VSA4VQA: Scaling a Vector Symbolic Architecture to Visual Question Answering on Natural Images

0

Sign in to get full access
Overview
- This paper presents VSA4VQA, a system that applies a Vector Symbolic Architecture (VSA) to the task of Visual Question Answering (VQA) on natural images.
- VSA is a computational approach that represents information using high-dimensional vectors, allowing for efficient reasoning and inference.
- The authors scaled the VSA approach to handle the complexity of natural images and language-based questions, aiming to advance the state-of-the-art in VQA.
Plain English Explanation
The researchers developed a system called VSA4VQA that uses a Vector Symbolic Architecture (VSA) to answer questions about natural images. VSA is a way of representing information using high-dimensional vectors, which can make it easier to do certain types of reasoning and problem-solving.
Previous VSA systems have been used for simpler tasks, but the team wanted to see if they could scale it up to handle the complexities of real-world images and language-based questions. This could help push the boundaries of what's possible in the field of Visual Question Answering (VQA), where the goal is to build AI systems that can understand an image and answer questions about it.
By adapting the VSA approach to work with natural images and language, the researchers hope to create a more flexible and powerful VQA system that can handle a wider range of questions and scenarios.
Technical Explanation
The core of the VSA4VQA system is a Vector Symbolic Architecture (VSA) that represents visual and linguistic information using high-dimensional vectors. This allows the system to perform compositional reasoning on the image and question data.
The authors developed new techniques to scale the VSA approach to handle the complexity of natural images, going beyond previous VSA systems that were limited to simpler visual domains. This includes integrating the VSA with deep learning models for feature extraction and multimodal fusion.
The resulting VSA4VQA system takes an image and a question as input, and produces an answer by reasoning over the high-dimensional vector representations. This end-to-end approach allows the system to learn how to map the visual and linguistic inputs to appropriate answers.
Critical Analysis
The authors acknowledge several limitations of the VSA4VQA system, such as the computational complexity of the high-dimensional vector operations and the need for large training datasets. They also note that the system may struggle with certain types of questions that require more complex reasoning or commonsense understanding.
Additionally, the paper does not provide a comprehensive comparison to state-of-the-art VQA models, making it difficult to fully assess the system's performance relative to other approaches. Further research and experimentation would be needed to better understand the strengths, weaknesses, and potential applications of the VSA4VQA approach.
Conclusion
The VSA4VQA system represents an intriguing attempt to apply a Vector Symbolic Architecture to the challenging task of Visual Question Answering on natural images. By leveraging the compositional and reasoning capabilities of VSA, the authors have taken a step towards developing more flexible and powerful VQA models.
While the current system has some limitations, the research opens up new avenues for exploring the intersection of symbolic and deep learning approaches in multimodal AI. Continued advancements in this direction could lead to VQA systems that are better able to understand and reason about the world in human-like ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VSA4VQA: Scaling a Vector Symbolic Architecture to Visual Question Answering on Natural Images
Anna Penzkofer, Lei Shi, Andreas Bulling
While Vector Symbolic Architectures (VSAs) are promising for modelling spatial cognition, their application is currently limited to artificially generated images and simple spatial queries. We propose VSA4VQA - a novel 4D implementation of VSAs that implements a mental representation of natural images for the challenging task of Visual Question Answering (VQA). VSA4VQA is the first model to scale a VSA to complex spatial queries. Our method is based on the Semantic Pointer Architecture (SPA) to encode objects in a hyperdimensional vector space. To encode natural images, we extend the SPA to include dimensions for object's width and height in addition to their spatial location. To perform spatial queries we further introduce learned spatial query masks and integrate a pre-trained vision-language model for answering attribute-related questions. We evaluate our method on the GQA benchmark dataset and show that it can effectively encode natural images, achieving competitive performance to state-of-the-art deep learning methods for zero-shot VQA.
Read more5/8/2024

0
Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Read more6/17/2024
🖼️
0
From Image to Language: A Critical Analysis of Visual Question Answering (VQA) Approaches, Challenges, and Opportunities
Md Farhan Ishmam, Md Sakib Hossain Shovon, M. F. Mridha, Nilanjan Dey
The multimodal task of Visual Question Answering (VQA) encompassing elements of Computer Vision (CV) and Natural Language Processing (NLP), aims to generate answers to questions on any visual input. Over time, the scope of VQA has expanded from datasets focusing on an extensive collection of natural images to datasets featuring synthetic images, video, 3D environments, and various other visual inputs. The emergence of large pre-trained networks has shifted the early VQA approaches relying on feature extraction and fusion schemes to vision language pre-training (VLP) techniques. However, there is a lack of comprehensive surveys that encompass both traditional VQA architectures and contemporary VLP-based methods. Furthermore, the VLP challenges in the lens of VQA haven't been thoroughly explored, leaving room for potential open problems to emerge. Our work presents a survey in the domain of VQA that delves into the intricacies of VQA datasets and methods over the field's history, introduces a detailed taxonomy to categorize the facets of VQA, and highlights the recent trends, challenges, and scopes for improvement. We further generalize VQA to multimodal question answering, explore tasks related to VQA, and present a set of open problems for future investigation. The work aims to navigate both beginners and experts by shedding light on the potential avenues of research and expanding the boundaries of the field.
Read more9/25/2024
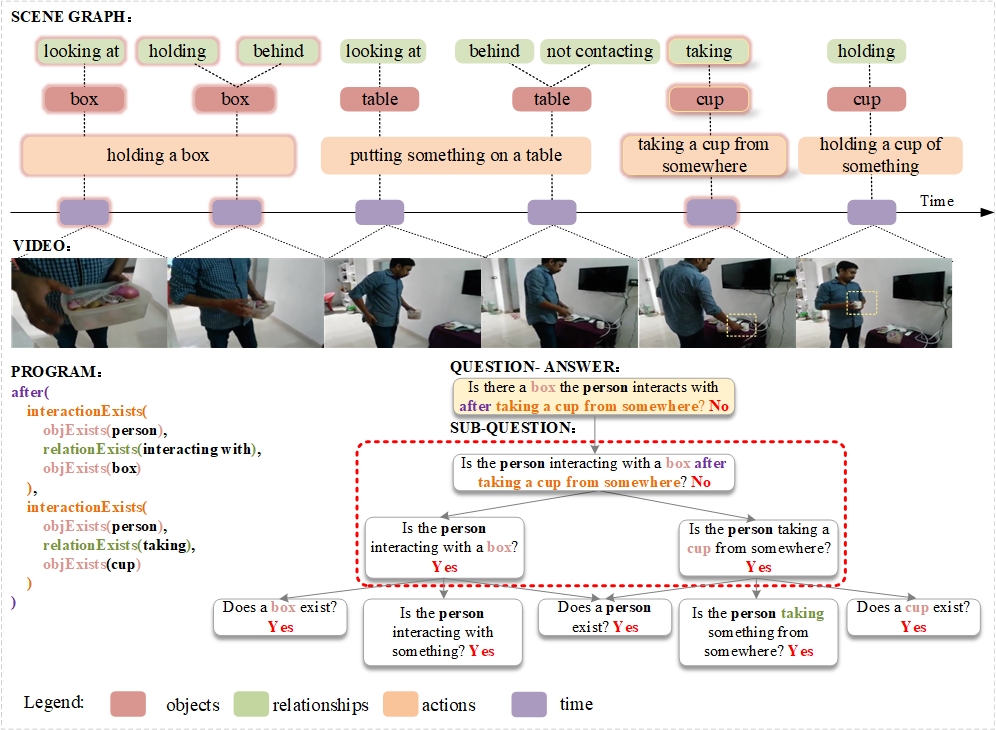
0
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Lili Liang, Guanglu Sun, Jin Qiu, Lizhong Zhang
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
Read more4/8/2024