LitSumm: Large language models for literature summarisation of non-coding RNAs

0
💬
Sign in to get full access
Overview
- Growing challenge of curating scientific literature in life sciences due to rapid publication growth and limited curator resources
- This study aims to generate high-quality, factually accurate summaries of literature on non-coding RNAs using large language models (LLMs)
- Automated summaries were assessed to be of high quality, though traditional evaluation metrics did not correlate with human assessment
- Summaries were generated for over 4,600 non-coding RNAs and made available through the RNAcentral resource
Plain English Explanation
The number of scientific publications in the life sciences is growing rapidly, but the number of people available to carefully read and summarize this literature (known as "curators") has remained relatively fixed. This presents a major challenge for the developers of biomedical knowledge databases, as they struggle to keep up with the flood of new information.
In this study, the researchers took a step towards addressing this problem by using large language models (LLMs) - advanced AI systems trained on vast amounts of text data - to automatically generate summaries of the scientific literature on non-coding RNAs. Non-coding RNAs are a class of RNA molecules that do not encode proteins, but instead perform various regulatory functions in cells.
The researchers found that by carefully designing prompts and checks, they were able to generate high-quality, factually accurate summaries with proper citations. When a subset of the summaries was manually evaluated, the majority were rated as extremely high quality.
Interestingly, the researchers also found that the commonly used automated evaluation approaches for summarization did not accurately reflect the human assessment of quality. This highlights the limitations of current automated metrics and the need for more sophisticated evaluation techniques.
Finally, the researchers applied their tool to generate summaries for over 4,600 non-coding RNAs and made these available through the RNAcentral resource, a database of non-coding RNA sequences. This demonstrates the potential for automated literature summarization to significantly enhance the curation and dissemination of scientific knowledge, especially in fields with rapidly growing literature.
Technical Explanation
The researchers in this study aimed to address the growing challenge of curating scientific literature in the life sciences. With the continued increase in the rate of publication, coupled with the relatively fixed number of curators worldwide, developers of biomedical knowledge databases are struggling to keep up.
To tackle this problem, the researchers explored the use of large language models (LLMs) to automatically generate summaries of the scientific literature on non-coding RNAs. They carefully designed a chain of prompts and checks to ensure the generated summaries were of high quality and factually accurate, with proper citations.
The researchers evaluated the quality of the automatically generated summaries in two ways. First, they conducted a manual assessment of a subset of the summaries, finding that the majority were rated as extremely high quality. Second, they applied the most commonly used automated evaluation approaches, but found that these metrics did not correlate with the human assessment of quality.
This discrepancy between human and automated evaluation highlights the limitations of current summarization evaluation techniques and the need for more sophisticated approaches. The researchers suggest that careful prompting and automated checking are essential for producing high-quality summaries using LLMs.
Finally, the researchers applied their tool to generate summaries for over 4,600 non-coding RNAs and made these summaries available through the RNAcentral resource. This demonstrates the potential for automated literature summarization to significantly enhance the curation and dissemination of scientific knowledge, particularly in fields with rapidly growing literature.
Critical Analysis
The researchers in this study have taken an important step towards addressing the growing challenge of curating scientific literature in the life sciences. By leveraging the power of large language models, they have shown that it is possible to generate high-quality, factually accurate summaries of the literature on non-coding RNAs.
However, the researchers also acknowledge several limitations and areas for further research. One key limitation is the discrepancy between human and automated evaluation of the generated summaries, which suggests that current summarization evaluation metrics may not be sufficient. The researchers indicate that more sophisticated evaluation approaches are needed to accurately assess the quality of automatically generated summaries.
Additionally, the researchers focused on a specific domain (non-coding RNAs) and used a commercial LLM, which may limit the generalizability of their findings. It would be valuable to explore the performance of their approach on other biomedical domains and with different LLM architectures to better understand the broader applicability of the technique.
Furthermore, the researchers did not provide a detailed analysis of the types of errors or biases present in the automatically generated summaries. Understanding the common pitfalls and limitations of the current approach would help guide future improvements and refinements.
Overall, this study represents an important step forward in the quest to automate the curation of scientific literature, but there is still significant work to be done to fully realize the potential of this technology. Continued research, innovation, and careful evaluation will be necessary to create reliable and robust summarization systems that can truly alleviate the burden on human curators.
Conclusion
This study has demonstrated the feasibility of using large language models to automatically generate high-quality, factually accurate summaries of scientific literature on non-coding RNAs. By carefully designing prompts and checks, the researchers were able to produce summaries that were rated extremely high quality by human evaluators, despite the limitations of current automated evaluation metrics.
The researchers' approach has the potential to significantly enhance the curation and dissemination of scientific knowledge, particularly in fields with rapidly growing literature like the life sciences. By making the generated summaries available through the RNAcentral resource, the researchers have taken an important step towards increasing the accessibility and usability of this valuable information.
However, the study also highlights the need for continued research and innovation in the field of automated literature summarization. Improving evaluation techniques, exploring the performance on a broader range of domains, and understanding the limitations of the current approach will be crucial for further developing this technology and realizing its full potential in supporting scientific discovery and knowledge management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
LitSumm: Large language models for literature summarisation of non-coding RNAs
Andrew Green, Carlos Ribas, Nancy Ontiveros-Palacios, Sam Griffiths-Jones, Anton I. Petrov, Alex Bateman, Blake Sweeney
Motivation: Curation of literature in life sciences is a growing challenge. The continued increase in the rate of publication, coupled with the relatively fixed number of curators worldwide presents a major challenge to developers of biomedical knowledgebases. Very few knowledgebases have resources to scale to the whole relevant literature and all have to prioritise their efforts. Results: In this work, we take a first step to alleviating the lack of curator time in RNA science by generating summaries of literature for non-coding RNAs using large language models (LLMs). We demonstrate that high-quality, factually accurate summaries with accurate references can be automatically generated from the literature using a commercial LLM and a chain of prompts and checks. Manual assessment was carried out for a subset of summaries, with the majority being rated extremely high quality. We also applied the most commonly used automated evaluation approaches, finding that they do not correlate with human assessment. Finally, we apply our tool to a selection of over 4,600 ncRNAs and make the generated summaries available via the RNAcentral resource. We conclude that automated literature summarization is feasible with the current generation of LLMs, provided careful prompting and automated checking are applied. Availability: Code used to produce these summaries can be found here: https://github.com/RNAcentral/litscan-summarization and the dataset of contexts and summaries can be found here: https://huggingface.co/datasets/RNAcentral/litsumm-v1. Summaries are also displayed on the RNA report pages in RNAcentral (https://rnacentral.org/)
Read more4/22/2024
💬
0
Can Large Language Model Summarizers Adapt to Diverse Scientific Communication Goals?
Marcio Fonseca, Shay B. Cohen
In this work, we investigate the controllability of large language models (LLMs) on scientific summarization tasks. We identify key stylistic and content coverage factors that characterize different types of summaries such as paper reviews, abstracts, and lay summaries. By controlling stylistic features, we find that non-fine-tuned LLMs outperform humans in the MuP review generation task, both in terms of similarity to reference summaries and human preferences. Also, we show that we can improve the controllability of LLMs with keyword-based classifier-free guidance (CFG) while achieving lexical overlap comparable to strong fine-tuned baselines on arXiv and PubMed. However, our results also indicate that LLMs cannot consistently generate long summaries with more than 8 sentences. Furthermore, these models exhibit limited capacity to produce highly abstractive lay summaries. Although LLMs demonstrate strong generic summarization competency, sophisticated content control without costly fine-tuning remains an open problem for domain-specific applications.
Read more6/28/2024
0
WisPerMed at BioLaySumm: Adapting Autoregressive Large Language Models for Lay Summarization of Scientific Articles
Tabea M. G. Pakull, Hendrik Damm, Ahmad Idrissi-Yaghir, Henning Schafer, Peter A. Horn, Christoph M. Friedrich
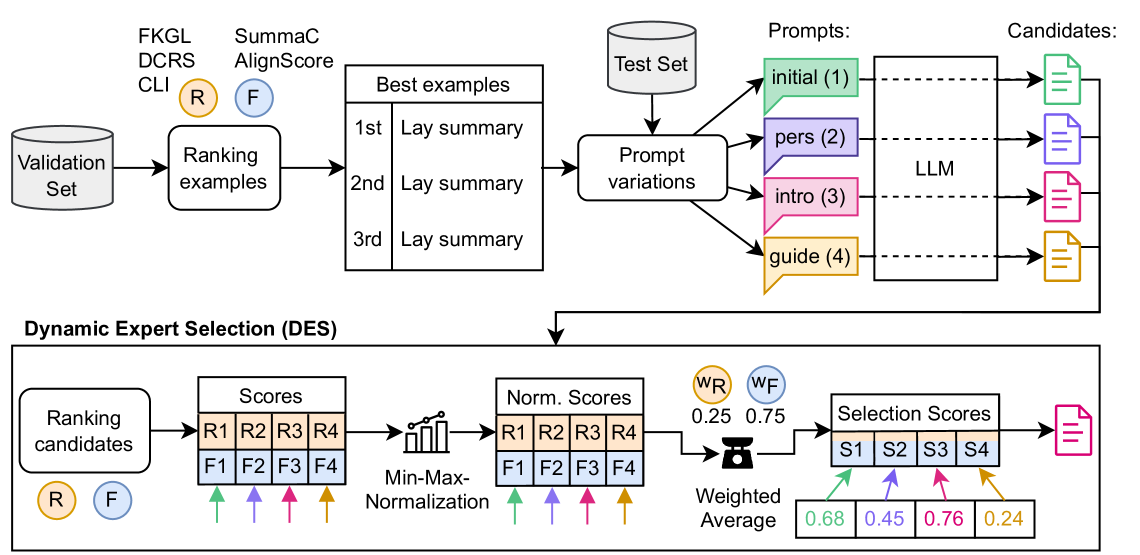
This paper details the efforts of the WisPerMed team in the BioLaySumm2024 Shared Task on automatic lay summarization in the biomedical domain, aimed at making scientific publications accessible to non-specialists. Large language models (LLMs), specifically the BioMistral and Llama3 models, were fine-tuned and employed to create lay summaries from complex scientific texts. The summarization performance was enhanced through various approaches, including instruction tuning, few-shot learning, and prompt variations tailored to incorporate specific context information. The experiments demonstrated that fine-tuning generally led to the best performance across most evaluated metrics. Few-shot learning notably improved the models' ability to generate relevant and factually accurate texts, particularly when using a well-crafted prompt. Additionally, a Dynamic Expert Selection (DES) mechanism to optimize the selection of text outputs based on readability and factuality metrics was developed. Out of 54 participants, the WisPerMed team reached the 4th place, measured by readability, factuality, and relevance. Determined by the overall score, our approach improved upon the baseline by approx. 5.5 percentage points and was only approx 1.5 percentage points behind the first place.
Read more9/24/2024
0
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
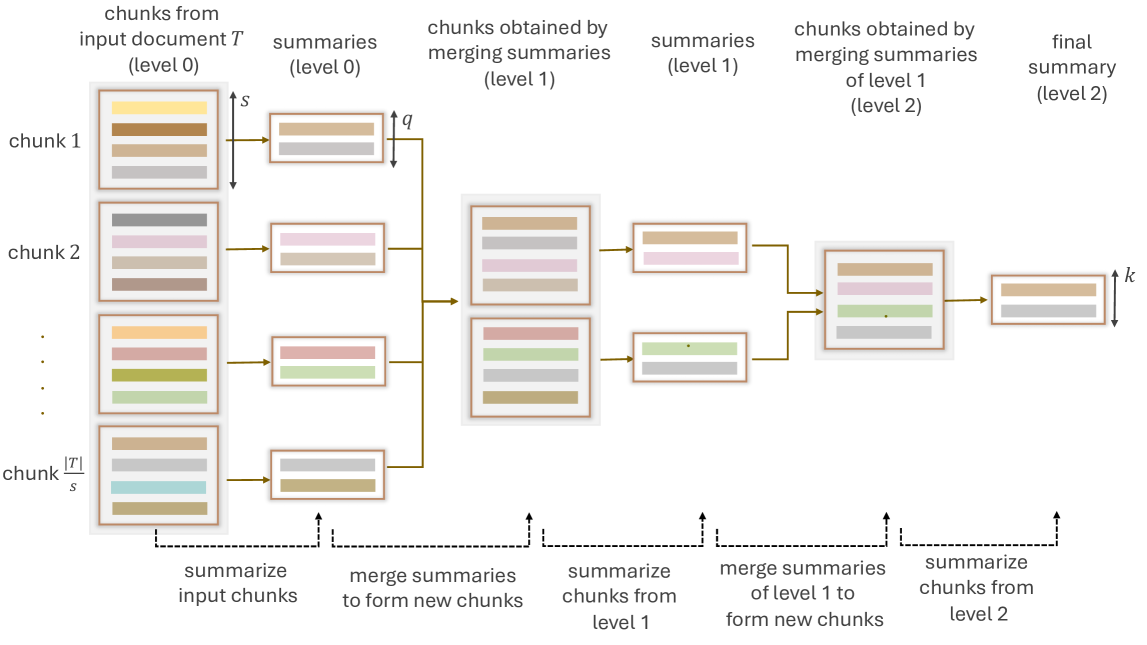
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024