Defending Against Social Engineering Attacks in the Age of LLMs

0

Sign in to get full access
Overview
- The paper explores the potential for large language models (LLMs) to be manipulated to conduct social engineering attacks, known as cyber-social engineering (CSE).
- It examines the capabilities of LLMs in carrying out CSE attempts and discusses strategies for defending against such attacks.
- The research aims to raise awareness about the security implications of LLMs and provide guidance for mitigating the risks.
Plain English Explanation
The paper discusses a concerning issue related to the growing capabilities of large language models (LLMs) - the potential for these AI systems to be manipulated to carry out social engineering attacks. Social engineering attacks involve tricking people into revealing sensitive information or performing actions that compromise security.
The researchers explore how LLMs, which are trained on vast amounts of data to generate human-like text, could potentially be used by attackers to craft highly personalized and convincing messages to deceive victims. This is known as cyber-social engineering (CSE). The paper delves into the specific ways in which LLMs could be exploited to conduct these types of attacks.
Defending Against Social Engineering Attacks in the Age of LLMs is important because it raises awareness about an emerging security threat posed by the increasing sophistication of AI language models. As these models become more widely adopted, it's crucial to understand how they could be misused and develop effective strategies to protect against such attacks.
The research aims to provide guidance on defending against CSE attempts facilitated by LLMs. By understanding the potential vulnerabilities and developing appropriate safeguards, organizations and individuals can better secure themselves against this evolving threat.
Technical Explanation
The paper begins by discussing the rise of large language models (LLMs) and their growing capabilities in generating human-like text. It then examines how these powerful AI systems could potentially be manipulated to conduct cyber-social engineering (CSE) attacks.
The researchers explain that LLMs, trained on vast amounts of data, can be fine-tuned or prompted to produce highly personalized and convincing messages. Attackers could leverage this ability to craft tailor-made social engineering attempts, exploiting the target's vulnerabilities and tricking them into revealing sensitive information or performing actions that compromise security.
The paper delves into the various techniques that could be used to manipulate LLMs for CSE, such as prompt engineering, adversarial examples, and model fine-tuning. It also discusses the potential impact of language model privacy risks on the efficacy of these attacks.
The researchers propose several strategies for defending against CSE attempts facilitated by LLMs, including user education, behavioral analysis, and the development of detection and mitigation techniques. They emphasize the importance of proactively addressing this emerging security threat to protect individuals and organizations from the risks posed by the misuse of advanced language models.
Critical Analysis
The paper raises important concerns about the potential security implications of large language models and their susceptibility to exploitation for cyber-social engineering attacks. The researchers have provided a thorough analysis of the problem and have outlined several strategies for defending against such attacks.
However, one potential limitation of the research is the lack of real-world case studies or empirical data demonstrating the successful execution of CSE attempts using LLMs. While the theoretical framework and the proposed attack vectors are well-grounded, further research may be needed to fully understand the practical challenges and the effectiveness of these attacks in realistic scenarios.
Additionally, the paper does not delve deeply into the ethical considerations surrounding the development and use of LLMs. As these models become more sophisticated, there may be growing concerns about their potential misuse and the need for robust governance frameworks to ensure responsible deployment.
Overall, the paper serves as an important contribution to the ongoing discussion on the security implications of large language models. It highlights the need for proactive measures to mitigate the risks and the importance of continued research and collaboration between researchers, security practitioners, and policymakers to address this emerging threat.
Conclusion
The paper "Defending Against Social Engineering Attacks in the Age of LLMs" provides a comprehensive exploration of the potential for large language models (LLMs) to be manipulated to conduct cyber-social engineering (CSE) attacks. The researchers have highlighted the capabilities of these powerful AI systems in generating highly personalized and convincing messages, and the risks this poses for security and privacy.
The proposed strategies for defending against CSE attempts, such as user education, behavioral analysis, and the development of detection and mitigation techniques, offer a promising path forward. However, the paper also acknowledges the need for further research and the consideration of ethical implications as the adoption of LLMs continues to grow.
By raising awareness about this emerging security threat and providing guidance for mitigation, the paper contributes to the ongoing efforts to ensure the responsible development and deployment of large language models, ultimately helping to protect individuals and organizations from the risks of cyber-social engineering attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Defending Against Social Engineering Attacks in the Age of LLMs
Lin Ai, Tharindu Kumarage, Amrita Bhattacharjee, Zizhou Liu, Zheng Hui, Michael Davinroy, James Cook, Laura Cassani, Kirill Trapeznikov, Matthias Kirchner, Arslan Basharat, Anthony Hoogs, Joshua Garland, Huan Liu, Julia Hirschberg
The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
Read more6/19/2024

0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024
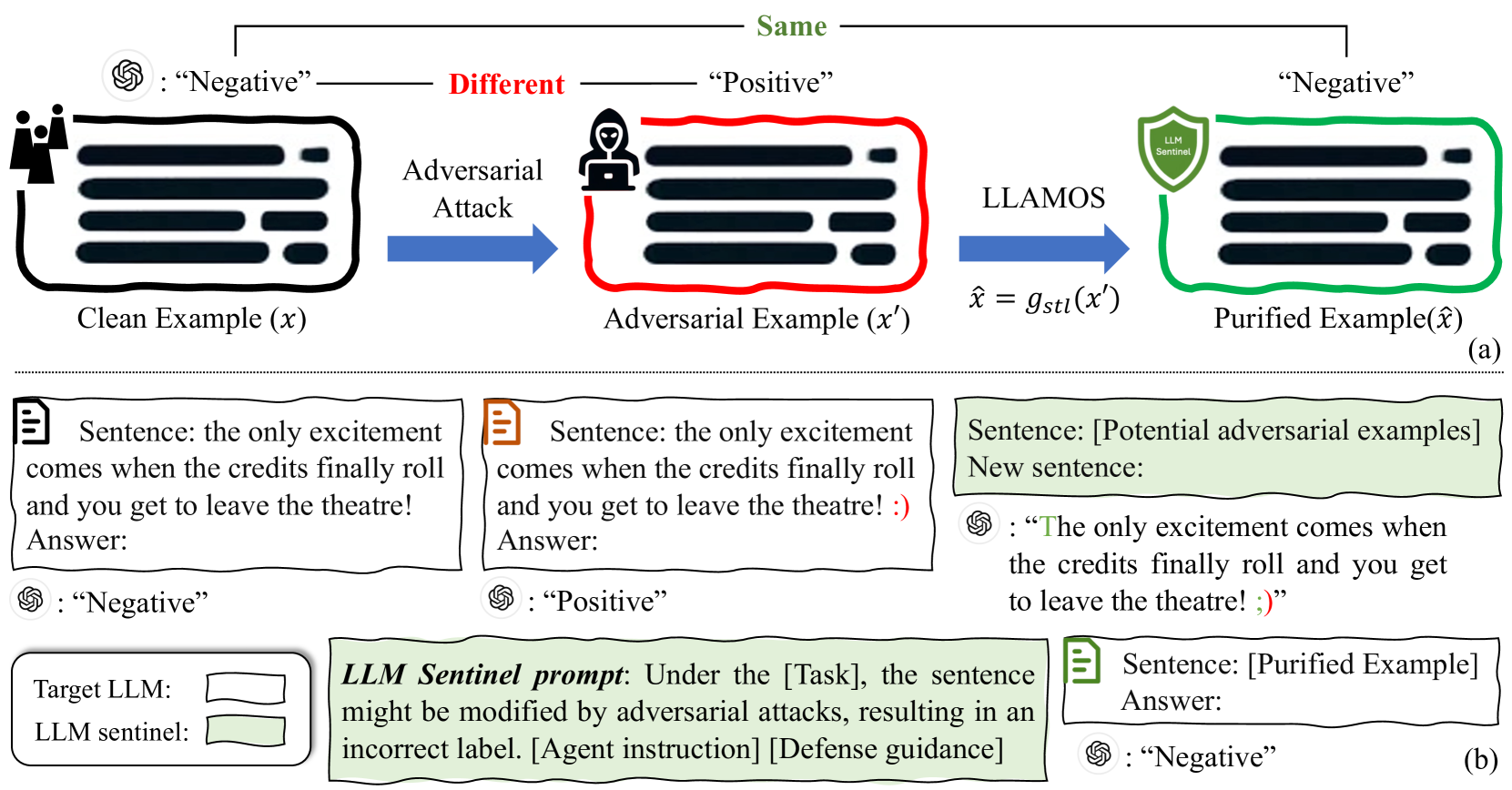
0
Large Language Model Sentinel: Advancing Adversarial Robustness by LLM Agent
Guang Lin, Qibin Zhao
Over the past two years, the use of large language models (LLMs) has advanced rapidly. While these LLMs offer considerable convenience, they also raise security concerns, as LLMs are vulnerable to adversarial attacks by some well-designed textual perturbations. In this paper, we introduce a novel defense technique named Large LAnguage MOdel Sentinel (LLAMOS), which is designed to enhance the adversarial robustness of LLMs by purifying the adversarial textual examples before feeding them into the target LLM. Our method comprises two main components: a) Agent instruction, which can simulate a new agent for adversarial defense, altering minimal characters to maintain the original meaning of the sentence while defending against attacks; b) Defense guidance, which provides strategies for modifying clean or adversarial examples to ensure effective defense and accurate outputs from the target LLMs. Remarkably, the defense agent demonstrates robust defensive capabilities even without learning from adversarial examples. Additionally, we conduct an intriguing adversarial experiment where we develop two agents, one for defense and one for attack, and engage them in mutual confrontation. During the adversarial interactions, neither agent completely beat the other. Extensive experiments on both open-source and closed-source LLMs demonstrate that our method effectively defends against adversarial attacks, thereby enhancing adversarial robustness.
Read more8/29/2024
🤿
0
The Ethics of Interaction: Mitigating Security Threats in LLMs
Ashutosh Kumar, Shiv Vignesh Murthy, Sagarika Singh, Swathy Ragupathy
This paper comprehensively explores the ethical challenges arising from security threats to Large Language Models (LLMs). These intricate digital repositories are increasingly integrated into our daily lives, making them prime targets for attacks that can compromise their training data and the confidentiality of their data sources. The paper delves into the nuanced ethical repercussions of such security threats on society and individual privacy. We scrutinize five major threats--prompt injection, jailbreaking, Personal Identifiable Information (PII) exposure, sexually explicit content, and hate-based content--going beyond mere identification to assess their critical ethical consequences and the urgency they create for robust defensive strategies. The escalating reliance on LLMs underscores the crucial need for ensuring these systems operate within the bounds of ethical norms, particularly as their misuse can lead to significant societal and individual harm. We propose conceptualizing and developing an evaluative tool tailored for LLMs, which would serve a dual purpose: guiding developers and designers in preemptive fortification of backend systems and scrutinizing the ethical dimensions of LLM chatbot responses during the testing phase. By comparing LLM responses with those expected from humans in a moral context, we aim to discern the degree to which AI behaviors align with the ethical values held by a broader society. Ultimately, this paper not only underscores the ethical troubles presented by LLMs; it also highlights a path toward cultivating trust in these systems.
Read more7/11/2024