Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks
2404.08347
0
0
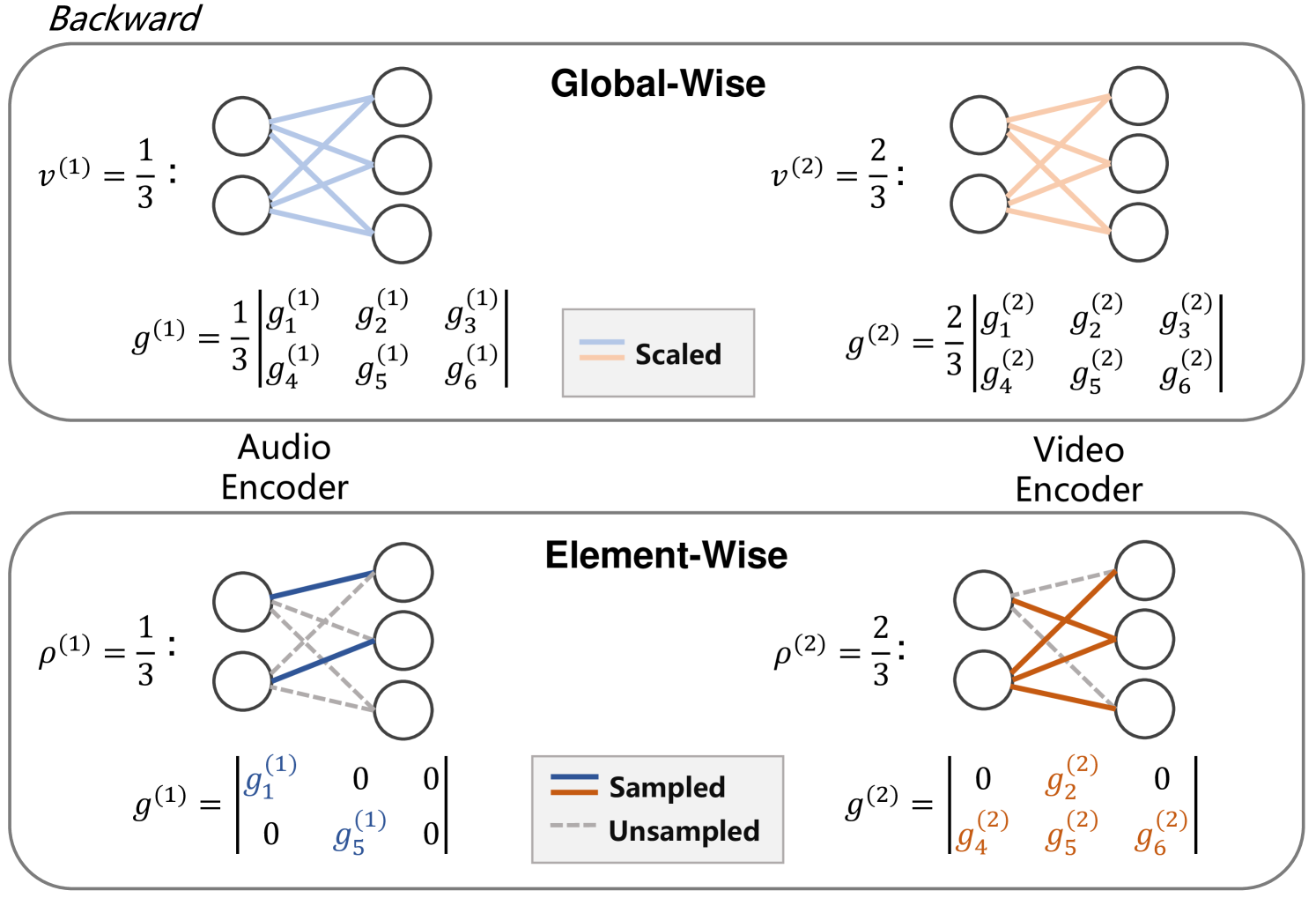
Abstract
Multi-modal learning aims to enhance performance by unifying models from various modalities but often faces the modality imbalance problem in real data, leading to a bias towards dominant modalities and neglecting others, thereby limiting its overall effectiveness. To address this challenge, the core idea is to balance the optimization of each modality to achieve a joint optimum. Existing approaches often employ a modal-level control mechanism for adjusting the update of each modal parameter. However, such a global-wise updating mechanism ignores the different importance of each parameter. Inspired by subnetwork optimization, we explore a uniform sampling-based optimization strategy and find it more effective than global-wise updating. According to the findings, we further propose a novel importance sampling-based, element-wise joint optimization method, called Adaptively Mask Subnetworks Considering Modal Significance(AMSS). Specifically, we incorporate mutual information rates to determine the modal significance and employ non-uniform adaptive sampling to select foreground subnetworks from each modality for parameter updates, thereby rebalancing multi-modal learning. Additionally, we demonstrate the reliability of the AMSS strategy through convergence analysis. Building upon theoretical insights, we further enhance the multi-modal mask subnetwork strategy using unbiased estimation, referred to as AMSS+. Extensive experiments reveal the superiority of our approach over comparison methods.
Create account to get full access
Overview
- This paper presents a new technique called "Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks" for addressing the challenge of modality imbalance in multi-modal learning.
- The method involves adaptively masking subnetworks during the training process to rebalance the contributions of different modalities and improve overall model performance.
- The authors demonstrate the effectiveness of their approach on various multi-modal benchmarks and show that it outperforms existing techniques for addressing modality imbalance.
Plain English Explanation
When training machine learning models that combine information from multiple sources (modalities), such as text, images, and audio, one common challenge is that some modalities may be more dominant or informative than others. This "modality imbalance" can lead to the model relying too heavily on the more prominent modalities and underutilizing the less informative ones, resulting in suboptimal performance.
The researchers in this paper have developed a new technique to address this issue. Their method, called "Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks," involves dynamically masking (or hiding) certain subnetworks during training. This allows the model to focus more attention on the less dominant modalities, helping to rebalance their contributions and improve the overall performance of the multi-modal system.
By adaptively adjusting the masking of subnetworks throughout the training process, the model can learn to better leverage the information from all available modalities, even if some are initially less prominent. This is an important advancement, as it helps to overcome the limitations of traditional multi-modal approaches that struggle with imbalanced data.
The researchers demonstrate the effectiveness of their approach on several multi-modal benchmarks, showing that it outperforms existing techniques for addressing modality imbalance. This suggests that their "adaptive masking" method could be a valuable tool for researchers and practitioners working on a wide range of multi-modal learning problems.
Technical Explanation
The key idea behind the "Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks" approach is to dynamically adjust the contribution of different modalities during the training process. The authors achieve this by introducing a masking mechanism that selectively hides or deactivates certain subnetworks associated with individual modalities.
The masking mechanism is implemented as a separate sub-network that learns to generate binary masks for each modality's subnetwork. These masks are then applied to the original subnetworks, effectively reducing or amplifying their contributions to the final model output. The masking sub-network is trained jointly with the main multi-modal model, allowing it to adaptively adjust the masking patterns over the course of training.
This adaptive masking approach enables the model to focus more on the less dominant modalities, helping to rebalance their contributions and improve overall performance. The authors show that this method outperforms existing techniques for addressing modality imbalance, such as Salience-Based Adaptive Masking: Revisiting Token Dynamics, Unified Multi-Modal Diagnostic Framework for Reconstruction and Pre-Training, and OMNI-SMOLA: Boosting Generalist Multimodal Models with Soft Prompts, on various multi-modal benchmarks.
Critical Analysis
The "Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks" approach presents a promising solution for addressing the challenge of modality imbalance in multi-modal learning. The authors' adaptive masking mechanism is a clever way to dynamically adjust the contributions of different modalities during training, helping to ensure that less dominant modalities are not overshadowed by more prominent ones.
However, one potential limitation of this approach is that it may be computationally expensive, as the masking sub-network adds an additional component to the overall model architecture. This could be a concern for applications with tight computational budgets or real-time requirements. Additionally, the paper does not provide a detailed analysis of the computational overhead or training time implications of the adaptive masking mechanism.
Another area that could benefit from further investigation is the interpretability and explainability of the adaptive masking process. While the authors demonstrate the effectiveness of their approach, it would be valuable to understand the specific mechanisms by which the masking sub-network learns to rebalance the modalities. This could provide insights into the model's decision-making process and potentially lead to further improvements or applications of the technique.
Finally, the paper could have explored the potential for synergies between this adaptive masking approach and other techniques for addressing modality imbalance, such as Sparse Multimodal Fusion with Modal Channel Attention or Data-Efficient Multimodal Fusion on a Single GPU. Combining complementary methods could lead to even more robust and effective solutions for multi-modal learning tasks.
Conclusion
The "Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks" paper presents a novel and promising approach for addressing the challenge of modality imbalance in multi-modal learning. By dynamically adjusting the contributions of different modalities through an adaptive masking mechanism, the authors demonstrate significant performance improvements on various benchmarks compared to existing techniques.
This work highlights the importance of developing specialized techniques to handle the unique challenges of multi-modal learning, where the relative importance and informativeness of different data sources can vary greatly. The adaptive masking approach offers a compelling solution that could have far-reaching implications for a wide range of multi-modal applications, from natural language processing to multimedia analysis and beyond.
As the field of multi-modal learning continues to evolve, this research serves as an important step forward, showcasing the potential for innovative methods to unlock the full potential of combining information from multiple modalities. By addressing the issue of modality imbalance, the authors have made a valuable contribution to the ongoing effort to build more robust and capable multi-modal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Improving Multimodal Learning with Multi-Loss Gradient Modulation
Konstantinos Kontras, Christos Chatzichristos, Matthew Blaschko, Maarten De Vos
0
0
Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
5/14/2024
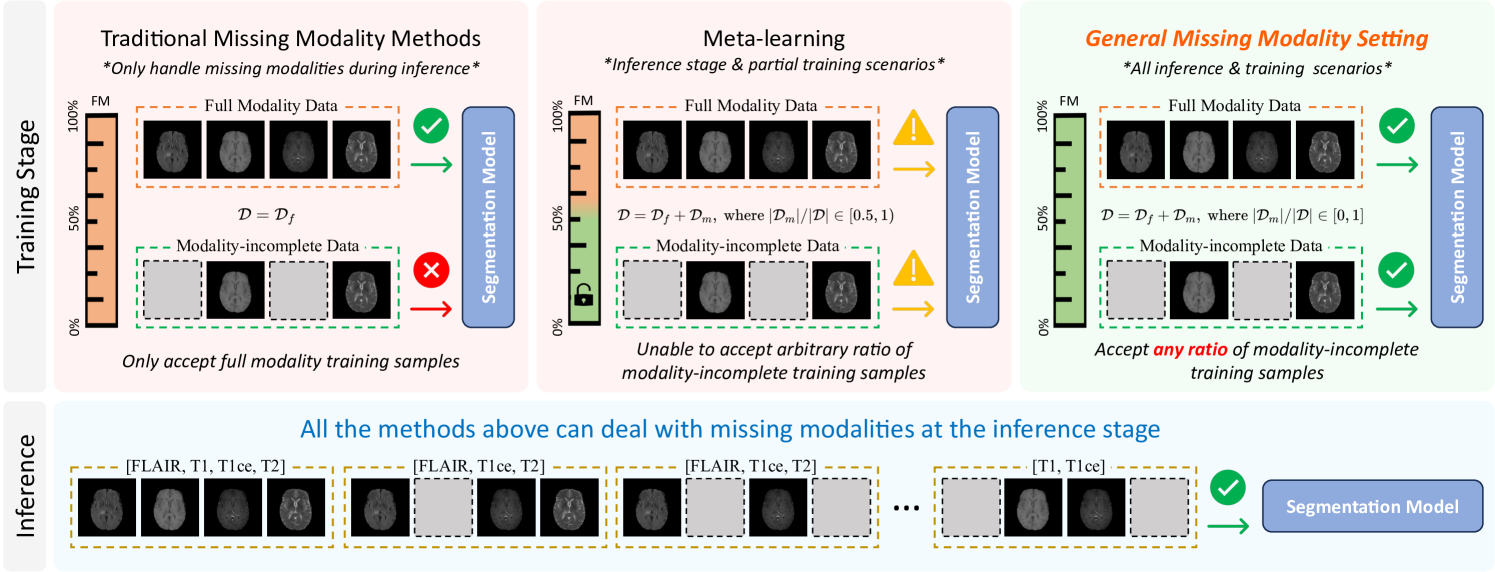
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024

Salience-Based Adaptive Masking: Revisiting Token Dynamics for Enhanced Pre-training
Hyesong Choi, Hyejin Park, Kwang Moo Yi, Sungmin Cha, Dongbo Min
0
0
In this paper, we introduce Saliency-Based Adaptive Masking (SBAM), a novel and cost-effective approach that significantly enhances the pre-training performance of Masked Image Modeling (MIM) approaches by prioritizing token salience. Our method provides robustness against variations in masking ratios, effectively mitigating the performance instability issues common in existing methods. This relaxes the sensitivity of MIM-based pre-training to masking ratios, which in turn allows us to propose an adaptive strategy for `tailored' masking ratios for each data sample, which no existing method can provide. Toward this goal, we propose an Adaptive Masking Ratio (AMR) strategy that dynamically adjusts the proportion of masking for the unique content of each image based on token salience. We show that our method significantly improves over the state-of-the-art in mask-based pre-training on the ImageNet-1K dataset.
4/15/2024
Quantifying and Enhancing Multi-modal Robustness with Modality Preference
Zequn Yang, Yake Wei, Ce Liang, Di Hu
0
0
Multi-modal models have shown a promising capability to effectively integrate information from various sources, yet meanwhile, they are found vulnerable to pervasive perturbations, such as uni-modal attacks and missing conditions. To counter these perturbations, robust multi-modal representations are highly expected, which are positioned well away from the discriminative multi-modal decision boundary. In this paper, different from conventional empirical studies, we focus on a commonly used joint multi-modal framework and theoretically discover that larger uni-modal representation margins and more reliable integration for modalities are essential components for achieving higher robustness. This discovery can further explain the limitation of multi-modal robustness and the phenomenon that multi-modal models are often vulnerable to attacks on the specific modality. Moreover, our analysis reveals how the widespread issue, that the model has different preferences for modalities, limits the multi-modal robustness by influencing the essential components and could lead to attacks on the specific modality highly effective. Inspired by our theoretical finding, we introduce a training procedure called Certifiable Robust Multi-modal Training (CRMT), which can alleviate this influence from modality preference and explicitly regulate essential components to significantly improve robustness in a certifiable manner. Our method demonstrates substantial improvements in performance and robustness compared with existing methods. Furthermore, our training procedure can be easily extended to enhance other robust training strategies, highlighting its credibility and flexibility.
4/19/2024