Are LLMs Good Annotators for Discourse-level Event Relation Extraction?

0

Sign in to get full access
Overview
- The paper investigates whether large language models (LLMs) can effectively annotate discourse-level event relations.
- Event relation extraction is a crucial task in natural language processing, with applications in areas like summarization and question answering.
- The researchers evaluate the performance of LLMs like GPT-3 and T5 on this task, comparing their results to human annotations.
Plain English Explanation
The paper looks at whether powerful language models like GPT-3 and T5 can be used to identify relationships between events mentioned in text. Identifying event relations is an important task in natural language processing, as it can help with things like summarizing documents or answering questions about what happened.
The researchers compared the event relation annotations made by these language models to ones made by humans. This allowed them to see how well the models perform on this discourse-level task, which involves understanding the connections between events across a whole piece of text, rather than just within individual sentences.
Technical Explanation
The paper evaluates the performance of large language models (LLMs) like GPT-3 and T5 on the task of discourse-level event relation extraction. This involves identifying how events mentioned in a text are related to each other, such as one event causing another or two events occurring in sequence.
The researchers used established benchmarks like the MATRES and CARER datasets to assess the LLMs' abilities. They fine-tuned the models on the task and compared their event relation annotations to high-quality human-generated ones. Metrics like F1 score were used to quantify the models' performance.
The results showed that the LLMs can achieve reasonably good performance on this challenging task, but still lag behind human-level capabilities, especially for more complex event relations. The paper discusses potential reasons for this and suggests avenues for further improving LLM performance on discourse-level event reasoning.
Critical Analysis
The paper provides a thorough and systematic evaluation of LLM performance on discourse-level event relation extraction, which is an important limitation of current language models. The researchers acknowledge that the task is complex and challenging, and that further research is needed to close the gap with human-level performance.
One potential limitation is the use of only two main benchmark datasets, which may not fully capture the diversity of discourse-level event relations. Expanding the evaluation to a wider range of datasets could provide a more comprehensive assessment.
Additionally, the paper does not deeply explore potential reasons for the performance gap between LLMs and humans. Further analysis of the types of errors made by the models, or the role of commonsense reasoning and world knowledge, could yield useful insights.
Overall, the paper makes a valuable contribution by rigorously evaluating LLM capabilities on a crucial NLP task and highlighting areas for future improvement. Readers are encouraged to think critically about the research and consider how these findings may impact the development of more advanced language understanding systems.
Conclusion
This paper investigates the ability of large language models (LLMs) to effectively annotate discourse-level event relations, a challenging task in natural language processing. The results show that while LLMs can achieve reasonable performance, they still lag behind human-level capabilities, especially for more complex event relations.
The findings have important implications for the continued development of language models and their application in real-world tasks like summarization, question answering, and event reasoning. The paper suggests that further research is needed to close the gap between LLM and human performance on discourse-level event relation extraction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are LLMs Good Annotators for Discourse-level Event Relation Extraction?
Kangda Wei, Aayush Gautam, Ruihong Huang
Large Language Models (LLMs) have demonstrated proficiency in a wide array of natural language processing tasks. However, its effectiveness over discourse-level event relation extraction (ERE) tasks remains unexplored. In this paper, we assess the effectiveness of LLMs in addressing discourse-level ERE tasks characterized by lengthy documents and intricate relations encompassing coreference, temporal, causal, and subevent types. Evaluation is conducted using an commercial model, GPT-3.5, and an open-source model, LLaMA-2. Our study reveals a notable underperformance of LLMs compared to the baseline established through supervised learning. Although Supervised Fine-Tuning (SFT) can improve LLMs performance, it does not scale well compared to the smaller supervised baseline model. Our quantitative and qualitative analysis shows that LLMs have several weaknesses when applied for extracting event relations, including a tendency to fabricate event mentions, and failures to capture transitivity rules among relations, detect long distance relations, or comprehend contexts with dense event mentions.
Read more7/30/2024
💬
1
Improving Large Language Models in Event Relation Logical Prediction
Meiqi Chen, Yubo Ma, Kaitao Song, Yixin Cao, Yan Zhang, Dongsheng Li
Event relations are crucial for narrative understanding and reasoning. Governed by nuanced logic, event relation extraction (ERE) is a challenging task that demands thorough semantic understanding and rigorous logical reasoning. In this paper, we conduct an in-depth investigation to systematically explore the capability of LLMs in understanding and applying event relation logic. More in detail, we first investigate the deficiencies of LLMs in logical reasoning across different tasks. Our study reveals that LLMs are not logically consistent reasoners, which results in their suboptimal performance on tasks that need rigorous reasoning. To address this, we explore three different approaches to endow LLMs with event relation logic, and thus enable them to generate more coherent answers across various scenarios. Based on our approach, we also contribute a synthesized dataset (LLM-ERL) involving high-order reasoning for evaluation and fine-tuning. Extensive quantitative and qualitative analyses on different tasks also validate the effectiveness of our approaches and provide insights for solving practical tasks with LLMs in future work. Codes are available at https://github.com/chenmeiqii/Teach-LLM-LR.
Read more8/12/2024

0
LLM with Relation Classifier for Document-Level Relation Extraction
Xingzuo Li, Kehai Chen, Yunfei Long, Min Zhang
Large language models (LLMs) create a new paradigm for natural language processing. Despite their advancement, LLM-based methods still lag behind traditional approaches in document-level relation extraction (DocRE), a critical task for understanding complex entity relations. This paper investigates the causes of this performance gap, identifying the dispersion of attention by LLMs due to entity pairs without relations as a primary factor. We then introduce a novel classifier-LLM approach to DocRE. The proposed approach begins with a classifier specifically designed to select entity pair candidates exhibiting potential relations and thereby feeds them to LLM for the final relation extraction. This method ensures that during inference, the LLM's focus is directed primarily at entity pairs with relations. Experiments on DocRE benchmarks reveal that our method significantly outperforms recent LLM-based DocRE models and achieves competitive performance with several leading traditional DocRE models.
Read more8/27/2024
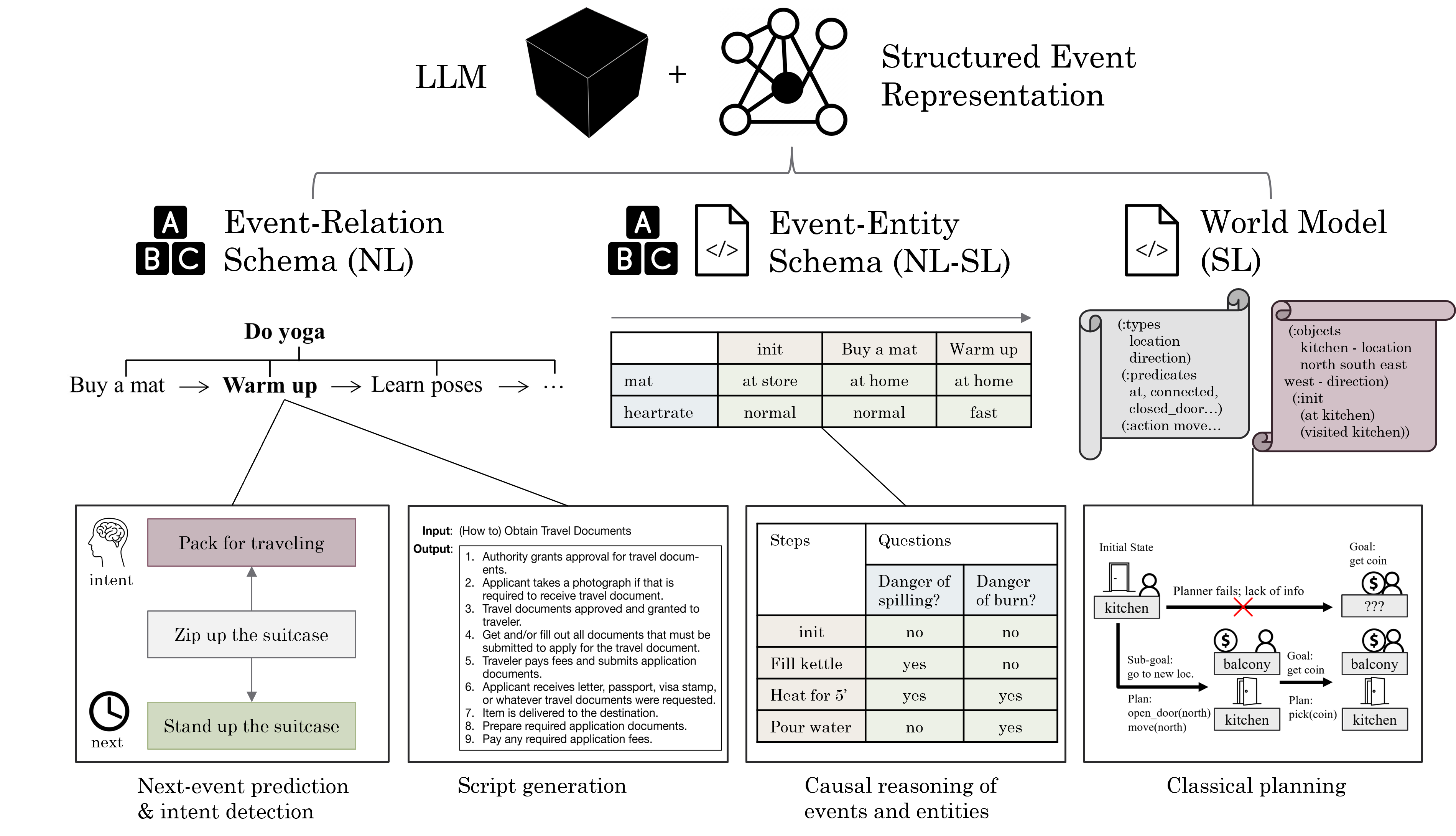
0
Structured Event Reasoning with Large Language Models
Li Zhang
Reasoning about real-life events is a unifying challenge in AI and NLP that has profound utility in a variety of domains, while fallacy in high-stake applications could be catastrophic. Able to work with diverse text in these domains, large language models (LLMs) have proven capable of answering questions and solving problems. However, I show that end-to-end LLMs still systematically fail to reason about complex events, and they lack interpretability due to their black-box nature. To address these issues, I propose three general approaches to use LLMs in conjunction with a structured representation of events. The first is a language-based representation involving relations of sub-events that can be learned by LLMs via fine-tuning. The second is a semi-symbolic representation involving states of entities that can be predicted and leveraged by LLMs via few-shot prompting. The third is a fully symbolic representation that can be predicted by LLMs trained with structured data and be executed by symbolic solvers. On a suite of event reasoning tasks spanning common-sense inference and planning, I show that each approach greatly outperforms end-to-end LLMs with more interpretability. These results suggest manners of synergy between LLMs and structured representations for event reasoning and beyond.
Read more8/30/2024