Visual Knowledge in the Big Model Era: Retrospect and Prospect
2404.04308
0
0
📈
Abstract
Visual knowledge is a new form of knowledge representation that can encapsulate visual concepts and their relations in a succinct, comprehensive, and interpretable manner, with a deep root in cognitive psychology. As the knowledge about the visual world has been identified as an indispensable component of human cognition and intelligence, visual knowledge is poised to have a pivotal role in establishing machine intelligence. With the recent advance of Artificial Intelligence (AI) techniques, large AI models (or foundation models) have emerged as a potent tool capable of extracting versatile patterns from broad data as implicit knowledge, and abstracting them into an outrageous amount of numeric parameters. To pave the way for creating visual knowledge empowered AI machines in this coming wave, we present a timely review that investigates the origins and development of visual knowledge in the pre-big model era, and accentuates the opportunities and unique role of visual knowledge in the big model era.
Create account to get full access
Overview
- Visual knowledge is a new way of representing knowledge about the visual world, which can capture visual concepts and their relationships in a concise, comprehensive, and interpretable manner.
- It has its roots in cognitive psychology and is seen as an essential component of human cognition and intelligence.
- The recent advancements in Artificial Intelligence (AI) have led to the emergence of large AI models (or foundation models) that can extract patterns and abstract them into a vast number of numeric parameters as implicit knowledge.
- This review investigates the origins and development of visual knowledge in the pre-big model era, and highlights the opportunities and unique role of visual knowledge in the big model era.
Plain English Explanation
Visual knowledge is a new way of representing information about the visual world. It can capture the different visual concepts, like objects, scenes, and their relationships, in a clear and compact way. This is important because our ability to understand and reason about the visual world is a crucial part of how we think and learn as humans.
As AI systems have become more advanced, they have developed the ability to extract and store a lot of implicit, or hidden, knowledge from large datasets. These large AI models can recognize patterns and create a huge number of numeric parameters to represent what they've learned. Visual knowledge could play a key role in helping these AI systems better understand and reason about the visual world, in the same way that humans do.
This review looks at how visual knowledge developed before the era of these large AI models, and explores the unique opportunities and importance of visual knowledge as these powerful AI systems continue to evolve. It examines how visual knowledge can help AI systems learn and reason about visual concepts and their relationships, which could be crucial for building AI that can truly understand and interact with the world like humans can.
Technical Explanation
The paper begins by introducing the concept of visual knowledge as a new form of knowledge representation that can capture visual concepts and their relationships in a concise, comprehensive, and interpretable manner. It emphasizes that the ability to understand the visual world is a fundamental part of human cognition and intelligence, and therefore, visual knowledge is poised to play a pivotal role in establishing machine intelligence.
The paper then discusses the recent advancements in Artificial Intelligence (AI) techniques, particularly the emergence of large AI models (or foundation models). These models have the capability of extracting versatile patterns from broad data as implicit knowledge and representing them through a vast number of numeric parameters. The paper suggests that visual knowledge could be instrumental in helping these large AI models better understand and reason about the visual world, similar to how humans do.
To provide context, the paper investigates the origins and development of visual knowledge in the pre-big model era. It highlights the opportunities and unique role of visual knowledge in the current era of large AI models, where visual knowledge could play a key role in eliciting spatial reasoning and cognition from these powerful systems.
Critical Analysis
The paper presents a compelling case for the importance of visual knowledge in the development of machine intelligence. It rightly points out that the ability to understand the visual world is a fundamental aspect of human cognition and that incorporating visual knowledge could be crucial for building AI systems that can interact with and reason about the world in a more human-like manner.
However, the paper does not delve into the potential challenges and limitations of incorporating visual knowledge into large AI models. For example, it does not address the difficulties in extracting and representing visual knowledge in a way that is both comprehensive and interpretable. There are also concerns about the potential for knowledge collapse, where the vast amount of numeric parameters in large AI models could lead to the loss of meaningful and interpretable knowledge.
Additionally, the paper could have explored the ethical implications of incorporating visual knowledge into AI systems, such as the potential for biases and the need for careful curation and validation of the visual knowledge used.
Overall, the paper provides a solid foundation for understanding the importance of visual knowledge in the development of machine intelligence, but more research is needed to address the practical challenges and potential pitfalls of implementing visual knowledge in large AI models.
Conclusion
The paper highlights the emerging concept of visual knowledge as a new form of knowledge representation that can capture visual concepts and their relationships in a concise, comprehensive, and interpretable manner. It underscores the pivotal role that visual knowledge is poised to play in establishing machine intelligence, given its deep roots in human cognition and intelligence.
The review provides important context by investigating the origins and development of visual knowledge in the pre-big model era, and then emphasizes the unique opportunities and significance of visual knowledge in the current era of large AI models. These powerful AI systems have the potential to greatly benefit from incorporating visual knowledge, which could help them better understand and reason about the visual world, much like humans do.
Overall, this paper lays the groundwork for further research and development in the integration of visual knowledge into advanced AI systems, with the goal of creating machines that can truly comprehend and interact with the world in a more natural and intelligent way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
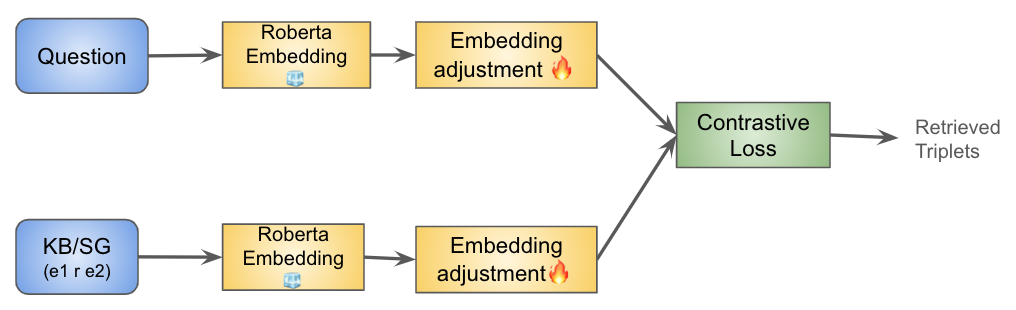
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
0
0
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
4/17/2024
🛸
Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
Yi Cheng, Ziwei Xu, Dongyun Lin, Harry Cheng, Yongkang Wong, Ying Sun, Joo Hwee Lim, Mohan Kankanhalli
0
0
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
5/22/2024

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024

Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
0
0
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
6/24/2024