World-Model-Based Control for Industrial box-packing of Multiple Objects using NewtonianVAE

0
👨🏫
Sign in to get full access
Overview
- This research paper focuses on the problem of industrial box-packing, which involves the precise placement of multiple objects in a specific order.
- The researchers designed a robotic system that uses a vision-based learning control model to automate this task.
- The proposed model, called in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), employs an RGB camera to capture the posture of the objects grasped by the robotic hand.
- The researchers demonstrate that their model, trained for a single object-placement task, can handle sequential tasks without additional training.
- The robotic system was tested on industrial box-packing tasks and achieved a 100% success rate, outperforming state-of-the-art and conventional approaches.
Plain English Explanation
In factories, workers often need to carefully pack identical objects into boxes. This can be a tedious and repetitive task. The researchers in this study wanted to create a robotic system that could automate this process.
The key challenge is that the robot needs to know the exact position and orientation of the object it is holding in order to place it accurately in the box. The researchers developed a special camera system that can "see" the object in the robot's hand and understand how it is positioned.
They trained their robot using this camera system to learn how to pick up and place objects in a specific order. Interestingly, the researchers found that once the robot learned this task for a single object, it could then apply that same knowledge to handle a sequence of different objects without any additional training.
When the researchers tested the robot on real industrial box-packing tasks, it was able to complete the tasks with a 100% success rate. This is a significant improvement over previous approaches, showing the power of this vision-based learning control model.
Technical Explanation
The researchers designed a robotic system that employs a vision-based learning control model to automate industrial box-packing tasks. The key component of their system is the in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), which uses an RGB camera to capture the posture of objects grasped by the robotic hand.
The researchers demonstrate that their model, trained for a single object-placement task, can handle sequential tasks without additional training. This is a significant advantage, as factories often need to pack new types of products, and it should be easy to collect data to train the model.
To evaluate the effectiveness of the proposed model, the researchers employed a real robot to perform sequential industrial box-packing tasks. The results showed that the ihVS-NVAE model achieved a 100% success rate, outperforming the state-of-the-art and conventional approaches. This highlights the superior effectiveness and potential of the researchers' approach in real-world industrial settings.
Critical Analysis
The researchers provide a robust evaluation of their proposed model, demonstrating its superior performance in real-world industrial box-packing tasks. However, the paper does not address potential limitations or areas for further research.
One potential concern is the model's reliance on a single RGB camera to capture the in-hand posture of objects. It would be interesting to see how the model's performance might be affected by factors such as occlusion, lighting conditions, or object complexity.
Additionally, the researchers do not discuss the model's adaptability to handle a wide range of object shapes, sizes, and materials. It would be valuable to understand the model's limitations and the types of industrial tasks it is best suited for.
Further research could also explore the integration of the ihVS-NVAE model with other robotic capabilities, such as robust visual-inertial navigation or data-efficient and explainable safe box manipulation, to create a more comprehensive industrial automation system.
Conclusion
This research paper presents a novel robotic system that uses a vision-based learning control model, the ihVS-NVAE, to automate industrial box-packing tasks. The key innovation is the model's ability to handle sequential tasks without additional training, which is a significant advantage in real-world factory settings.
The researchers' evaluation of the system's performance in real-world industrial box-packing tasks demonstrates its superior effectiveness, with a 100% success rate. This highlights the potential of the proposed approach to revolutionize industrial automation and reduce the burden on human workers.
While the paper does not address all potential limitations, the researchers' work represents an important step forward in the development of robust and adaptable robotic systems for industrial applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
World-Model-Based Control for Industrial box-packing of Multiple Objects using NewtonianVAE
Yusuke Kato, Ryo Okumura, Tadahiro Taniguchi
The process of industrial box-packing, which involves the accurate placement of multiple objects, requires high-accuracy positioning and sequential actions. When a robot is tasked with placing an object at a specific location with high accuracy, it is important not only to have information about the location of the object to be placed, but also the posture of the object grasped by the robotic hand. Often, industrial box-packing requires the sequential placement of identically shaped objects into a single box. The robot's action should be determined by the same learned model. In factories, new kinds of products often appear and there is a need for a model that can easily adapt to them. Therefore, it should be easy to collect data to train the model. In this study, we designed a robotic system to automate real-world industrial tasks, employing a vision-based learning control model. We propose in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), which employs an RGB camera to obtain in-hand postures of objects. We demonstrate that our model, trained for a single object-placement task, can handle sequential tasks without additional training. To evaluate efficacy of the proposed model, we employed a real robot to perform sequential industrial box-packing of multiple objects. Results showed that the proposed model achieved a 100% success rate in industrial box-packing tasks, thereby outperforming the state-of-the-art and conventional approaches, underscoring its superior effectiveness and potential in industrial tasks.
Read more4/5/2024
💬
0
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Ozan Ozdemir, Matthias Kerzel, Cornelius Weber, Jae Hee Lee, Stefan Wermter
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.
Read more5/7/2024
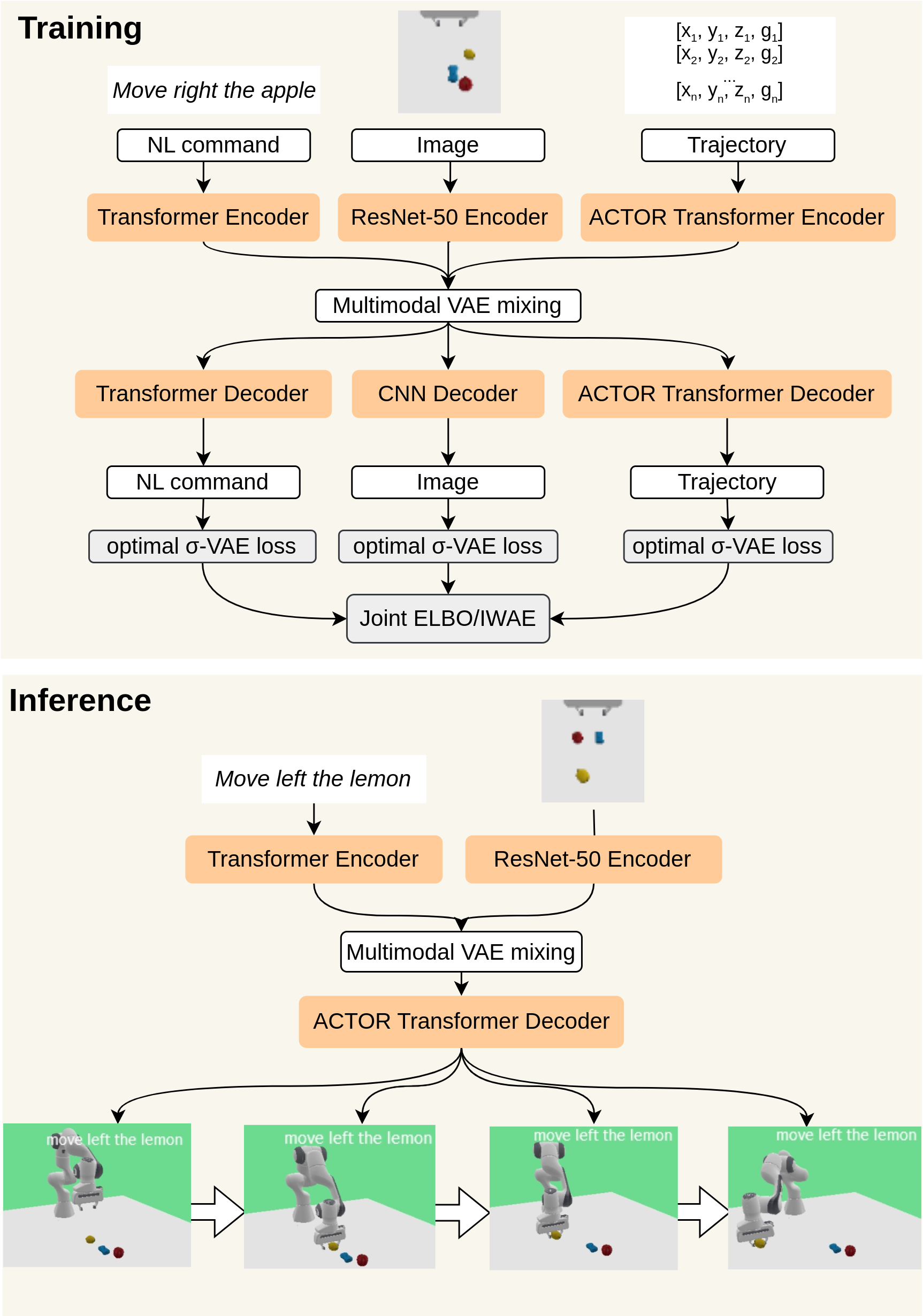
0
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
Read more4/3/2024
📈
0
Unified Control Framework for Real-Time Interception and Obstacle Avoidance of Fast-Moving Objects with Diffusion Variational Autoencoder
Apan Dastider, Hao Fang, Mingjie Lin
Real-time interception of fast-moving objects by robotic arms in dynamic environments poses a formidable challenge due to the need for rapid reaction times, often within milliseconds, amidst dynamic obstacles. This paper introduces a unified control framework to address the above challenge by simultaneously intercepting dynamic objects and avoiding moving obstacles. Central to our approach is using diffusion-based variational autoencoder for motion planning to perform both object interception and obstacle avoidance. We begin by encoding the high-dimensional temporal information from streaming events into a two-dimensional latent manifold, enabling the discrimination between safe and colliding trajectories, culminating in the construction of an offline densely connected trajectory graph. Subsequently, we employ an extended Kalman filter to achieve precise real-time tracking of the moving object. Leveraging a graph-traversing strategy on the established offline dense graph, we generate encoded robotic motor control commands. Finally, we decode these commands to enable real-time motion of robotic motors, ensuring effective obstacle avoidance and high interception accuracy of fast-moving objects. Experimental validation on both computer simulations and autonomous 7-DoF robotic arms demonstrates the efficacy of our proposed framework. Results indicate the capability of the robotic manipulator to navigate around multiple obstacles of varying sizes and shapes while successfully intercepting fast-moving objects thrown from different angles by hand. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/multirobotskill/home.
Read more4/4/2024