Adaptive Hyperparameter Optimization for Continual Learning Scenarios

0

Sign in to get full access
Overview
- This paper explores methods for optimizing hyperparameters in continual learning scenarios, where models are trained on a sequence of tasks.
- The authors propose a new approach called Online Continuous Hyperparameter Optimization (OCHO) that can efficiently tune hyperparameters as new tasks are encountered.
- They also investigate the impact of hyperparameter selection on the performance of continual learning models across a range of benchmark datasets.
Plain English Explanation
Continual learning is a field of machine learning that focuses on training models to adapt and learn new skills over time, without forgetting what they've already learned. This is an important capability, as it allows AI systems to keep improving and expanding their knowledge and abilities as they encounter new information.
One key challenge in continual learning is the selection of hyperparameters - the high-level settings and configurations that control how a machine learning model is trained. These hyperparameters can have a big impact on the model's performance, and they often need to be tuned carefully for each new task the model is trained on.
The researchers in this paper propose a new approach called Online Continuous Hyperparameter Optimization (OCHO) that can automatically adjust the hyperparameters as the model learns new tasks, without requiring the entire training process to be restarted. This makes the hyperparameter tuning process much more efficient and practical for real-world continual learning applications.
The authors also investigate the importance of hyperparameter selection in continual learning models across a variety of benchmark datasets. They find that the choice of hyperparameters can have a significant impact on the model's ability to learn new tasks without forgetting old ones, a key challenge in continual learning.
Overall, this research provides valuable insights into the role of hyperparameter optimization in continual learning, and offers a new technique that can help make these models more robust and adaptable as they encounter new information over time.
Technical Explanation
The paper presents a new approach called Online Continuous Hyperparameter Optimization (OCHO) for tuning hyperparameters in continual learning scenarios. OCHO uses a generalized linear model to predict the performance of the model under different hyperparameter configurations, and continuously updates this model as new tasks are encountered.
This allows OCHO to efficiently search the hyperparameter space and identify the best settings for each new task, without requiring the entire training process to be restarted. The authors show that OCHO outperforms standard hyperparameter optimization techniques, such as random search and Bayesian optimization, in terms of both final performance and sample efficiency.
The paper also investigates the impact of hyperparameter selection on the performance of continual learning models across a range of benchmark datasets. They find that the choice of hyperparameters can have a significant effect on the model's ability to learn new tasks without catastrophically forgetting old ones - a key challenge in continual learning.
The authors also discuss the importance of data-aware and parameter-aware robustness in continual learning models, and how their proposed OCHO approach can help address these issues.
Critical Analysis
The paper presents a novel and promising approach to hyperparameter optimization in continual learning, and the authors have conducted a thorough empirical evaluation to demonstrate its effectiveness. However, there are a few potential limitations and areas for further research that could be considered:
-
The experiments in the paper are limited to a relatively small number of benchmark datasets, and it would be valuable to investigate the performance of OCHO on a wider range of continual learning tasks and applications.
-
The authors do not provide a detailed analysis of the computational and memory requirements of OCHO, which could be an important consideration for real-world deployment, especially in resource-constrained environments.
-
While the paper discusses the importance of data-aware and parameter-aware robustness, it does not explore these concepts in depth or provide a comprehensive evaluation of how OCHO performs on these dimensions.
-
The paper does not address the potential for OCHO to introduce additional hyperparameters or configuration choices, which could make the overall hyperparameter optimization process more complex for practitioners.
Overall, the research presented in this paper represents a valuable contribution to the field of continual learning, and the OCHO approach shows promise as a practical solution for efficient hyperparameter tuning in these scenarios. Further research and evaluation could help to address the potential limitations and provide a more comprehensive understanding of the technique's capabilities and tradeoffs.
Conclusion
This paper introduces a novel approach called Online Continuous Hyperparameter Optimization (OCHO) for tuning hyperparameters in continual learning scenarios. The authors demonstrate that OCHO can efficiently optimize hyperparameters as new tasks are encountered, outperforming standard techniques in terms of both final performance and sample efficiency.
The paper also investigates the importance of hyperparameter selection for continual learning models, highlighting the significant impact that hyperparameter choices can have on a model's ability to learn new tasks without catastrophically forgetting old ones.
This research provides valuable insights and a practical solution for addressing one of the key challenges in continual learning - the efficient and effective tuning of hyperparameters as models adapt to new information and tasks over time. As AI systems become more complex and are required to learn and adapt in real-world environments, techniques like OCHO will be increasingly important for ensuring the robustness and reliability of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Hyperparameter Optimization for Continual Learning Scenarios
Rudy Semola, Julio Hurtado, Vincenzo Lomonaco, Davide Bacciu
Hyperparameter selection in continual learning scenarios is a challenging and underexplored aspect, especially in practical non-stationary environments. Traditional approaches, such as grid searches with held-out validation data from all tasks, are unrealistic for building accurate lifelong learning systems. This paper aims to explore the role of hyperparameter selection in continual learning and the necessity of continually and automatically tuning them according to the complexity of the task at hand. Hence, we propose leveraging the nature of sequence task learning to improve Hyperparameter Optimization efficiency. By using the functional analysis of variance-based techniques, we identify the most crucial hyperparameters that have an impact on performance. We demonstrate empirically that this approach, agnostic to continual scenarios and strategies, allows us to speed up hyperparameters optimization continually across tasks and exhibit robustness even in the face of varying sequential task orders. We believe that our findings can contribute to the advancement of continual learning methodologies towards more efficient, robust and adaptable models for real-world applications.
Read more6/21/2024

0
Hyperparameter Selection in Continual Learning
Thomas L. Lee, Sigrid Passano Hellan, Linus Ericsson, Elliot J. Crowley, Amos Storkey
In continual learning (CL) -- where a learner trains on a stream of data -- standard hyperparameter optimisation (HPO) cannot be applied, as a learner does not have access to all of the data at the same time. This has prompted the development of CL-specific HPO frameworks. The most popular way to tune hyperparameters in CL is to repeatedly train over the whole data stream with different hyperparameter settings. However, this end-of-training HPO is unrealistic as in practice a learner can only see the stream once. Hence, there is an open question: what HPO framework should a practitioner use for a CL problem in reality? This paper answers this question by evaluating several realistic HPO frameworks. We find that all the HPO frameworks considered, including end-of-training HPO, perform similarly. We therefore advocate using the realistic and most computationally efficient method: fitting the hyperparameters on the first task and then fixing them throughout training.
Read more4/10/2024
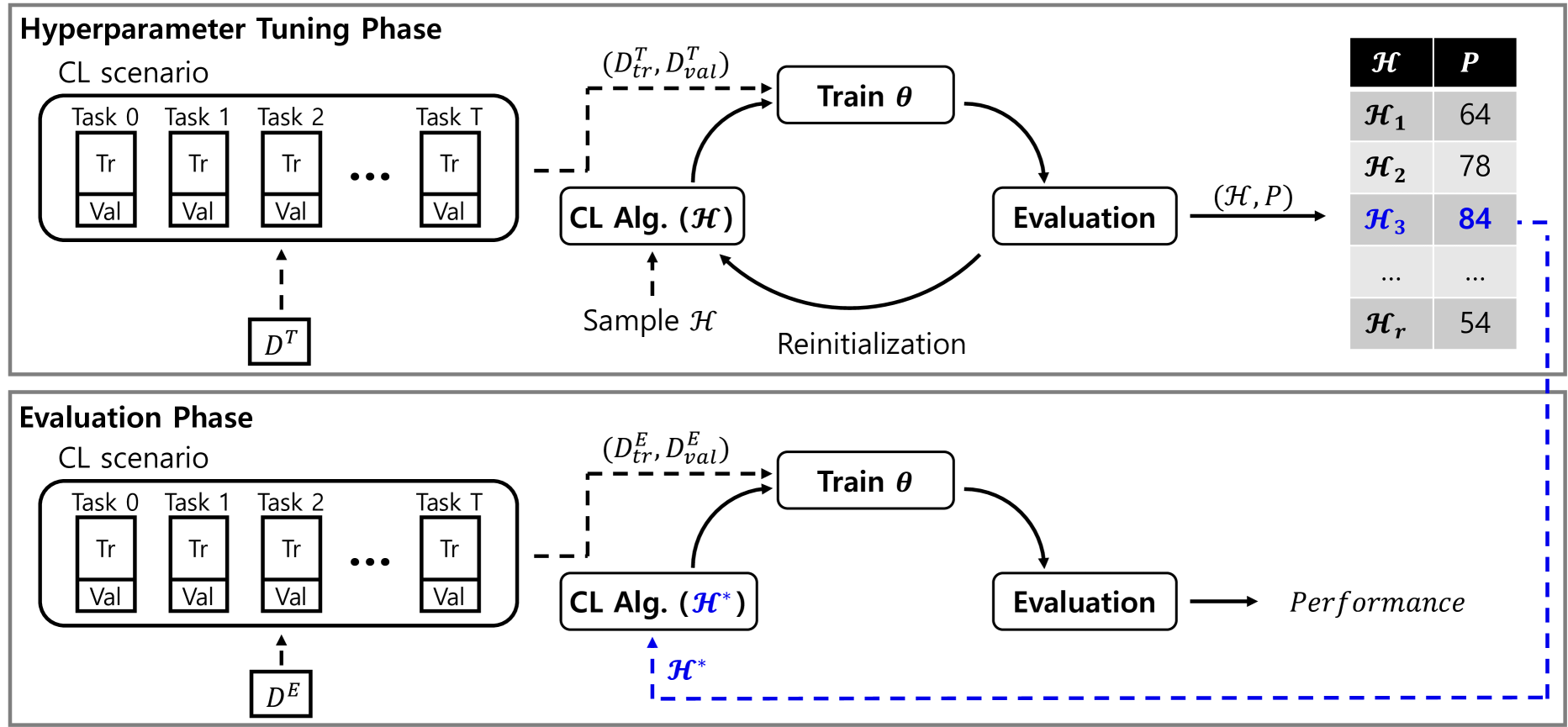
0
Hyperparameters in Continual Learning: A Reality Check
Sungmin Cha, Kyunghyun Cho
In this paper, we argue that the conventional evaluation protocol in continual learning (CL) research deviates from the fundamental principle in machine learning evaluation. The primary objective of CL algorithm is to balance the trade-off between plasticity (learning new knowledge from new tasks) and stability (retaining knowledge from previous tasks). To evaluate it, a CL scenario is constructed by using a benchmark dataset, where a neural network model is continually trained on the training data of each task, and the best hyperparameters for a CL algorithm are selected based on validation data.The final evaluation involves assessing the model trained with these hyperparameters on the test data from the same scenario. This evaluation protocol primarily aims to assess how well a CL algorithm performs on unseen data within that specific scenario. However, to accurately evaluate the CL algorithm, the focus should be on assessing generalizability of each algorithm's CL capacity to handle unseen scenarios. To achieve this evaluation goal, we propose a revised evaluation protocol. Our protocol consists of two phases: hyperparameter tuning and evaluation. Both phases share the same scenario configuration (e.g., the number of tasks) but the scenarios for each phase are generated from different datasets. During the hyperparameter tuning phase, the best hyperparameters are identified, which are then used to train the model using the CL algorithm in the evaluation phase. Finally, the result from this phase is reported as the final evaluation. We apply the proposed evaluation protocol to class-incremental learning algorithms, both with and without a pretrained model. Through extensive experiments involving approximately 5000 trials, we demonstrate that most state-of-the-art algorithms fail to exhibit the reported performance, revealing a lack of generalizability.
Read more8/19/2024

0
Adaptive Variational Continual Learning via Task-Heuristic Modelling
Fan Yang
Variational continual learning (VCL) is a turn-key learning algorithm that has state-of-the-art performance among the best continual learning models. In our work, we explore an extension of the generalized variational continual learning (GVCL) model, named AutoVCL, which combines task heuristics for informed learning and model optimization. We demonstrate that our model outperforms the standard GVCL with fixed hyperparameters, benefiting from the automatic adjustment of the hyperparameter based on the difficulty and similarity of the incoming task compared to the previous tasks.
Read more8/30/2024