BERGEN: A Benchmarking Library for Retrieval-Augmented Generation

0

Sign in to get full access
Overview
- This paper introduces BERGEN, a benchmarking library for evaluating retrieval-augmented generation models.
- Retrieval-augmented generation combines large language models with information retrieval systems to generate more accurate and informative content.
- BERGEN provides a suite of tasks and datasets to assess the performance of retrieval-augmented generation models across various domains, including open-domain question answering, multilingual summarization, and code generation.
Plain English Explanation
The paper introduces a new benchmarking library called BERGEN that helps researchers and developers evaluate a special type of AI model called a "retrieval-augmented generation" model. These models work by combining a large language model (like GPT-3) with an information retrieval system (like a search engine) to generate more accurate and informative content.
For example, a retrieval-augmented model could be used to answer open-ended questions by not only generating a response using its language understanding, but also retrieving relevant information from a knowledge base to include in the answer. Or it could be used to generate high-quality summaries of long documents by selectively pulling in key details from the original text.
The BERGEN library provides a set of standardized tasks and datasets that allow researchers to thoroughly test and compare the performance of different retrieval-augmented generation models across a variety of domains, including question answering, summarization, and code generation. This helps advance the field by providing a common benchmark to assess progress and identify areas for further improvement.
Technical Explanation
The paper introduces the BERGEN benchmarking library for evaluating retrieval-augmented generation models. Retrieval-augmented generation combines large language models with information retrieval systems to generate more accurate and informative content by selectively retrieving and incorporating relevant information.
BERGEN provides a suite of tasks and datasets spanning various domains, including open-domain question answering, multilingual summarization, and code generation. These benchmarks allow for comprehensive evaluation of retrieval-augmented generation models' performance in terms of accuracy, information coverage, and other relevant metrics.
The paper also introduces several novel retrieval-augmented generation techniques, such as empowering large language models to set up their own retrieval systems and a comprehensive RAG benchmark that assesses models' abilities to effectively leverage retrieved information. These methodological contributions further advance the state-of-the-art in retrieval-augmented generation.
Critical Analysis
The paper provides a thorough and well-designed benchmarking library for evaluating retrieval-augmented generation models. The authors acknowledge that the field is still relatively new, and the BERGEN suite of tasks and datasets aims to establish a common evaluation framework to drive progress.
One potential limitation is the scope of the benchmarks, which may not fully capture the wide range of real-world applications and use cases for retrieval-augmented generation. The authors note that they plan to expand the library over time to address this.
Additionally, the paper does not delve deeply into the ethical considerations or potential societal impacts of these models, such as their ability to generate convincing but potentially misleading content. As the field continues to advance, it will be important for researchers to carefully consider these issues.
Overall, the BERGEN benchmarking library represents a significant contribution to the field of retrieval-augmented generation, providing a valuable tool for researchers and developers to evaluate and improve these promising AI models.
Conclusion
This paper introduces the BERGEN benchmarking library, which provides a standardized framework for evaluating retrieval-augmented generation models. These models combine large language models with information retrieval systems to generate more accurate and informative content by selectively retrieving and incorporating relevant information.
The BERGEN library includes a suite of tasks and datasets spanning a variety of domains, enabling comprehensive assessment of retrieval-augmented generation performance. The authors also introduce novel techniques to further advance the state-of-the-art in this emerging field.
While the paper acknowledges some limitations, BERGEN represents an important step forward in establishing common benchmarks for retrieval-augmented generation. As the technology continues to evolve, this work will help drive progress and ensure these models are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BERGEN: A Benchmarking Library for Retrieval-Augmented Generation
David Rau, Herv'e D'ejean, Nadezhda Chirkova, Thibault Formal, Shuai Wang, Vassilina Nikoulina, St'ephane Clinchant
Retrieval-Augmented Generation allows to enhance Large Language Models with external knowledge. In response to the recent popularity of generative LLMs, many RAG approaches have been proposed, which involve an intricate number of different configurations such as evaluation datasets, collections, metrics, retrievers, and LLMs. Inconsistent benchmarking poses a major challenge in comparing approaches and understanding the impact of each component in the pipeline. In this work, we study best practices that lay the groundwork for a systematic evaluation of RAG and present BERGEN, an end-to-end library for reproducible research standardizing RAG experiments. In an extensive study focusing on QA, we benchmark different state-of-the-art retrievers, rerankers, and LLMs. Additionally, we analyze existing RAG metrics and datasets. Our open-source library BERGEN is available under url{https://github.com/naver/bergen}.
Read more7/2/2024

0
RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
Robert Friel, Masha Belyi, Atindriyo Sanyal
Retrieval-Augmented Generation (RAG) has become a standard architectural pattern for incorporating domain-specific knowledge into user-facing chat applications powered by Large Language Models (LLMs). RAG systems are characterized by (1) a document retriever that queries a domain-specific corpus for context information relevant to an input query, and (2) an LLM that generates a response based on the provided query and context. However, comprehensive evaluation of RAG systems remains a challenge due to the lack of unified evaluation criteria and annotated datasets. In response, we introduce RAGBench: the first comprehensive, large-scale RAG benchmark dataset of 100k examples. It covers five unique industry-specific domains and various RAG task types. RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications. Further, we formalize the TRACe evaluation framework: a set of explainable and actionable RAG evaluation metrics applicable across all RAG domains. We release the labeled dataset at https://huggingface.co/datasets/rungalileo/ragbench. RAGBench explainable labels facilitate holistic evaluation of RAG systems, enabling actionable feedback for continuous improvement of production applications. Thorough extensive benchmarking, we find that LLM-based RAG evaluation methods struggle to compete with a finetuned RoBERTa model on the RAG evaluation task. We identify areas where existing approaches fall short and propose the adoption of RAGBench with TRACe towards advancing the state of RAG evaluation systems.
Read more7/17/2024

6
LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain
Nicholas Pipitone, Ghita Houir Alami
Retrieval-Augmented Generation (RAG) systems are showing promising potential, and are becoming increasingly relevant in AI-powered legal applications. Existing benchmarks, such as LegalBench, assess the generative capabilities of Large Language Models (LLMs) in the legal domain, but there is a critical gap in evaluating the retrieval component of RAG systems. To address this, we introduce LegalBench-RAG, the first benchmark specifically designed to evaluate the retrieval step of RAG pipelines within the legal space. LegalBench-RAG emphasizes precise retrieval by focusing on extracting minimal, highly relevant text segments from legal documents. These highly relevant snippets are preferred over retrieving document IDs, or large sequences of imprecise chunks, both of which can exceed context window limitations. Long context windows cost more to process, induce higher latency, and lead LLMs to forget or hallucinate information. Additionally, precise results allow LLMs to generate citations for the end user. The LegalBench-RAG benchmark is constructed by retracing the context used in LegalBench queries back to their original locations within the legal corpus, resulting in a dataset of 6,858 query-answer pairs over a corpus of over 79M characters, entirely human-annotated by legal experts. We also introduce LegalBench-RAG-mini, a lightweight version for rapid iteration and experimentation. By providing a dedicated benchmark for legal retrieval, LegalBench-RAG serves as a critical tool for companies and researchers focused on enhancing the accuracy and performance of RAG systems in the legal domain. The LegalBench-RAG dataset is publicly available at https://github.com/zeroentropy-cc/legalbenchrag.
Read more8/21/2024
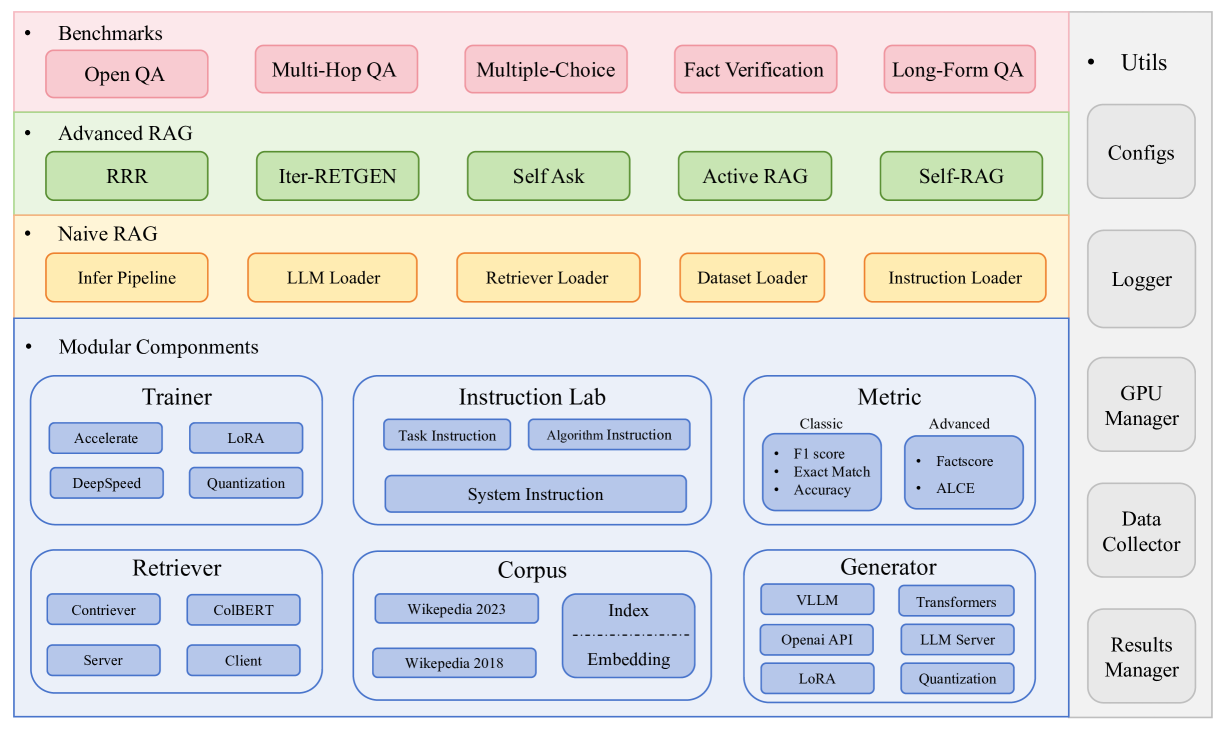
0
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Xuanwang Zhang, Yunze Song, Yidong Wang, Shuyun Tang, Xinfeng Li, Zhengran Zeng, Zhen Wu, Wei Ye, Wenyuan Xu, Yue Zhang, Xinyu Dai, Shikun Zhang, Qingsong Wen
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
Read more9/10/2024