How to Explore with Belief: State Entropy Maximization in POMDPs
2406.02295
0
0

Abstract
Recent works have studied
Create account to get full access
Overview
- Explores the concept of state entropy maximization in partially observable Markov decision processes (POMDPs) to guide exploration
- Proposes a novel algorithm called Belief State Entropy Maximization (BSEM) that aims to maximize the entropy of the agent's belief state to encourage exploration
- Demonstrates the effectiveness of BSEM on various POMDP benchmark tasks and real-world applications
Plain English Explanation
In this research, the authors investigate a way to help AI agents explore their environment more effectively when they have incomplete information about the world around them. This is a common challenge in reinforcement learning tasks, where the agent needs to learn by interacting with its environment.
The key idea is to have the agent try to maximize the entropy (or uncertainty) of its beliefs about the current state of the environment. By doing this, the agent will be encouraged to try out different actions and gather more information, rather than settling on a particular belief and exploiting that belief. This approach, called Belief State Entropy Maximization (BSEM), can be particularly useful in partially observable environments, where the agent can't directly observe the full state of the world.
The authors demonstrate the effectiveness of BSEM on various benchmark tasks and real-world applications, showing that it can help agents explore their environment more thoroughly and find better solutions to complex problems. This work has important implications for reinforcement learning and intrinsic reward systems, which aim to enable AI agents to learn and explore autonomously.
Technical Explanation
The paper proposes a novel algorithm called Belief State Entropy Maximization (BSEM) for exploration in partially observable Markov decision processes (POMDPs). The key idea is to have the agent try to maximize the entropy (or uncertainty) of its beliefs about the current state of the environment, rather than simply exploiting its current beliefs.
The authors first provide a formalization of the POMDP problem and the concept of belief state entropy. They then present the BSEM algorithm, which combines a state entropy maximization term with the standard reward maximization objective. This encourages the agent to take actions that lead to belief states with high entropy, as this indicates the agent is uncertain about the true state of the environment and should explore further.
The authors evaluate BSEM on several benchmark POMDP tasks, as well as a real-world application of a robotic navigation task. The results show that BSEM outperforms standard exploration methods, such as ε-greedy and upper confidence bound (UCB), in terms of both exploration efficiency and final task performance.
The authors also provide theoretical analysis, showing that BSEM can be interpreted as a form of intrinsic motivation for exploration, and that it has desirable properties such as encouraging the agent to visit a diverse set of belief states.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the BSEM algorithm on a range of POMDP tasks. The authors make a compelling case for the importance of effective exploration in POMDPs and provide a novel and principled approach to addressing this challenge.
One potential limitation of the work is that it focuses solely on the exploration phase of learning, and does not address the exploitation phase or the transition between the two. In real-world applications, agents may need to balance exploration and exploitation in more sophisticated ways, which is an area for further research.
Additionally, the authors mention that BSEM may be sensitive to the choice of entropy weighting hyperparameter, which could limit its practical applicability. Developing more robust or adaptive ways of setting this parameter could be an important direction for future work.
Finally, while the authors demonstrate the effectiveness of BSEM on several benchmark tasks, it would be valuable to see how it performs on larger, more complex real-world problems, where the benefits of effective exploration may be even more pronounced.
Conclusion
The Belief State Entropy Maximization (BSEM) algorithm proposed in this paper represents an important contribution to the field of reinforcement learning and exploration in partially observable environments. By encouraging agents to maximize the entropy of their belief states, BSEM can lead to more efficient and thorough exploration, which is crucial for solving complex problems in the real world.
The authors' evaluation of BSEM on benchmark tasks and a real-world application demonstrates its effectiveness, and the theoretical insights provided help to solidify the underlying principles and potential of this approach. While there are some limitations and areas for further research, this work marks a significant step forward in developing more capable and autonomous AI systems that can learn and explore in challenging, uncertain environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Limits of Pure Exploration in POMDPs: When the Observation Entropy is Enough
Riccardo Zamboni, Duilio Cirino, Marcello Restelli, Mirco Mutti
0
0
The problem of pure exploration in Markov decision processes has been cast as maximizing the entropy over the state distribution induced by the agent's policy, an objective that has been extensively studied. However, little attention has been dedicated to state entropy maximization under partial observability, despite the latter being ubiquitous in applications, e.g., finance and robotics, in which the agent only receives noisy observations of the true state governing the system's dynamics. How can we address state entropy maximization in those domains? In this paper, we study the simple approach of maximizing the entropy over observations in place of true latent states. First, we provide lower and upper bounds to the approximation of the true state entropy that only depends on some properties of the observation function. Then, we show how knowledge of the latter can be exploited to compute a principled regularization of the observation entropy to improve performance. With this work, we provide both a flexible approach to bring advances in state entropy maximization to the POMDP setting and a theoretical characterization of its intrinsic limits.
6/19/2024
🏅
Provable Representation with Efficient Planning for Partial Observable Reinforcement Learning
Hongming Zhang, Tongzheng Ren, Chenjun Xiao, Dale Schuurmans, Bo Dai
0
0
In most real-world reinforcement learning applications, state information is only partially observable, which breaks the Markov decision process assumption and leads to inferior performance for algorithms that conflate observations with state. Partially Observable Markov Decision Processes (POMDPs), on the other hand, provide a general framework that allows for partial observability to be accounted for in learning, exploration and planning, but presents significant computational and statistical challenges. To address these difficulties, we develop a representation-based perspective that leads to a coherent framework and tractable algorithmic approach for practical reinforcement learning from partial observations. We provide a theoretical analysis for justifying the statistical efficiency of the proposed algorithm, and also empirically demonstrate the proposed algorithm can surpass state-of-the-art performance with partial observations across various benchmarks, advancing reliable reinforcement learning towards more practical applications.
6/12/2024

Sound Heuristic Search Value Iteration for Undiscounted POMDPs with Reachability Objectives
Qi Heng Ho, Martin S. Feather, Federico Rossi, Zachary N. Sunberg, Morteza Lahijanian
0
0
Partially Observable Markov Decision Processes (POMDPs) are powerful models for sequential decision making under transition and observation uncertainties. This paper studies the challenging yet important problem in POMDPs known as the (indefinite-horizon) Maximal Reachability Probability Problem (MRPP), where the goal is to maximize the probability of reaching some target states. This is also a core problem in model checking with logical specifications and is naturally undiscounted (discount factor is one). Inspired by the success of point-based methods developed for discounted problems, we study their extensions to MRPP. Specifically, we focus on trial-based heuristic search value iteration techniques and present a novel algorithm that leverages the strengths of these techniques for efficient exploration of the belief space (informed search via value bounds) while addressing their drawbacks in handling loops for indefinite-horizon problems. The algorithm produces policies with two-sided bounds on optimal reachability probabilities. We prove convergence to an optimal policy from below under certain conditions. Experimental evaluations on a suite of benchmarks show that our algorithm outperforms existing methods in almost all cases in both probability guarantees and computation time.
6/6/2024
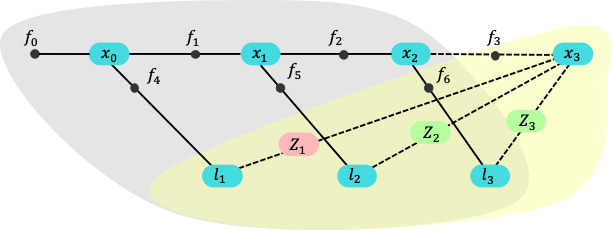
Measurement Simplification in rho-POMDP with Performance Guarantees
Tom Yotam, Vadim Indelman
0
0
Decision making under uncertainty is at the heart of any autonomous system acting with imperfect information. The cost of solving the decision making problem is exponential in the action and observation spaces, thus rendering it unfeasible for many online systems. This paper introduces a novel approach to efficient decision-making, by partitioning the high-dimensional observation space. Using the partitioned observation space, we formulate analytical bounds on the expected information-theoretic reward, for general belief distributions. These bounds are then used to plan efficiently while keeping performance guarantees. We show that the bounds are adaptive, computationally efficient, and that they converge to the original solution. We extend the partitioning paradigm and present a hierarchy of partitioned spaces that allows greater efficiency in planning. We then propose a specific variant of these bounds for Gaussian beliefs and show a theoretical performance improvement of at least a factor of 4. Finally, we compare our novel method to other state of the art algorithms in active SLAM scenarios, in simulation and in real experiments. In both cases we show a significant speed-up in planning with performance guarantees.
6/18/2024