CQIL: Inference Latency Optimization with Concurrent Computation of Quasi-Independent Layers

0
Sign in to get full access
Overview
- Proposes a new technique called CQIL (Concurrent Computation of Quasi-Independent Layers) to optimize inference latency for large neural networks
- Focuses on exploiting the quasi-independent nature of certain layers to enable concurrent computation and reduce overall inference time
- Demonstrates significant improvements in inference latency compared to existing approaches on various computer vision and natural language processing models
Plain English Explanation
The paper introduces a new method called CQIL (Concurrent Computation of Quasi-Independent Layers) that aims to speed up the process of making predictions with large neural network models, also known as the inference phase. The key idea is to take advantage of the fact that some layers in these models can be computed independently of each other, at least to a certain degree. By running these layers concurrently, the total time required for the model to make a prediction can be reduced.
This is particularly important for real-world applications where the speed of making predictions is crucial, such as autonomous vehicles, real-time language translation, or edge computing scenarios. The researchers demonstrate that CQIL can significantly improve inference latency compared to other techniques, without sacrificing the accuracy of the models.
Technical Explanation
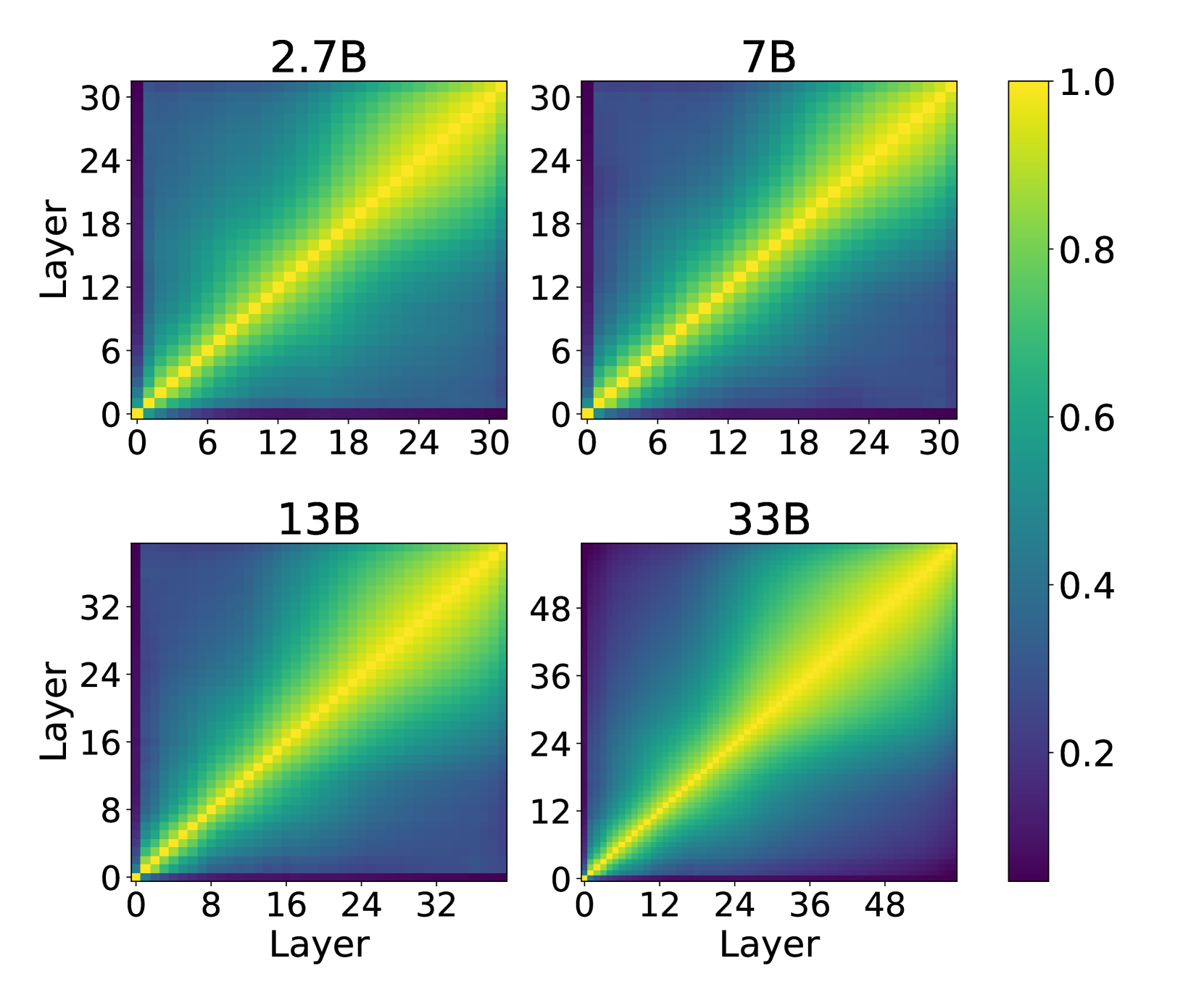
The paper first reviews existing approaches for optimizing inference latency, such as layer fusion, quantization, and hardware acceleration. It then introduces the CQIL technique, which identifies quasi-independent layers in the neural network and computes them concurrently to reduce the overall inference time.
The key steps of CQIL are:
- Analyzing the neural network to identify quasi-independent layers, which can be computed independently without significantly impacting the overall accuracy.
- Reorganizing the computation graph to enable the concurrent execution of these quasi-independent layers.
- Implementing a runtime scheduler that efficiently schedules the concurrent execution of the layers on available hardware resources.
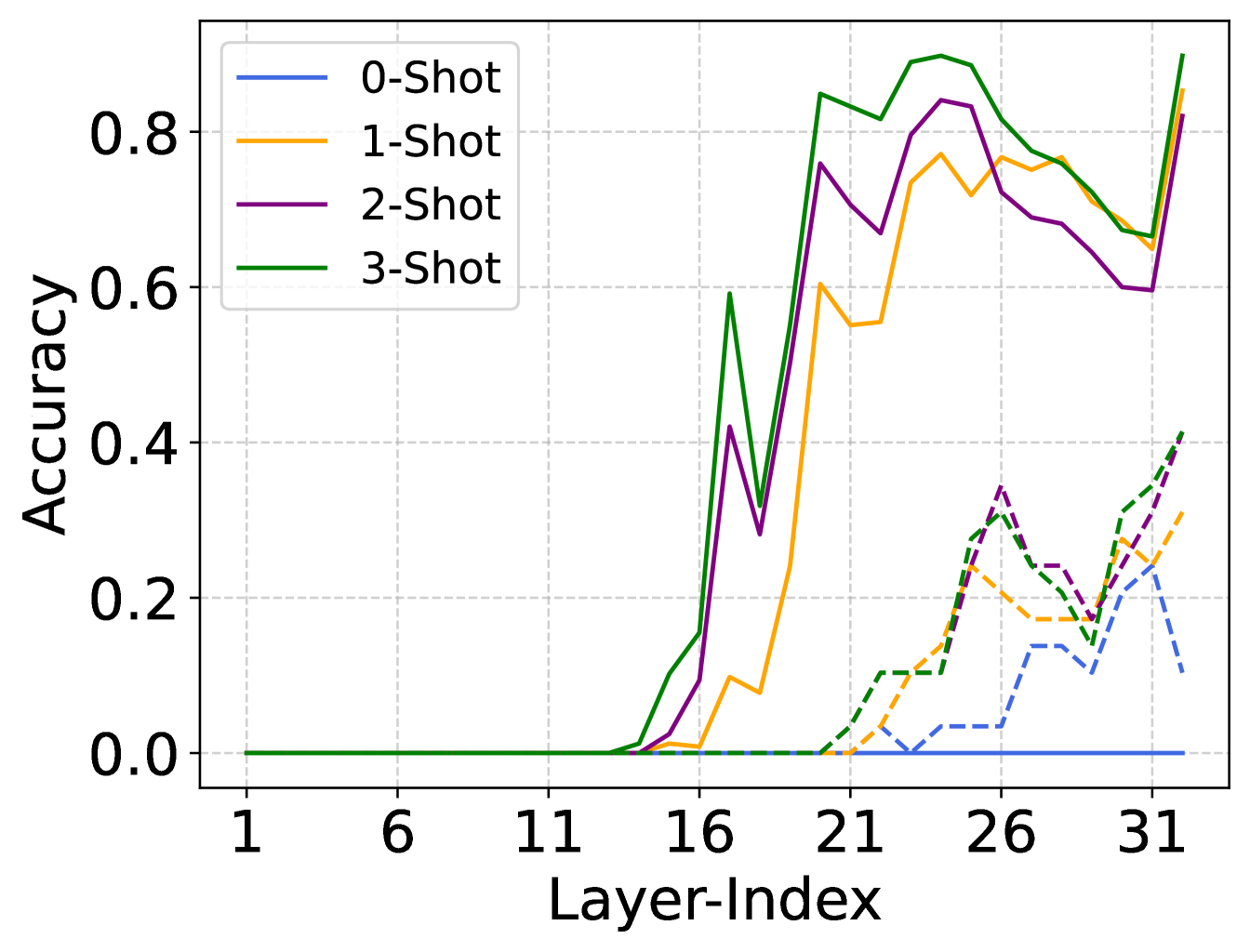
The authors evaluate CQIL on various computer vision and natural language processing models, including ResNet, BERT, and GPT-2. They demonstrate that CQIL can achieve significant improvements in inference latency, ranging from 20% to 50%, compared to existing techniques, while maintaining the original model accuracy.
Critical Analysis
The paper provides a comprehensive evaluation of CQIL and its effectiveness in improving inference latency across different model architectures and tasks. However, there are a few limitations and potential areas for further research:
- The paper focuses on identifying quasi-independent layers at the layer level, but it may be possible to find more fine-grained, neuron-level dependencies that could be exploited for even greater parallelization.
- The impact of CQIL on energy efficiency and environmental sustainability of inference is not explored, which is an important consideration for real-world deployment.
- The runtime scheduling algorithm could be further optimized to handle dynamic workloads and adapt to changing hardware resources more efficiently.
Overall, the CQIL technique represents a promising approach to accelerate inference for large neural networks, and the insights provided in this paper can inform future research in this area.
Conclusion
The CQIL technique proposed in this paper offers a novel way to optimize inference latency for large neural networks by exploiting the quasi-independent nature of certain layers. The authors demonstrate significant improvements in inference speed across a range of computer vision and natural language processing models, without sacrificing model accuracy.
This work highlights the importance of understanding the internal structure and dependencies within neural networks to unlock opportunities for parallel computation and efficient inference. As AI models continue to grow in size and complexity, techniques like CQIL will become increasingly crucial for enabling real-world applications that require fast and responsive predictions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CQIL: Inference Latency Optimization with Concurrent Computation of Quasi-Independent Layers
Longwei Zou, Qingyang Wang, Han Zhao, Jiangang Kong, Yi Yang, Yangdong Deng
The fast-growing large scale language models are delivering unprecedented performance on almost all natural language processing tasks. However, the effectiveness of large language models are reliant on an exponentially increasing number of parameters. The overwhelming computation complexity incurs a high inference latency that negatively affects user experience. Existing methods to improve inference efficiency, such as tensor parallelism and quantization, target to reduce per-layer computing latency, yet overlook the cumulative latency due to the number of layers. Recent works on reducing the cumulative latency through layer removing, however, lead to significant performance drop. Motivated by the similarity of inputs among adjacent layers, we propose to identify quasi-independent layers, which can be concurrently computed to significantly decrease inference latency. We also introduce a bypassing technique to mitigate the effect of information loss. Empirical experiments of the proposed approach on the LLaMA models confirm that Concurrent Computation of Quasi-Independent Layers (CQIL) can reduce latency by up to 48.3% on LLaMA-33B, while maintaining a close level of performance.
Read more7/8/2024
🛠️
0
Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Xinyuan Zhang, Jiang Liu, Zehui Xiong, Yudong Huang, Gaochang Xie, Ran Zhang
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
Read more5/14/2024
🤯
0
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
Read more4/10/2024
0
Not all Layers of LLMs are Necessary during Inference
Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, Zhongyuan Wang
Due to the large number of parameters, the inference phase of Large Language Models (LLMs) is resource-intensive. However, not all requests posed to LLMs are equally difficult to handle. Through analysis, we show that for some tasks, LLMs can achieve results comparable to the final output at some intermediate layers. That is, not all layers of LLMs are necessary during inference. If we can predict at which layer the inferred results match the final results (produced by evaluating all layers), we could significantly reduce the inference cost. To this end, we propose a simple yet effective algorithm named AdaInfer to adaptively terminate the inference process for an input instance. AdaInfer relies on easily obtainable statistical features and classic classifiers like SVM. Experiments on well-known LLMs like the Llama2 series and OPT, show that AdaInfer can achieve an average of 17.8% pruning ratio, and up to 43% on sentiment tasks, with nearly no performance drop (<1%). Because AdaInfer does not alter LLM parameters, the LLMs incorporated with AdaInfer maintain generalizability across tasks.
Read more7/10/2024