What's in an embedding? Would a rose by any embedding smell as sweet?

0

Sign in to get full access
Overview
- This paper explores the nature of embeddings, which are mathematical representations of data that capture important features and relationships.
- The authors investigate whether the specific embedding used for a task affects the performance and interpretability of the results.
- They examine the differences between algebraic and geometric approaches to embedding and how these impact the meaning and usefulness of the embeddings.
Plain English Explanation
Embeddings are a way of representing information in a numerical format that preserves the key relationships and characteristics of the original data. This allows machine learning models to work with the data more effectively. However, there are different ways to create these embeddings, and the approach used can significantly impact the results.
The paper looks at two main approaches: algebraic embeddings, which focus on the mathematical properties of the data, and geometric embeddings, which focus on the spatial relationships between data points. The authors explore how these different representations can lead to very different interpretations and outcomes, even for the same underlying information.
For example, an embedding that captures concept-level relationships may be more useful for certain tasks, while an embedding that preserves privacy may be better for others. The key insight is that the choice of embedding approach is crucial and can profoundly shape the results and conclusions drawn from the data.
Technical Explanation
The paper begins by contrasting algebraic and geometric approaches to embeddings. Algebraic embeddings focus on the linear and matrix-based properties of the data, aiming to preserve key algebraic relationships. In contrast, geometric embeddings focus on the spatial relationships between data points, representing them as points in a high-dimensional space.
The authors then explore how these different representations can lead to divergent results, even for the same underlying data. For example, they discuss how certain "easy" problems that large language models struggle with may be due to misalignments between the model's internal representations and the true conceptual structure of the data.
The paper also examines the implications of these findings for tasks like reasoning about inconsistencies in large language models and the potential for large language models to perform better on certain tasks than expected. The key insight is that the choice of embedding approach can significantly impact the performance, interpretability, and broader implications of machine learning models.
Critical Analysis
The paper raises important questions about the nature of embeddings and their role in machine learning. The authors acknowledge that both algebraic and geometric approaches have their strengths and weaknesses, and that the choice of embedding method should be carefully considered based on the specific task and goals of the analysis.
One limitation of the paper is that it does not provide a comprehensive evaluation of the performance and interpretability of different embedding approaches across a wide range of tasks and datasets. The authors focus primarily on conceptual and theoretical discussions, which could benefit from more empirical support.
Additionally, the paper does not delve deeply into the potential biases and ethical considerations that may arise from the use of different embedding techniques. As embeddings become increasingly prevalent in high-stakes applications, it will be important to further investigate these issues and their implications for fairness, accountability, and transparency in machine learning.
Conclusion
This paper offers a thought-provoking exploration of the nature of embeddings and the impact of different approaches on the performance and interpretability of machine learning models. The authors highlight the importance of carefully considering the choice of embedding method, as it can profoundly shape the results and conclusions drawn from the data.
The insights presented in this paper have broad implications for the field of machine learning, encouraging researchers and practitioners to critically examine the assumptions and limitations of their chosen embedding techniques. By better understanding the strengths and weaknesses of algebraic and geometric embeddings, the community can work towards developing more robust and interpretable machine learning systems that can be applied with greater confidence in a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What's in an embedding? Would a rose by any embedding smell as sweet?
Venkat Venkatasubramanian
Large Language Models (LLMs) are often criticized for lacking true understanding and the ability to reason with their knowledge, being seen merely as autocomplete systems. We believe that this assessment might be missing a nuanced insight. We suggest that LLMs do develop a kind of empirical understanding that is geometry-like, which seems adequate for a range of applications in NLP, computer vision, coding assistance, etc. However, this geometric understanding, built from incomplete and noisy data, makes them unreliable, difficult to generalize, and lacking in inference capabilities and explanations, similar to the challenges faced by heuristics-based expert systems decades ago. To overcome these limitations, we suggest that LLMs should be integrated with an algebraic representation of knowledge that includes symbolic AI elements used in expert systems. This integration aims to create large knowledge models (LKMs) that not only possess deep knowledge grounded in first principles, but also have the ability to reason and explain, mimicking human expert capabilities. To harness the full potential of generative AI safely and effectively, a paradigm shift is needed from LLM to more comprehensive LKM.
Read more6/18/2024
0
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
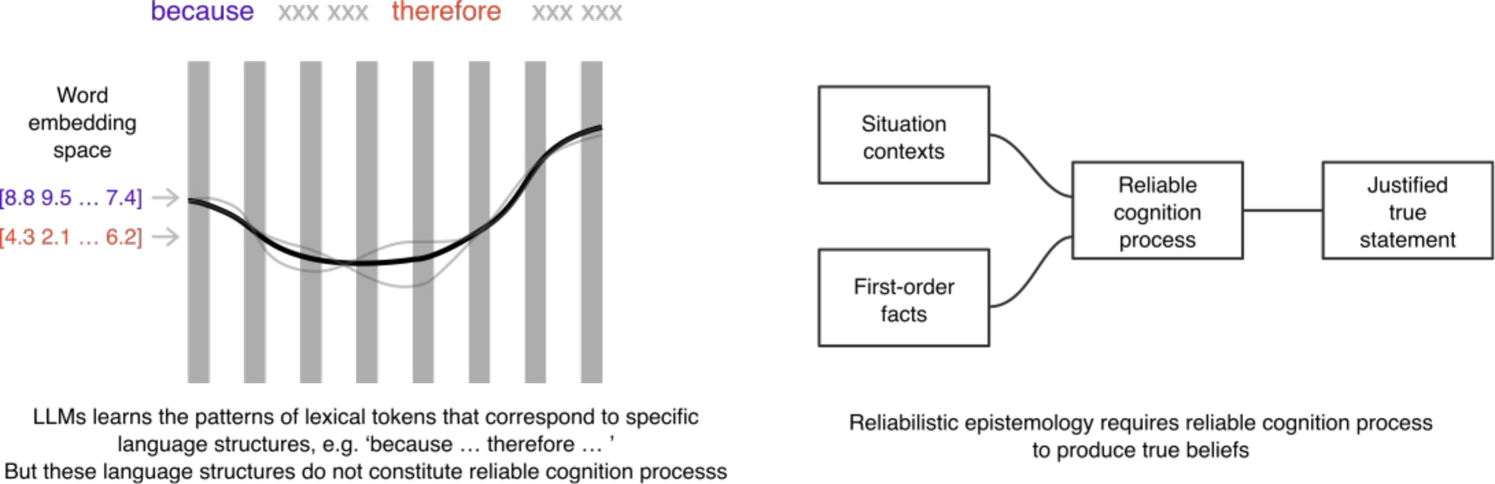
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024

0
Large Knowledge Model: Perspectives and Challenges
Huajun Chen
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
Read more6/27/2024

0
Large Language Model Enhanced Knowledge Representation Learning: A Survey
Xin Wang, Zirui Chen, Haofen Wang, Leong Hou U, Zhao Li, Wenbin Guo
The integration of Large Language Models (LLM) with Knowledge Representation Learning (KRL) signifies a significant advancement in the field of artificial intelligence (AI), enhancing the ability to capture and utilize both structure and textual information. Despite the increasing research on enhancing KRL with LLMs, a thorough survey that analyse processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain.
Read more7/19/2024