AutoEval Done Right: Using Synthetic Data for Model Evaluation

0

Sign in to get full access
Overview
- This paper introduces a new approach called "AutoEval" for evaluating machine learning models using synthetic data.
- The authors argue that traditional model evaluation methods, which rely on real-world datasets, can be problematic and propose using synthetic data as an alternative.
- The paper outlines the key benefits of the AutoEval approach and presents a framework for generating high-quality synthetic data for model evaluation.
Plain English Explanation
When it comes to evaluating the performance of machine learning models, researchers typically use real-world datasets. However, this can be challenging for a few reasons. Real-world datasets may have biases or gaps that can skew the evaluation results. Additionally, it can be difficult to obtain large, diverse datasets that are representative of the problem domain.
To address these issues, the authors of this paper propose a new approach called "AutoEval" that uses synthetic data for model evaluation. Synthetic data is artificially generated data that can be tailored to specific scenarios and test cases. By using synthetic data, researchers can have more control over the evaluation process and generate a wider range of test cases to thoroughly assess the model's performance.
The key benefits of the AutoEval approach include:
- Improved Evaluation Accuracy: Synthetic data can be designed to cover edge cases and rare events that may not be present in real-world datasets, leading to a more comprehensive evaluation of the model's capabilities.
- Increased Flexibility: Researchers can quickly generate new synthetic data to test different aspects of the model, without the limitations of working with fixed real-world datasets.
- Reduced Bias: Synthetic data can be generated to be free of the inherent biases that may be present in real-world datasets, allowing for a more unbiased evaluation.
The paper presents a framework for generating high-quality synthetic data for model evaluation, drawing on techniques from various related research in the field of synthetic data generation. The authors also discuss strategies for automating the data annotation process to further streamline the evaluation workflow.
Technical Explanation
The paper begins by highlighting the limitations of traditional model evaluation methods that rely on real-world datasets. The authors argue that these datasets can be prone to biases, gaps, and lack of diversity, which can lead to inaccurate or incomplete assessments of a model's performance.
To address these shortcomings, the authors propose the "AutoEval" approach, which leverages synthetic data for model evaluation. The paper outlines a framework for generating high-quality synthetic data that can be tailored to specific test cases and scenarios. This involves techniques such as data augmentation, adversarial data generation, and language model-based data synthesis.
The key components of the AutoEval framework include:
- Synthetic Data Generation: The authors describe methods for generating diverse and representative synthetic data, drawing on techniques from previous research in this area.
- Automated Data Annotation: To scale the evaluation process, the authors discuss approaches for automating the data annotation task, leveraging techniques like crowdsourcing and active learning.
- Comprehensive Evaluation Metrics: The paper outlines a suite of evaluation metrics that can be used to assess the model's performance, including accuracy, robustness, and fairness.
The authors present a series of experiments that demonstrate the effectiveness of the AutoEval approach compared to traditional evaluation methods. They show that the synthetic data generated by their framework can lead to more accurate and comprehensive assessments of the model's capabilities, particularly in edge cases and rare scenarios.
Critical Analysis
The paper presents a compelling case for using synthetic data in the model evaluation process, as it can address several limitations of traditional methods. However, the authors acknowledge that the generation of high-quality synthetic data is not a trivial task and can introduce its own challenges.
One potential concern is the risk of overfitting the model to the synthetic data, which could lead to overestimating its performance on real-world scenarios. The authors discuss this issue and suggest strategies, such as incorporating adversarial data generation and ensuring that the synthetic data is sufficiently diverse and representative.
Additionally, the paper does not delve deeply into the potential biases that may be introduced during the synthetic data generation process. While the authors claim that synthetic data can be designed to be free of inherent biases, it is crucial to carefully examine the assumptions and algorithms used to generate the data, as they may inadvertently encode biases.
Further research could explore the long-term implications of relying on synthetic data for model evaluation, particularly in domains where the real-world data is scarce or difficult to obtain. It would be valuable to investigate the transferability of insights gained from synthetic data evaluations to real-world performance and to develop robust methods for validating the generalizability of the synthetic data-based assessments.
Conclusion
This paper presents a novel approach called "AutoEval" that leverages synthetic data for the evaluation of machine learning models. The authors argue that traditional evaluation methods relying on real-world datasets can be problematic due to biases, gaps, and lack of diversity, and propose the use of synthetic data as a solution.
The AutoEval framework outlines a comprehensive approach for generating high-quality synthetic data, automating the data annotation process, and evaluating models using a suite of comprehensive metrics. The authors demonstrate the effectiveness of their approach through a series of experiments, showing that synthetic data can lead to more accurate and comprehensive assessments of a model's capabilities.
While the paper presents a promising solution, it also acknowledges the potential challenges and limitations of the synthetic data-based approach, such as the risk of overfitting and the need to carefully address biases in the data generation process. Further research in this area could explore the long-term implications and the transferability of insights gained from synthetic data evaluations to real-world performance.
Overall, the AutoEval approach offers a compelling alternative to traditional model evaluation methods, with the potential to drive more rigorous and comprehensive assessments of machine learning models, ultimately leading to the development of more robust and reliable systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AutoEval Done Right: Using Synthetic Data for Model Evaluation
Pierre Boyeau, Anastasios N. Angelopoulos, Nir Yosef, Jitendra Malik, Michael I. Jordan
The evaluation of machine learning models using human-labeled validation data can be expensive and time-consuming. AI-labeled synthetic data can be used to decrease the number of human annotations required for this purpose in a process called autoevaluation. We suggest efficient and statistically principled algorithms for this purpose that improve sample efficiency while remaining unbiased. These algorithms increase the effective human-labeled sample size by up to 50% on experiments with GPT-4.
Read more5/29/2024
0
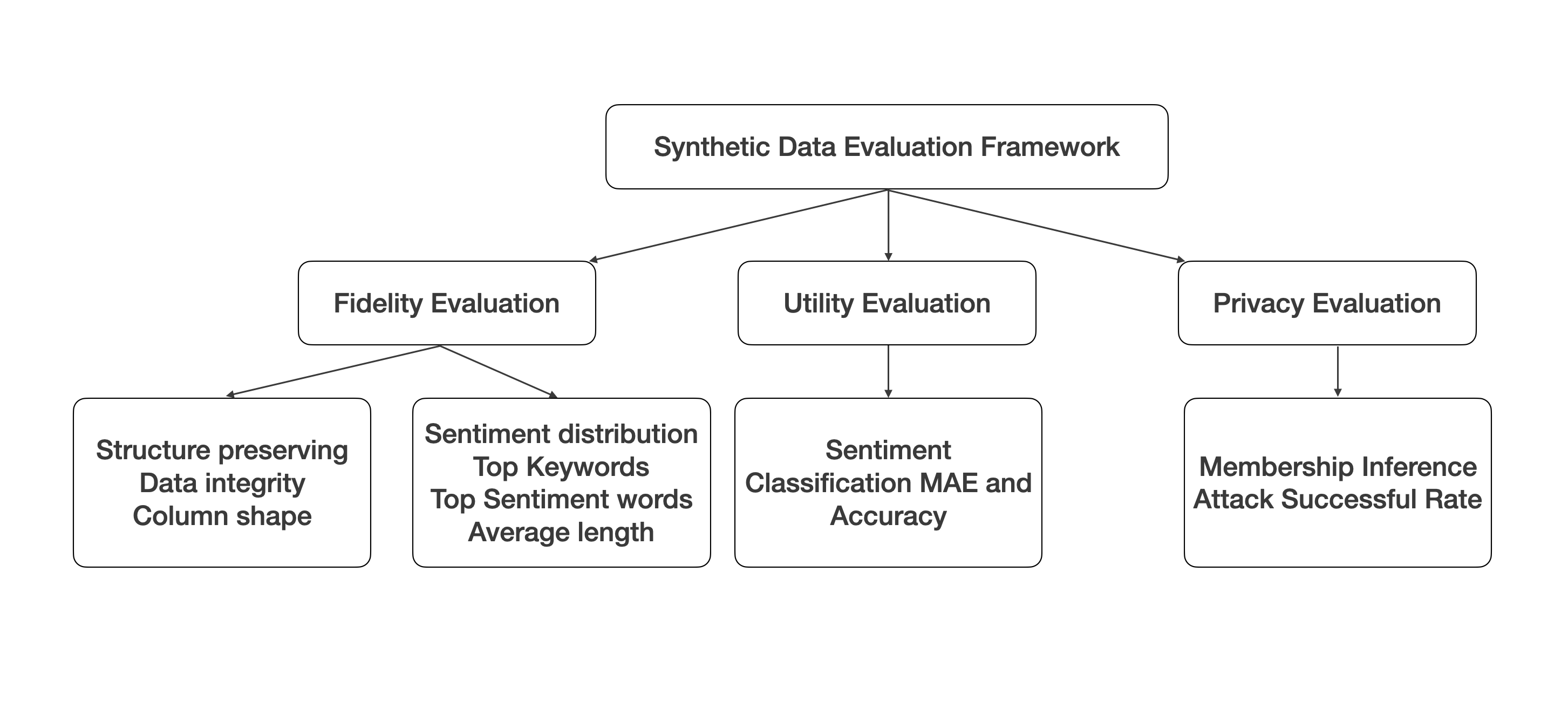
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
Read more4/24/2024

0
An Empirical Study of Validating Synthetic Data for Formula Generation
Usneek Singh, Jos'e Cambronero, Sumit Gulwani, Aditya Kanade, Anirudh Khatry, Vu Le, Mukul Singh, Gust Verbruggen
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Read more7/24/2024
0
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
Read more4/16/2024