic phrase processing. Our benchmarking findings can serve future research aiming to improve the generic capability of LMs on semantic phrase comprehension. Our source code and data are available at https://github.com/jacklanda/LexBench
5/7/2024