Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities

1

Sign in to get full access
Overview
- The paper proposes a new multi-tower decoder architecture called "Zipper" for fusing different input modalities, such as text, audio, and video, to improve performance on various tasks.
- Zipper uses a modular design with separate decoding towers for each modality, which are then combined to leverage the strengths of each modality.
- The authors demonstrate the effectiveness of Zipper on several benchmarks, showing improved performance compared to existing multimodal fusion approaches.
Plain English Explanation
The Zipper paper introduces a new way to combine different types of information, like text, audio, and video, to improve the performance of artificial intelligence (AI) systems on various tasks. The key idea is to have separate "towers" in the AI model, each focused on processing a different type of input, and then "zip" these towers together to take advantage of the unique strengths of each modality.
For example, an AI system might use one tower to process text, another to process audio, and a third to process video. By combining the outputs from these towers, the system can make more accurate predictions or generate more natural responses than if it had only used a single type of input.
The Zipformer paper and the Towards Multi-Task, Multi-Modal Models for Video paper provide additional context on how multimodal fusion can be applied to speech recognition and video analysis, respectively.
Overall, the Zipper approach aims to help AI systems better understand and utilize the rich, complementary information available in different types of data, leading to more powerful and versatile AI applications.
Technical Explanation
The Zipper paper presents a novel multi-tower decoder architecture for fusing multiple input modalities, such as text, audio, and video. The key innovation is the use of separate decoding towers for each modality, which are then combined to leverage the strengths of each.
The architecture consists of an encoder that processes the input data, and multiple decoder towers that specialize in different modalities. Each tower has its own attention mechanism and output layer, allowing it to focus on the most relevant features for its particular modality. The outputs from the towers are then "zipped" together, using a learned fusion mechanism, to produce the final output.
The authors evaluate Zipper on several benchmarks, including multimodal machine translation, visual question answering, and video captioning. The results demonstrate that Zipper outperforms existing multimodal fusion approaches, achieving state-of-the-art performance on several tasks.
Critical Analysis
The Zipper paper presents a compelling approach to multimodal fusion, but there are a few potential limitations and areas for further research:
-
The paper does not provide a detailed analysis of the computational and memory requirements of the Zipper architecture, which could be an important consideration for real-world applications.
-
While the authors demonstrate the effectiveness of Zipper on several benchmarks, it would be interesting to see how the approach generalizes to a wider range of tasks and datasets, especially in more complex, real-world scenarios.
-
The fusion mechanism used in Zipper is relatively simple, and more sophisticated techniques, such as those explored in the OmniFusion technical report, could potentially further improve performance.
-
The paper does not discuss the interpretability or explainability of the Zipper model, which could be an important consideration for applications where transparency and accountability are crucial.
Overall, the Zipper paper makes a valuable contribution to the field of multimodal fusion, and the proposed approach represents a promising direction for future research and development in this area.
Conclusion
The Zipper paper introduces a novel multi-tower decoder architecture for effectively fusing multiple input modalities, such as text, audio, and video. By using separate decoding towers for each modality and then combining their outputs, Zipper is able to leverage the unique strengths of each data type to improve performance on a variety of tasks.
The results presented in the paper demonstrate the effectiveness of the Zipper approach, which outperforms existing multimodal fusion techniques on several benchmarks. While the paper identifies a few areas for further exploration, the Zipper architecture represents an important step forward in the development of powerful, versatile AI systems that can seamlessly integrate and capitalize on diverse sources of information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
Vicky Zayats, Peter Chen, Melissa Ferrari, Dirk Padfield
Integrating multiple generative foundation models, especially those trained on different modalities, into something greater than the sum of its parts poses significant challenges. Two key hurdles are the availability of aligned data (concepts that contain similar meaning but is expressed differently in different modalities), and effectively leveraging unimodal representations in cross-domain generative tasks, without compromising their original unimodal capabilities. We propose Zipper, a multi-tower decoder architecture that addresses these concerns by using cross-attention to flexibly compose multimodal generative models from independently pre-trained unimodal decoders. In our experiments fusing speech and text modalities, we show the proposed architecture performs very competitively in scenarios with limited aligned text-speech data. We also showcase the flexibility of our model to selectively maintain unimodal (e.g., text-to-text generation) generation performance by freezing the corresponding modal tower (e.g. text). In cross-modal tasks such as automatic speech recognition (ASR) where the output modality is text, we show that freezing the text backbone results in negligible performance degradation. In cross-modal tasks such as text-to-speech generation (TTS) where the output modality is speech, we show that using a pre-trained speech backbone results in superior performance to the baseline.
Read more6/3/2024
🌀
5
Data-Efficient Multimodal Fusion on a Single GPU
Noel Vouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, Maksims Volkovs
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $sim ! 600times$ fewer GPU days and $sim ! 80times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
Read more4/11/2024
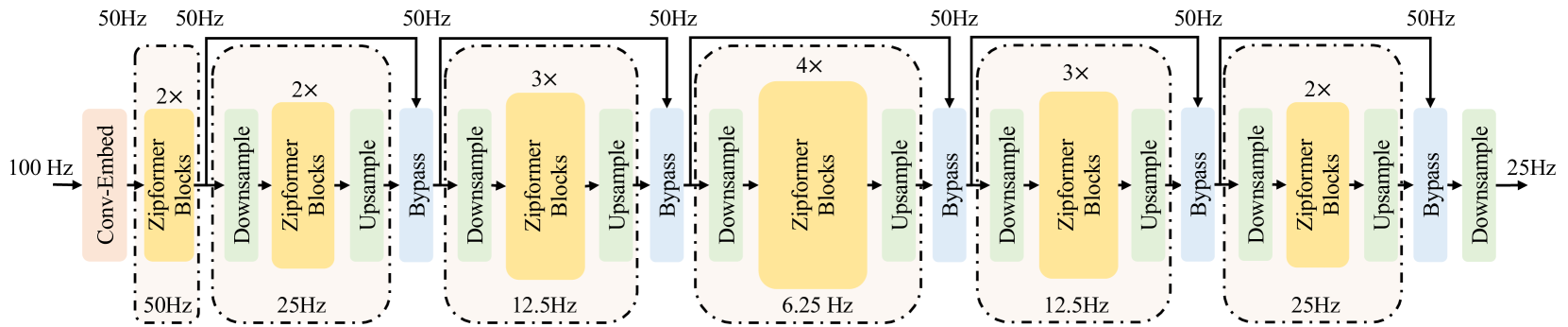
0
Zipformer: A faster and better encoder for automatic speech recognition
Zengwei Yao, Liyong Guo, Xiaoyu Yang, Wei Kang, Fangjun Kuang, Yifan Yang, Zengrui Jin, Long Lin, Daniel Povey
The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
Read more4/11/2024
🌐
0
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
Read more5/28/2024