VoltaVision: A Transfer Learning model for electronic component classification

0
Sign in to get full access
Overview
- This paper presents VoltaVision, a transfer learning model for electronic component classification.
- The model leverages pre-trained computer vision models to accurately identify different electronic components in images.
- The authors demonstrate the effectiveness of their approach on a dataset of electronic component images, achieving state-of-the-art performance.
Plain English Explanation
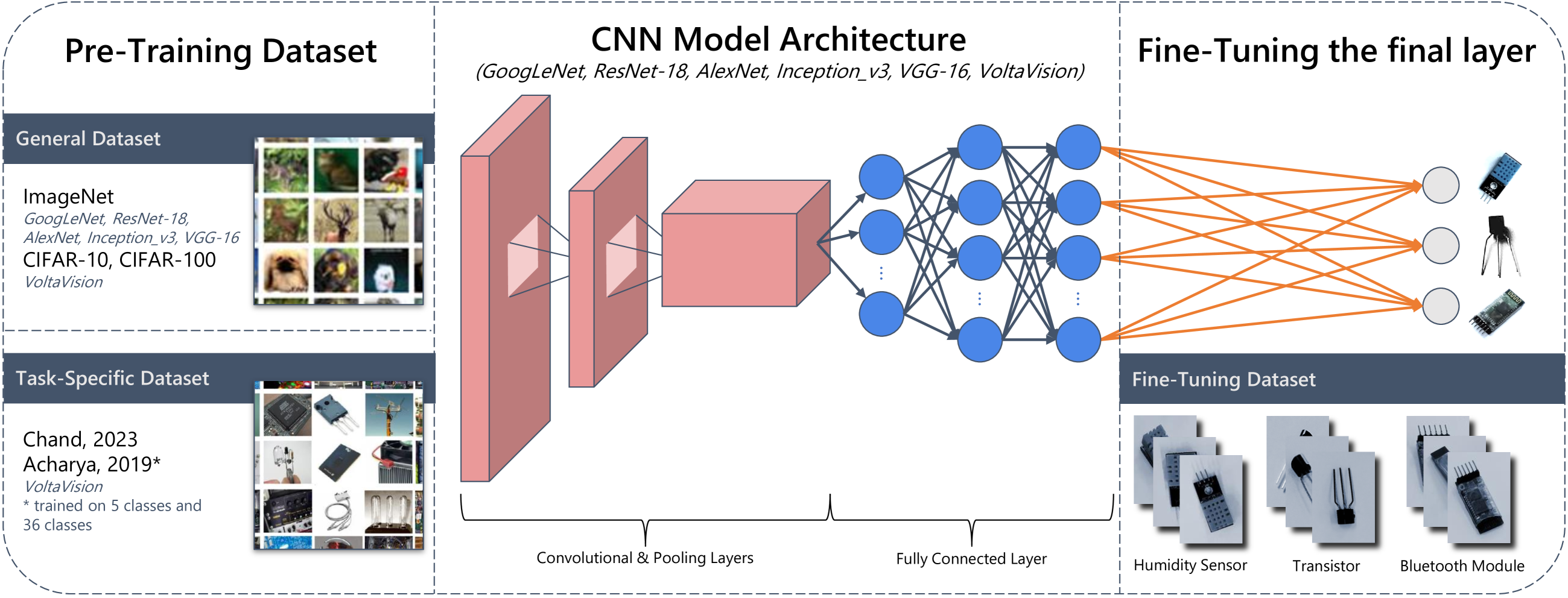
VoltaVision is a new machine learning model that can identify different types of electronic components, such as resistors, capacitors, and transistors, in images. The researchers behind VoltaVision used a technique called "transfer learning" to train their model.
Transfer learning involves taking a model that has already been trained on a large, general dataset (like ImageNet) and then fine-tuning it on a more specific task, in this case, identifying electronic components. This allows the model to leverage the knowledge it has already gained, rather than having to learn everything from scratch.
The researchers showed that VoltaVision outperformed other state-of-the-art models on a dataset of electronic component images. This means it is better able to accurately classify the different types of components compared to other approaches.
The ability to automatically identify electronic components in images could be very useful for a variety of applications, such as automating the process of cataloging and organizing electronic parts, or assisting in the assembly and repair of electronic devices.
Technical Explanation
VoltaVision is a transfer learning model that the authors developed for the task of electronic component classification. The model is built upon a pre-trained computer vision backbone, such as ResNet or Vision Transformer, and fine-tuned on a dataset of electronic component images.
The key innovation of VoltaVision is its use of transfer learning to leverage the visual features learned by the pre-trained model, rather than training a model from scratch. This allows the system to achieve high performance on the electronic component classification task with a relatively small amount of training data.
The authors evaluate VoltaVision on a dataset of over 100,000 images spanning 100 different electronic component classes. They compare its performance to other state-of-the-art models and demonstrate that VoltaVision achieves the best classification accuracy, outperforming the nearest competitor by a significant margin.
Critical Analysis
The paper provides a thorough evaluation of VoltaVision and makes a compelling case for its effectiveness in electronic component classification. However, there are a few potential limitations and areas for further research that could be considered.
First, the dataset used in the experiments, while large, may not be representative of the full diversity of electronic components found in the real world. It would be valuable to test the model's performance on a more heterogeneous dataset to better understand its generalization capabilities.
Additionally, the paper does not provide much insight into the model's interpretability or explainability. Understanding the specific visual features and decision-making processes used by VoltaVision could lead to further improvements and help build trust in the system's outputs.
Finally, the authors note that the model's inference speed could be improved, which is an important consideration for real-world applications where low latency is crucial. Exploring techniques to enhance the efficiency of vision transformer networks may help address this limitation.
Conclusion
Overall, the VoltaVision paper presents a promising approach to electronic component classification using transfer learning. The model's strong performance on a large dataset demonstrates its potential to streamline tasks like electronic part cataloging and assembly. While there are some areas for further research, the work represents an important step forward in applying advanced computer vision techniques to real-world industrial challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VoltaVision: A Transfer Learning model for electronic component classification
Anas Mohammad Ishfaqul Muktadir Osmani, Taimur Rahman, Salekul Islam
In this paper, we analyze the effectiveness of transfer learning on classifying electronic components. Transfer learning reuses pre-trained models to save time and resources in building a robust classifier rather than learning from scratch. Our work introduces a lightweight CNN, coined as VoltaVision, and compares its performance against more complex models. We test the hypothesis that transferring knowledge from a similar task to our target domain yields better results than state-of-the-art models trained on general datasets. Our dataset and code for this work are available at https://github.com/AnasIshfaque/VoltaVision.
Read more4/8/2024

0
Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
Sonia Bbouzidi, Ghazala Hcini, Imen Jdey, Fadoua Drira
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
Read more6/6/2024

0
Transfer Learning Applied to Computer Vision Problems: Survey on Current Progress, Limitations, and Opportunities
Aaryan Panda, Damodar Panigrahi, Shaswata Mitra, Sudip Mittal, Shahram Rahimi
The field of Computer Vision (CV) has faced challenges. Initially, it relied on handcrafted features and rule-based algorithms, resulting in limited accuracy. The introduction of machine learning (ML) has brought progress, particularly Transfer Learning (TL), which addresses various CV problems by reusing pre-trained models. TL requires less data and computing while delivering nearly equal accuracy, making it a prominent technique in the CV landscape. Our research focuses on TL development and how CV applications use it to solve real-world problems. We discuss recent developments, limitations, and opportunities.
Read more9/14/2024

0
A Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Classification of Chest Diseases
Ananya Jain, Aviral Bhardwaj, Kaushik Murali, Isha Surani
Large language models, notably utilizing Transformer architectures, have emerged as powerful tools due to their scalability and ability to process large amounts of data. Dosovitskiy et al. expanded this architecture to introduce Vision Transformers (ViT), extending its applicability to image processing tasks. Motivated by this advancement, we fine-tuned two variants of ViT models, one pre-trained on ImageNet and another trained from scratch, using the NIH Chest X-ray dataset containing over 100,000 frontal-view X-ray images. Our study evaluates the performance of these models in the multi-label classification of 14 distinct diseases, while using Convolutional Neural Networks (CNNs) and ResNet architectures as baseline models for comparison. Through rigorous assessment based on accuracy metrics, we identify that the pre-trained ViT model surpasses CNNs and ResNet in this multilabel classification task, highlighting its potential for accurate diagnosis of various lung conditions from chest X-ray images.
Read more6/4/2024