Can LLMs Solve longer Math Word Problems Better?

0
🧠
Sign in to get full access
Overview
- This paper explores the ability of Large Language Models (LLMs) to solve long and complex math word problems, which is crucial for their real-world applications.
- The researchers introduce a new benchmark dataset called "Extended Grade-School Math" (E-GSM) that contains math word problems with lengthy narratives.
- They also propose two novel metrics to assess the performance and resilience of LLMs in solving these long and complex problems.
- The study examines the limitations of existing zero-shot prompting techniques and both proprietary and open-source LLMs in solving long math word problems.
- The researchers propose different approaches to address these challenges for proprietary and open-source LLMs, respectively.
Plain English Explanation
Math word problems are an important way to evaluate the capabilities of large language models (LLMs), which are artificial intelligence systems that can understand and generate human language. Current research has focused on math problems with short and concise contexts. However, real-world math problems often involve complex and lengthy scenarios, and it's crucial for LLMs to be able to solve these long and detailed problems for practical applications.
This study aims to explore the ability of LLMs to handle long and complex math word problems, which the researchers call "Context Length Generalizability" (CoLeG). They introduce a new dataset called "Extended Grade-School Math" (E-GSM) that contains math word problems with lengthy narratives, and they also propose new ways to measure how well LLMs can solve these problems.
The researchers find that existing LLMs, both proprietary (owned by companies) and open-source (freely available), generally struggle with solving the long and complex math word problems in the E-GSM dataset. To address this, they develop different approaches for the two types of LLMs:
For proprietary LLMs, the researchers propose a new instructional prompt that can help mitigate the influence of the long context on the LLM's performance.
For open-source LLMs, the researchers create a new data augmentation task that can improve the LLM's ability to handle long and complex math word problems.
The study's comprehensive results show that these new approaches are effective, leading to improved performance on the E-GSM dataset as well as better performance on other math word problem benchmarks. This research paves the way for future work on using LLMs for real-world, complex applications, and it offers practical solutions to current limitations in this area.
Technical Explanation
The paper introduces the concept of Context Length Generalizability (CoLeG), which refers to the ability of Large Language Models (LLMs) to solve long and complex math word problems. This is an important capability for the practical application of LLMs in real-world scenarios, where math problems often involve lengthy narratives.
To explore CoLeG, the researchers develop a new benchmark dataset called Extended Grade-School Math (E-GSM), which contains math word problems with lengthy contexts. They also propose two novel metrics to assess the efficacy and resilience of LLMs in solving these long and complex problems.
The study examines the performance of existing zero-shot prompting techniques and both proprietary and open-source LLMs on the E-GSM dataset. The results reveal a general deficiency in CoLeG, highlighting the limitations of current approaches.
To address these challenges, the researchers propose distinct strategies for proprietary and open-source LLMs. For proprietary LLMs, they introduce a new instructional prompt to mitigate the influence of long contexts. For open-source LLMs, they develop a novel data augmentation task to improve CoLeG.
The comprehensive results demonstrate the effectiveness of these proposed methods, showing not only improved performance on the E-GSM dataset but also better generalization across several other math word problem benchmarks.
Critical Analysis
The paper makes a valuable contribution to the field by addressing an important and underexplored aspect of LLM capabilities – their ability to handle long and complex math word problems. The introduction of the E-GSM dataset and the proposed evaluation metrics provide a valuable resource for the research community to further investigate CoLeG.
However, the paper does not explore the potential reasons behind the observed deficiencies in CoLeG for existing LLMs. It would be interesting to understand the specific architectural or training limitations that lead to this performance gap, as this could inform the development of more robust and generalizable LLM systems.
Additionally, the paper focuses on improving CoLeG through prompt engineering and data augmentation, but it does not explore other potential approaches, such as architectural modifications or specialized training regimes. Investigating a broader range of methods to enhance CoLeG could lead to even more effective solutions.
The GeoEval and MathIfy benchmarks could provide additional insights into the broader capabilities of LLMs in mathematical reasoning and problem-solving, which could complement the findings from this study.
Overall, this paper makes a significant contribution to the understanding and advancement of LLM capabilities in the context of long and complex math word problems, and it provides a solid foundation for future research in this area.
Conclusion
This study pioneers the exploration of Context Length Generalizability (CoLeG), the ability of Large Language Models (LLMs) to solve long and complex math word problems. By introducing the Extended Grade-School Math (E-GSM) dataset and novel evaluation metrics, the researchers uncover a general deficiency in the performance of existing LLMs on these types of problems.
To address this challenge, the paper proposes distinct approaches for proprietary and open-source LLMs, including a new instructional prompt and a data augmentation task, respectively. The comprehensive results demonstrate the effectiveness of these methods, showcasing improved performance not only on the E-GSM dataset but also on other math word problem benchmarks.
This research paves the way for future work on employing LLMs for real-world, complex applications, offering practical solutions to current limitations and opening new avenues for exploring model generalizability and training methodologies. The insights gained from this study can contribute to the development of more robust and versatile LLMs, expanding their capabilities to tackle the nuanced challenges present in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Can LLMs Solve longer Math Word Problems Better?
Xin Xu, Tong Xiao, Zitong Chao, Zhenya Huang, Can Yang, Yang Wang
Math Word Problems (MWPs) are crucial for evaluating the capability of Large Language Models (LLMs), with current research primarily focusing on questions with concise contexts. However, as real-world math problems often involve complex circumstances, LLMs' ability to solve long MWPs is vital for their applications in these scenarios, yet remains under-explored. This study pioneers the exploration of Context Length Generalizability (CoLeG), the ability of LLMs to solve long MWPs. We introduce Extended Grade-School Math (E-GSM), a collection of MWPs with lengthy narratives. Two novel metrics are proposed to assess the efficacy and resilience of LLMs in solving these problems. Our examination of existing zero-shot prompting techniques and both proprietary and open-source LLMs reveals a general deficiency in CoLeG. To alleviate these challenges, we propose distinct approaches for different categories of LLMs. For proprietary LLMs, a new instructional prompt is proposed to mitigate the influence of long context. For open-source LLMs, a new data augmentation task is developed to improve CoLeG. Our comprehensive results demonstrate the effectiveness of our proposed methods, showing not only improved performance on E-GSM but also generalizability across several other MWP benchmarks. Our findings pave the way for future research in employing LLMs for complex, real-world applications, offering practical solutions to current limitations and opening avenues for further exploration of model generalizability and training methodologies.
Read more5/24/2024

0
Investigating the Robustness of LLMs on Math Word Problems
Ujjwala Anantheswaran, Himanshu Gupta, Kevin Scaria, Shreyas Verma, Chitta Baral, Swaroop Mishra
Large Language Models (LLMs) excel at various tasks, including solving math word problems (MWPs), but struggle with real-world problems containing irrelevant information. To address this, we propose a prompting framework that generates adversarial variants of MWPs by adding irrelevant variables. We introduce a dataset, ProbleMATHIC, containing both adversarial and non-adversarial MWPs. Our experiments reveal that LLMs are susceptible to distraction by numerical noise, resulting in an average relative performance drop of ~26% on adversarial MWPs. To mitigate this, we fine-tune LLMs (Llama-2, Mistral) on the adversarial samples from our dataset. Fine-tuning on adversarial training instances improves performance on adversarial MWPs by ~8%, indicating increased robustness to noise and better ability to identify relevant data for reasoning. Finally, to assess the generalizability of our prompting framework, we introduce GSM-8K-Adv, an adversarial variant of the GSM-8K benchmark. LLMs continue to struggle when faced with adversarial information, reducing performance by up to ~6%.
Read more9/4/2024

0
Data Augmentation with In-Context Learning and Comparative Evaluation in Math Word Problem Solving
Gulsum Yigit, Mehmet Fatih Amasyali
Math Word Problem (MWP) solving presents a challenging task in Natural Language Processing (NLP). This study aims to provide MWP solvers with a more diverse training set, ultimately improving their ability to solve various math problems. We propose several methods for data augmentation by modifying the problem texts and equations, such as synonym replacement, rule-based: question replacement, and rule based: reversing question methodologies over two English MWP datasets. This study extends by introducing a new in-context learning augmentation method, employing the Llama-7b language model. This approach involves instruction-based prompting for rephrasing the math problem texts. Performance evaluations are conducted on 9 baseline models, revealing that augmentation methods outperform baseline models. Moreover, concatenating examples generated by various augmentation methods further improves performance.
Read more4/8/2024
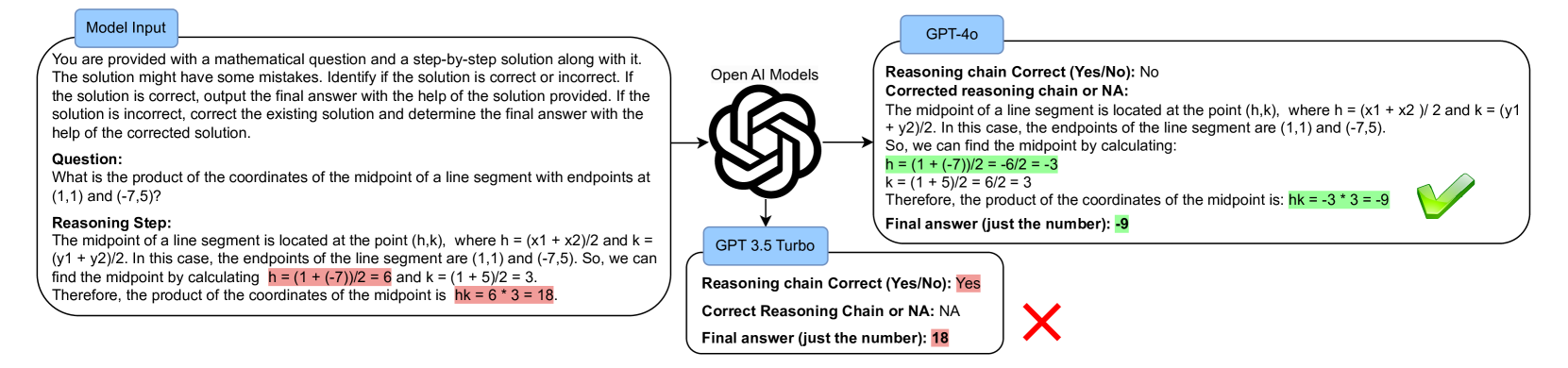
0
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
Read more6/18/2024