Improved off-policy training of diffusion samplers

0
🏋️
Sign in to get full access
Overview
- The researchers studied the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function.
- They benchmarked several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks).
- The results provide insights into the relative advantages of existing algorithms and challenge some claims from past work.
- The researchers also proposed a novel exploration strategy for off-policy methods, which improved the quality of samples on a variety of target distributions.
- The code for the sampling methods and benchmarks studied is made publicly available on GitHub for future work on diffusion models for amortized inference.
Plain English Explanation
Diffusion models are a type of machine learning model that can be used to generate new data, such as images or text, by simulating a noisy process. In this research, the authors focused on the problem of training diffusion models to generate samples from a distribution with a given, but unnormalized, density or energy function. This means that the target distribution is known, but its exact shape or scale is not.
The researchers tested several different methods for training these diffusion models, including approaches that use simulation-based variational inference (Implicit Diffusion: Efficient Optimization Through Stochastic Sampling) and off-policy methods that use continuous generative flow networks (Improved Sampling via Learned Diffusions).
The results of their experiments provided new insights into the strengths and weaknesses of these different methods, challenging some claims made in previous research. Importantly, the researchers also proposed a novel exploration strategy for the off-policy methods, which involved using a replay buffer and local search in the target space. This new technique improved the quality of the generated samples across a variety of target distributions.
Overall, this research advances our understanding of how to effectively train diffusion models to generate samples from complex, unnormalized distributions, which has important applications in areas like physics-informed diffusion models and general noisy inverse problems.
Technical Explanation
The researchers benchmarked several diffusion-structured inference methods, including simulation-based variational approaches (Diffusion Models as Constrained Samplers: Optimization and Uncertainty Quantification) and off-policy methods that use continuous generative flow networks (Improved Sampling via Learned Diffusions).
For the off-policy methods, the researchers proposed a novel exploration strategy that uses a replay buffer and local search in the target space. This approach helps the model better explore the target distribution and generate higher-quality samples.
The experimental results provide insights into the relative advantages of these different algorithms. The researchers found that the simulation-based variational approaches and off-policy methods both have their own strengths and weaknesses, and that the choice of method should depend on the specific characteristics of the target distribution and the computational resources available.
The researchers also challenged some claims from past work, suggesting that the performance of these diffusion-based sampling methods may be more nuanced than previously thought. This highlights the importance of thorough benchmarking and critical analysis of new techniques in this rapidly evolving field.
Critical Analysis
The paper provides a comprehensive benchmarking of several diffusion-based sampling methods, which is valuable for advancing the state of the art in this area. However, the researchers acknowledge that their work has some limitations.
For example, the proposed exploration strategy for off-policy methods, while effective, may be computationally intensive and require careful tuning of hyperparameters. Additionally, the researchers only tested the methods on a limited set of target distributions, and it's possible that the relative performance of the algorithms could change for different types of distributions.
Furthermore, the paper does not delve deeply into the theoretical underpinnings of the diffusion-based sampling approaches, which could limit the ability to fully understand the strengths and weaknesses of each method. Exploring the theoretical foundations of diffusion models could be a fruitful area for future research.
Overall, the researchers have made a valuable contribution to the field by providing a rigorous empirical comparison of diffusion-based sampling methods and proposing a novel exploration strategy. However, there is still much more work to be done to fully understand the capabilities and limitations of these techniques, especially as they are applied to more complex real-world problems.
Conclusion
This research provides important insights into the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. The benchmarking of several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods, sheds light on the relative advantages of these algorithms.
Notably, the researchers proposed a novel exploration strategy for off-policy methods, which improved the quality of samples on a variety of target distributions. This work advances our understanding of how to effectively train diffusion models for amortized inference, with potential applications in areas like physics-informed diffusion models and general noisy inverse problems.
By making their code publicly available, the researchers have provided a valuable resource for the research community to build upon and further explore the capabilities of diffusion models for complex data generation and inference tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Improved off-policy training of diffusion samplers
Marcin Sendera, Minsu Kim, Sarthak Mittal, Pablo Lemos, Luca Scimeca, Jarrid Rector-Brooks, Alexandre Adam, Yoshua Bengio, Nikolay Malkin
We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.
Read more5/28/2024

0
Implicit Diffusion: Efficient Optimization through Stochastic Sampling
Pierre Marion, Anna Korba, Peter Bartlett, Mathieu Blondel, Valentin De Bortoli, Arnaud Doucet, Felipe Llinares-L'opez, Courtney Paquette, Quentin Berthet
We present a new algorithm to optimize distributions defined implicitly by parameterized stochastic diffusions. Doing so allows us to modify the outcome distribution of sampling processes by optimizing over their parameters. We introduce a general framework for first-order optimization of these processes, that performs jointly, in a single loop, optimization and sampling steps. This approach is inspired by recent advances in bilevel optimization and automatic implicit differentiation, leveraging the point of view of sampling as optimization over the space of probability distributions. We provide theoretical guarantees on the performance of our method, as well as experimental results demonstrating its effectiveness. We apply it to training energy-based models and finetuning denoising diffusions.
Read more5/24/2024
0
Improved sampling via learned diffusions
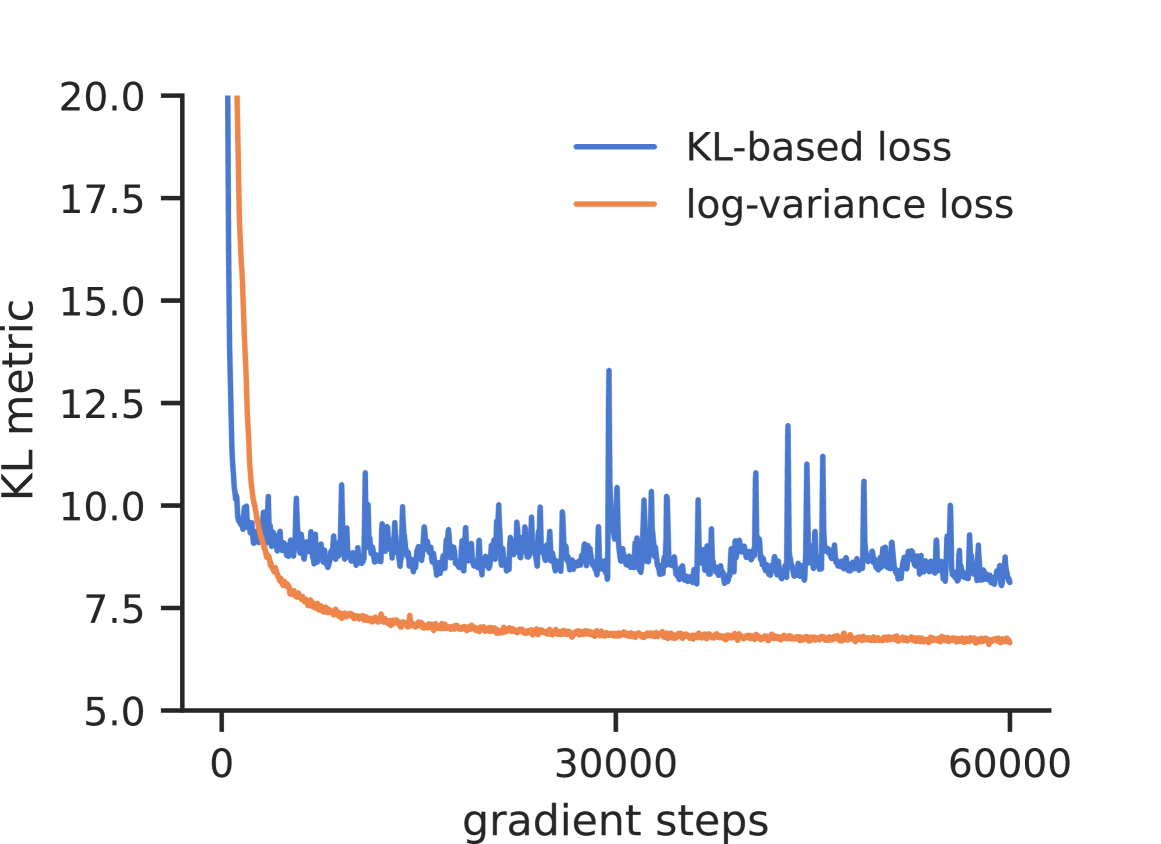
Lorenz Richter, Julius Berner
Recently, a series of papers proposed deep learning-based approaches to sample from target distributions using controlled diffusion processes, being trained only on the unnormalized target densities without access to samples. Building on previous work, we identify these approaches as special cases of a generalized Schrodinger bridge problem, seeking a stochastic evolution between a given prior distribution and the specified target. We further generalize this framework by introducing a variational formulation based on divergences between path space measures of time-reversed diffusion processes. This abstract perspective leads to practical losses that can be optimized by gradient-based algorithms and includes previous objectives as special cases. At the same time, it allows us to consider divergences other than the reverse Kullback-Leibler divergence that is known to suffer from mode collapse. In particular, we propose the so-called log-variance loss, which exhibits favorable numerical properties and leads to significantly improved performance across all considered approaches.
Read more5/24/2024
0
A Diffusion Model Framework for Unsupervised Neural Combinatorial Optimization
Sebastian Sanokowski, Sepp Hochreiter, Sebastian Lehner
Learning to sample from intractable distributions over discrete sets without relying on corresponding training data is a central problem in a wide range of fields, including Combinatorial Optimization. Currently, popular deep learning-based approaches rely primarily on generative models that yield exact sample likelihoods. This work introduces a method that lifts this restriction and opens the possibility to employ highly expressive latent variable models like diffusion models. Our approach is conceptually based on a loss that upper bounds the reverse Kullback-Leibler divergence and evades the requirement of exact sample likelihoods. We experimentally validate our approach in data-free Combinatorial Optimization and demonstrate that our method achieves a new state-of-the-art on a wide range of benchmark problems.
Read more6/5/2024