Feature-Adaptive and Data-Scalable In-Context Learning

0

Sign in to get full access
Overview
- This paper introduces a feature-adaptive and data-scalable in-context learning approach for large language models.
- The method aims to improve the model's performance on tasks that require understanding long-range contextual information, building on previous work in context learning, hint-enhanced context learning, and label space decomposition.
- The paper also explores the trade-offs between model performance and data privacy, building on research in locally differentially private context learning.
- Additionally, the authors investigate the generalization and robustness of their approach, building on insights from previous work.
Plain English Explanation
The paper proposes a new way for large language models to learn from context, which is the information surrounding the text they are processing. The authors' approach is designed to be adaptable to different types of features in the text and able to scale to handle large amounts of data.
The key idea is to enable the model to better understand and use the long-range contextual information in the text, which can be important for many tasks. This builds on previous research that has looked at how language models can learn from context.
The paper also explores the trade-offs between the model's performance and data privacy - in other words, how to make the model work well while still protecting the privacy of the data it's trained on. And it investigates how well the model's approach generalizes to new situations and how robust it is to changes.
Overall, the paper presents a new method for large language models to learn from context in a more flexible and scalable way, with potential benefits for a range of applications.
Technical Explanation
The paper introduces a feature-adaptive and data-scalable in-context learning approach for large language models. The key elements of the method are:
-
Feature Adaptation: The model is designed to be able to adapt to different types of features in the input text, allowing it to better capture the relevant contextual information for a given task.
-
Data Scalability: The approach is able to scale to handle large amounts of training data, which is important for building high-performing language models.
-
Long-Range Context Modeling: The model is specifically aimed at improving the understanding of long-range contextual information in the text, building on previous work in context learning and hint-enhanced context learning.
-
Label Space Decomposition: The paper explores using label space decomposition techniques, as introduced in prior research, to further enhance the model's performance.
-
Privacy-Preservation: The authors investigate the trade-offs between model performance and data privacy, building on the locally differentially private context learning approach.
-
Generalization and Robustness: The paper examines the generalization and robustness of the proposed method, extending the insights from previous work.
Through extensive experiments, the authors demonstrate the effectiveness of their feature-adaptive and data-scalable in-context learning approach, highlighting its advantages over existing techniques.
Critical Analysis
The paper presents a comprehensive and technically detailed approach to improving large language models' ability to learn from context. The authors' focus on feature adaptation, data scalability, and long-range context modeling are well-justified and build on previous research in the field.
One potential limitation of the work is the trade-off between model performance and data privacy. While the authors explore this aspect, the specific implementation and its implications for real-world deployment could be an area for further investigation.
Additionally, the generalization and robustness of the proposed method, though examined in the paper, could be an important area for deeper exploration. The authors mention some insights, but there may be opportunities to further unpack the strengths and weaknesses of the approach in different settings.
Overall, the paper makes a valuable contribution to the ongoing research on enhancing language models' contextual understanding and data-efficient learning. The feature-adaptive and data-scalable in-context learning approach presented here could have significant implications for a wide range of natural language processing applications.
Conclusion
This paper introduces a novel feature-adaptive and data-scalable in-context learning method for large language models. The approach aims to improve the models' ability to understand and leverage long-range contextual information, with potential benefits for a variety of natural language processing tasks.
By addressing key challenges such as feature adaptation, data scalability, and privacy-preservation, the authors have developed a technical solution that builds on and extends previous research in the field. The critical analysis highlights some areas for further exploration, but overall, this work represents an important step forward in enhancing the contextual understanding of large language models.
As the demand for more sophisticated and capable natural language processing systems continues to grow, innovations like the one presented in this paper will be crucial for driving the field forward and unlocking new applications and possibilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Feature-Adaptive and Data-Scalable In-Context Learning
Jiahao Li, Quan Wang, Licheng Zhang, Guoqing Jin, Zhendong Mao
In-context learning (ICL), which promotes inference with several demonstrations, has become a widespread paradigm to stimulate LLM capabilities for downstream tasks. Due to context length constraints, it cannot be further improved in spite of more training data, and general features directly from LLMs in ICL are not adaptive to the specific downstream task. In this paper, we propose a feature-adaptive and data-scalable in-context learning framework (FADS-ICL), which can leverage task-adaptive features to promote inference on the downstream task, with the supervision of beyond-context samples. Specifically, it first extracts general features of beyond-context samples via the LLM with ICL input form one by one, and introduces a task-specific modulator to perform feature refinement and prediction after fitting a specific downstream task. We conduct extensive experiments on FADS-ICL under varying data settings (4$sim$128 shots) and LLM scale (0.8$sim$70B) settings. Experimental results show that FADS-ICL consistently outperforms previous state-of-the-art methods by a significant margin under all settings, verifying the effectiveness and superiority of FADS-ICL. For example, under the 1.5B and 32 shots setting, FADS-ICL can achieve textbf{+14.3} average accuracy from feature adaptation over vanilla ICL on 10 datasets, with textbf{+6.2} average accuracy over the previous state-of-the-art method, and the performance can further improve with increasing training data. Code and data are publicly available at url{https://github.com/jiahaozhenbang/FADS-ICL}.
Read more6/4/2024
👨🏫
0
Implicit In-context Learning
Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, Dimitris N. Metaxas
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of task-ids, enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
Read more5/24/2024
0
Multimodal Contrastive In-Context Learning
Yosuke Miyanishi, Minh Le Nguyen
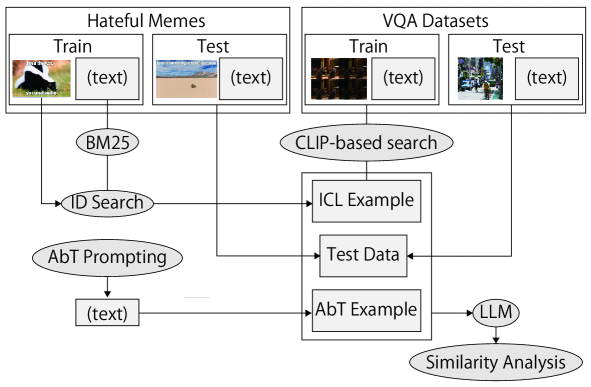
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Read more8/26/2024
0
Enhancing In-Context Learning via Implicit Demonstration Augmentation
Xiaoling Zhou, Wei Ye, Yidong Wang, Chaoya Jiang, Zhemg Lee, Rui Xie, Shikun Zhang
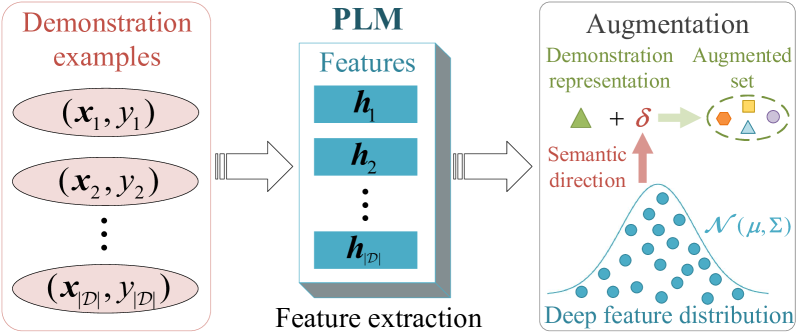
The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
Read more7/2/2024