Vivo : une approche multimodale de la synthese concatenative par corpus dans le cadre d'une oeuvre audiovisuelle immersive

0

Sign in to get full access
Overview
- This paper presents research on using dual modalities (text and visual) for generative pre-training of language models.
- It explores the integration of text and visual information to improve the performance of language models on various tasks.
- The paper also discusses the potential benefits and challenges of this approach, as well as potential applications in areas like human-AI collaborative authoring and multimodal perception for soft robotic interactions.
Plain English Explanation
This research looks at using both text and visual information to train language models, which are artificial intelligence systems that can understand and generate human language. The goal is to see if combining these two types of information can make the language models better at their tasks, such as answering questions or generating text.
The researchers explored different ways of integrating the text and visual data, similar to how humans use both language and visual cues to understand the world. This could be useful for applications like text-guided visual sound source localization, where the language model can use both textual and visual information to figure out where a sound is coming from.
The paper also discusses the potential benefits and challenges of this approach, and how it might be used in areas like human-AI collaborative authoring and multimodal perception for soft robotic interactions. Overall, the research aims to improve the capabilities of language models by giving them access to both textual and visual information.
Technical Explanation
The paper explores the use of dual modalities (text and visual) for generative pre-training of language models. The researchers propose a framework that integrates text and visual information to improve the performance of language models on various tasks.
The system uses a transformer-based language model that is pre-trained on a large corpus of text data. This pre-trained model is then fine-tuned on a dataset that combines text and corresponding visual information, such as images paired with captions. The researchers experiment with different ways of integrating the text and visual data, including concatenating the text and visual features, and using attention mechanisms to dynamically combine the information.
The paper presents experiments on several language understanding and generation tasks, such as question answering and text summarization. The results show that the dual-modality approach can outperform language models trained on text alone, particularly on tasks that require understanding the relationship between language and visual information.
The researchers also discuss the potential benefits and challenges of this approach, and how it might be applied in areas like human-AI collaborative authoring and multimodal perception for soft robotic interactions.
Critical Analysis
The paper presents a well-designed study that explores the integration of text and visual information for improving language models. The use of a pre-trained language model as a starting point is a sensible approach, and the experiments on various language tasks provide a comprehensive evaluation of the proposed framework.
However, the paper does not address several important limitations and potential issues with the approach. For example, the researchers do not discuss how the system might perform on more open-ended or creative tasks, such as text-guided visual sound source localization, where the language model needs to go beyond simple understanding and generation.
Additionally, the paper does not explore the robustness of the system to noisy or incomplete visual information, which could be a common challenge in real-world applications. It would be valuable to understand how the dual-modality approach might perform in the face of such challenges.
Overall, the research presented in the paper is a valuable contribution to the field of language modeling, but further exploration of the system's limitations and potential issues would strengthen the analysis and provide a more comprehensive understanding of the approach.
Conclusion
This paper presents a novel framework for integrating text and visual information to improve the performance of language models. The results suggest that the dual-modality approach can outperform language models trained on text alone, particularly on tasks that require understanding the relationship between language and visual information.
The potential applications of this research are broad, ranging from human-AI collaborative authoring to multimodal perception for soft robotic interactions. As language models continue to advance, the ability to leverage both textual and visual information will become increasingly important for a wide range of AI-powered applications.
While the paper presents a promising approach, further research is needed to address the limitations and potential issues discussed in the critical analysis. Exploring the system's performance on more open-ended and creative tasks, as well as its robustness to noisy or incomplete visual information, could provide valuable insights and help advance the field of multimodal language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vivo : une approche multimodale de la synthese concatenative par corpus dans le cadre d'une oeuvre audiovisuelle immersive
Mateo Fayet
Which visual descriptors are suitable for multi-modal interaction and how to integrate them via real-time video data analysis into a corpus-based concatenative synthesis sound system.
Read more4/17/2024
0
A Survey of Multimodal Composite Editing and Retrieval
Suyan Li, Fuxiang Huang, Lei Zhang
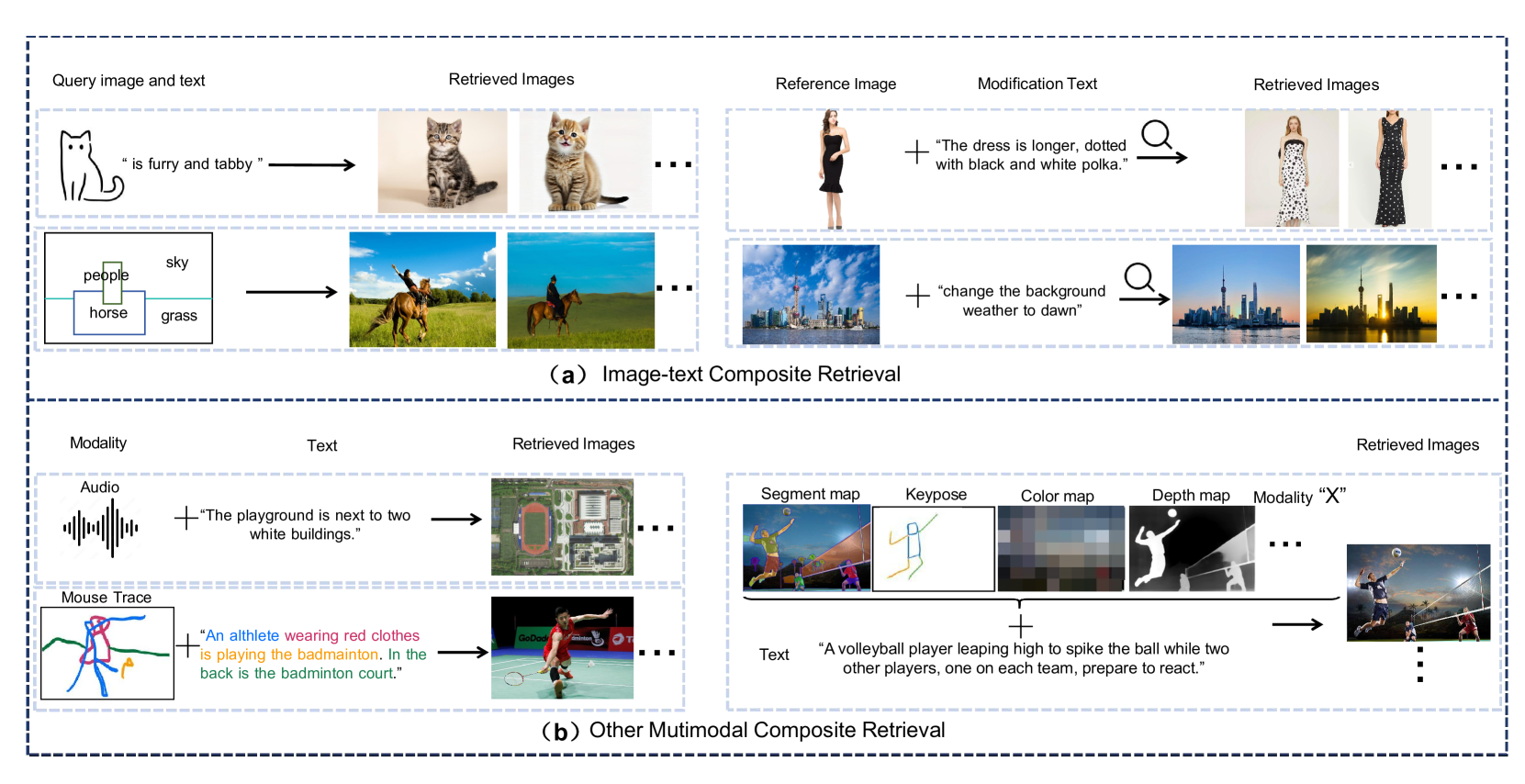
In the real world, where information is abundant and diverse across different modalities, understanding and utilizing various data types to improve retrieval systems is a key focus of research. Multimodal composite retrieval integrates diverse modalities such as text, image and audio, etc. to provide more accurate, personalized, and contextually relevant results. To facilitate a deeper understanding of this promising direction, this survey explores multimodal composite editing and retrieval in depth, covering image-text composite editing, image-text composite retrieval, and other multimodal composite retrieval. In this survey, we systematically organize the application scenarios, methods, benchmarks, experiments, and future directions. Multimodal learning is a hot topic in large model era, and have also witnessed some surveys in multimodal learning and vision-language models with transformers published in the PAMI journal. To the best of our knowledge, this survey is the first comprehensive review of the literature on multimodal composite retrieval, which is a timely complement of multimodal fusion to existing reviews. To help readers' quickly track this field, we build the project page for this survey, which can be found at https://github.com/fuxianghuang1/Multimodal-Composite-Editing-and-Retrieval.
Read more9/12/2024
📊
0
Vision+X: A Survey on Multimodal Learning in the Light of Data
Ye Zhu, Yu Wu, Nicu Sebe, Yan Yan
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, multimodal machine learning that incorporates data from various sources has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the intrinsic nature of different data modalities. We analyze the commonness and uniqueness of each data format mainly ranging from vision, audio, text, and motions, and then present the methodological advancements categorized by the combination of data modalities, such as Vision+Text, with slightly inclined emphasis on the visual data. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats. We hope that the exploitation of the alignment as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address a specific challenge related to the concrete multimodal task, prompting a unified multimodal machine learning framework closer to a real human intelligence system.
Read more6/12/2024

0
Comparative Analysis of Modality Fusion Approaches for Audio-Visual Person Identification and Verification
Aref Farhadipour, Masoumeh Chapariniya, Teodora Vukovic, Volker Dellwo
Multimodal learning involves integrating information from various modalities to enhance learning and comprehension. We compare three modality fusion strategies in person identification and verification by processing two modalities: voice and face. In this paper, a one-dimensional convolutional neural network is employed for x-vector extraction from voice, while the pre-trained VGGFace2 network and transfer learning are utilized for face modality. In addition, gammatonegram is used as speech representation in engagement with the Darknet19 pre-trained network. The proposed systems are evaluated using the K-fold cross-validation technique on the 118 speakers of the test set of the VoxCeleb2 dataset. The comparative evaluations are done for single-modality and three proposed multimodal strategies in equal situations. Results demonstrate that the feature fusion strategy of gammatonegram and facial features achieves the highest performance, with an accuracy of 98.37% in the person identification task. However, concatenating facial features with the x-vector reaches 0.62% for EER in verification tasks.
Read more9/4/2024