Implicit Diffusion: Efficient Optimization through Stochastic Sampling

0

Sign in to get full access
Overview
- This paper introduces "Implicit Diffusion", a novel approach to efficient optimization through stochastic sampling.
- The key contributions include a framework for analyzing implicit diffusion models, a new algorithm for optimizing such models, and empirical demonstrations on various tasks.
- The approach aims to overcome the limitations of existing diffusion models by implicitly defining the diffusion process, leading to more efficient optimization.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that can be used for tasks like generating images or text. These models work by simulating a "diffusion" process, where a clean input (like an image) is gradually corrupted with noise over many steps. The model then learns to reverse this process, allowing it to generate new, realistic-looking outputs.
However, training diffusion models can be computationally expensive, as it requires running the diffusion process many times. The "Implicit Diffusion" approach introduced in this paper seeks to address this issue. Instead of explicitly defining the diffusion process, the model implicitly learns it, allowing for more efficient optimization.
The key idea is to treat the diffusion process as a kind of "black box" that the model can interact with, without needing to know all the details of how it works. This allows the model to learn the optimal way to reverse the diffusion process, without the overhead of simulating it in full.
The paper demonstrates that this Implicit Diffusion approach can achieve competitive performance on a variety of tasks, while being more computationally efficient than traditional diffusion models. This could lead to faster and more scalable diffusion-based applications in the future.
Technical Explanation
The paper proposes a framework for Implicit Diffusion, where the diffusion process is not explicitly defined, but rather implicitly learned by the model. This allows for more efficient optimization compared to traditional diffusion models.
The key technical contribution is a new algorithm, called Implicit Diffusion Optimization (IDO), which learns an implicit diffusion process by optimizing a variational objective. This objective encourages the model to learn a diffusion process that is efficient to reverse, leading to better sample quality and generation speed.
The paper also demonstrates how this approach can be extended to physics-informed diffusion models, where the diffusion process is constrained by physical laws or other domain-specific knowledge. This can further improve the efficiency and robustness of the diffusion-based models.
Additionally, the paper shows how Implicit Diffusion can be applied to general noisy inverse problems, where the goal is to recover a clean signal from noisy observations. By treating the noise as an implicit diffusion process, the model can learn to invert the process efficiently.
Throughout the paper, the authors draw connections to learning the infinitesimal generator of stochastic diffusion processes, which provides a theoretical foundation for the Implicit Diffusion framework.
Critical Analysis
The Implicit Diffusion approach presented in this paper addresses an important challenge in diffusion-based machine learning models: the computational overhead of simulating the full diffusion process. By implicitly learning the diffusion process, the model can optimize more efficiently, leading to faster generation and better sample quality.
However, the paper does not explore the potential limitations of this approach. For example, it's unclear how well Implicit Diffusion would scale to more complex diffusion processes, or how sensitive the performance is to the specific choice of variational objective. Additionally, the paper does not discuss potential trade-offs between the efficiency gains and the model's ability to capture the true underlying diffusion process.
Further research could investigate the robustness and generalization of Implicit Diffusion to a wider range of tasks and datasets, as well as explore alternative objective functions or architectural choices that could enhance the model's performance and stability.
Conclusion
The "Implicit Diffusion" framework introduced in this paper represents a promising advance in the field of diffusion-based machine learning models. By implicitly learning the diffusion process, the model can be optimized more efficiently, leading to faster generation and better sample quality.
The paper's technical contributions, including the Implicit Diffusion Optimization algorithm and connections to the theory of stochastic diffusion processes, provide a solid foundation for future research in this area. If further developed and refined, the Implicit Diffusion approach could have significant implications for the wider adoption and scalability of diffusion-based models in various applications, such as image and text generation, inverse problems, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Implicit Diffusion: Efficient Optimization through Stochastic Sampling
Pierre Marion, Anna Korba, Peter Bartlett, Mathieu Blondel, Valentin De Bortoli, Arnaud Doucet, Felipe Llinares-L'opez, Courtney Paquette, Quentin Berthet
We present a new algorithm to optimize distributions defined implicitly by parameterized stochastic diffusions. Doing so allows us to modify the outcome distribution of sampling processes by optimizing over their parameters. We introduce a general framework for first-order optimization of these processes, that performs jointly, in a single loop, optimization and sampling steps. This approach is inspired by recent advances in bilevel optimization and automatic implicit differentiation, leveraging the point of view of sampling as optimization over the space of probability distributions. We provide theoretical guarantees on the performance of our method, as well as experimental results demonstrating its effectiveness. We apply it to training energy-based models and finetuning denoising diffusions.
Read more5/24/2024
0
Diffusion Models as Constrained Samplers for Optimization with Unknown Constraints
Lingkai Kong, Yuanqi Du, Wenhao Mu, Kirill Neklyudov, Valentin De Bortoli, Haorui Wang, Dongxia Wu, Aaron Ferber, Yi-An Ma, Carla P. Gomes, Chao Zhang
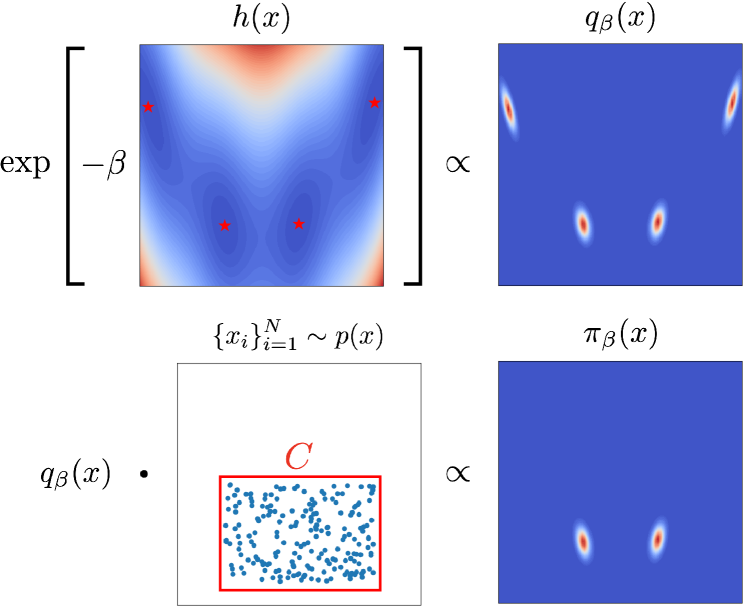
Addressing real-world optimization problems becomes particularly challenging when analytic objective functions or constraints are unavailable. While numerous studies have addressed the issue of unknown objectives, limited research has focused on scenarios where feasibility constraints are not given explicitly. Overlooking these constraints can lead to spurious solutions that are unrealistic in practice. To deal with such unknown constraints, we propose to perform optimization within the data manifold using diffusion models. To constrain the optimization process to the data manifold, we reformulate the original optimization problem as a sampling problem from the product of the Boltzmann distribution defined by the objective function and the data distribution learned by the diffusion model. To enhance sampling efficiency, we propose a two-stage framework that begins with a guided diffusion process for warm-up, followed by a Langevin dynamics stage for further correction. Theoretical analysis shows that the initial stage results in a distribution focused on feasible solutions, thereby providing a better initialization for the later stage. Comprehensive experiments on a synthetic dataset, six real-world black-box optimization datasets, and a multi-objective optimization dataset show that our method achieves better or comparable performance with previous state-of-the-art baselines.
Read more5/1/2024
🏋️
0
Improved off-policy training of diffusion samplers
Marcin Sendera, Minsu Kim, Sarthak Mittal, Pablo Lemos, Luca Scimeca, Jarrid Rector-Brooks, Alexandre Adam, Yoshua Bengio, Nikolay Malkin
We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.
Read more5/28/2024
0
A Diffusion Model Framework for Unsupervised Neural Combinatorial Optimization
Sebastian Sanokowski, Sepp Hochreiter, Sebastian Lehner
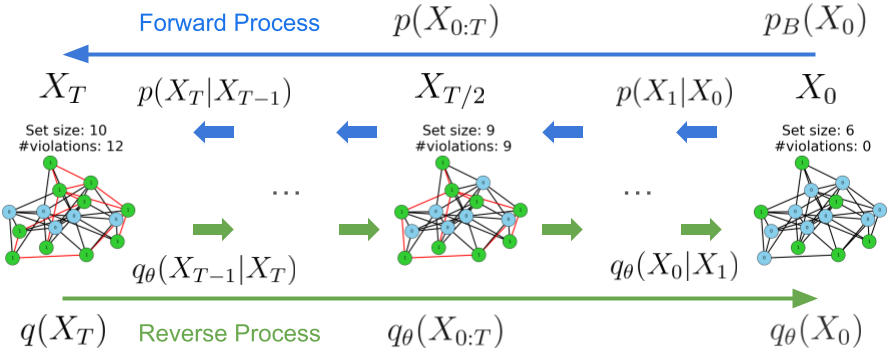
Learning to sample from intractable distributions over discrete sets without relying on corresponding training data is a central problem in a wide range of fields, including Combinatorial Optimization. Currently, popular deep learning-based approaches rely primarily on generative models that yield exact sample likelihoods. This work introduces a method that lifts this restriction and opens the possibility to employ highly expressive latent variable models like diffusion models. Our approach is conceptually based on a loss that upper bounds the reverse Kullback-Leibler divergence and evades the requirement of exact sample likelihoods. We experimentally validate our approach in data-free Combinatorial Optimization and demonstrate that our method achieves a new state-of-the-art on a wide range of benchmark problems.
Read more6/5/2024