LLMs are Meaning-Typed Code Constructs

0
Sign in to get full access
Overview
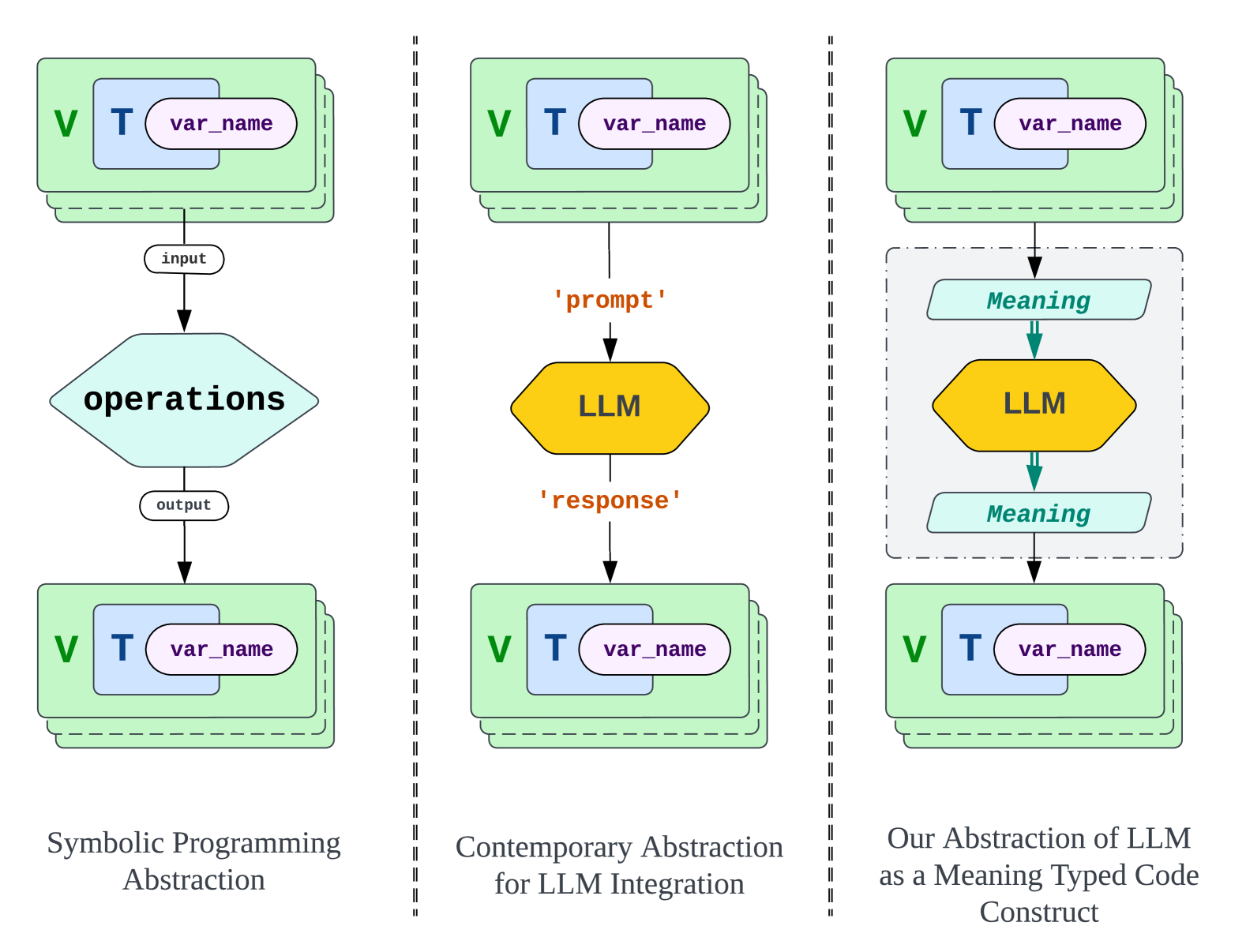
- This research paper explores the idea that large language models (LLMs) can be viewed as "meaning-typed code constructs" - essentially, code-like structures that encode semantic meaning.
- The paper suggests that LLMs possess characteristics similar to programming languages, and that understanding them through this lens could lead to new approaches in areas like AI-powered code generation and automated machine learning.
Plain English Explanation
The paper proposes that large language models, which are powerful AI systems trained on vast amounts of text data, can be thought of in a similar way to computer programming languages. Just as programming languages provide a structured way to write code that computers can execute, the authors argue that LLMs encode meaningful "code-like" information that can be harnessed for various applications.
For example, an LLM trained on a large corpus of text may have learned implicit "rules" about language, grammar, and semantics. From this perspective, the LLM's outputs could be seen as a form of "code" that expresses these learned patterns. By understanding LLMs through this lens, the researchers believe new techniques could emerge for generating code automatically or integrating LLMs with automated machine learning systems.
The key idea is that LLMs, despite being trained on unstructured text data, may actually encode meaningful "program-like" information that could be leveraged in novel ways, much like how traditional programming languages are used to build software applications.
Technical Explanation
The paper draws parallels between the structure and behavior of LLMs and traditional programming languages. It argues that LLMs can be viewed as "meaning-typed code constructs" - that is, code-like structures that encode semantic meaning, rather than just syntactic patterns.
The authors suggest that LLMs possess characteristics analogous to programming languages, such as:
- Modularity: LLMs can be composed of smaller, reusable components (e.g., individual neurons or attention heads) that perform specific functions.
- Abstraction: LLMs can learn and represent high-level concepts and relationships, similar to how programming languages enable abstraction.
- Compositionality: LLMs can combine their learned knowledge in novel ways to generate new, meaningful outputs, akin to how programming languages allow complex programs to be built from simpler building blocks.
The paper explores how this perspective on LLMs could inform new approaches to code generation and automated machine learning. For example, the authors suggest that understanding LLMs as "meaning-typed code constructs" could lead to techniques for extracting and composing LLM components to automatically generate working code.
Critical Analysis
The paper presents an intriguing new way of thinking about large language models, but it also raises some important questions and caveats:
- The analogy between LLMs and programming languages may have limitations, as LLMs are fundamentally different in their underlying architecture and training process compared to traditional programming languages.
- The paper does not provide a detailed, quantitative evaluation of the performance or practical benefits of viewing LLMs as "meaning-typed code constructs" compared to other approaches.
- The researchers acknowledge that further work is needed to fully understand the implications of this perspective and how it can be leveraged in real-world applications.
Additionally, while the paper's ideas are thought-provoking, it is important to consider potential ethical concerns around the use of LLMs, such as issues related to bias, transparency, and accountability. As these powerful AI systems become more widely adopted, it will be crucial to address such concerns.
Conclusion
This research paper presents a novel conceptual framework for understanding large language models, suggesting that they can be viewed as "meaning-typed code constructs" - code-like structures that encode semantic meaning. The authors believe this perspective could lead to new approaches in areas like AI-powered code generation and automated machine learning.
While the ideas are intriguing, the paper also acknowledges the need for further research to fully explore the implications and practical benefits of this view of LLMs. As the use of these powerful AI systems continues to grow, it will be important to address any potential ethical concerns and ensure that they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMs are Meaning-Typed Code Constructs
Jason Mars, Yiping Kang, Jayanaka Dantanarayana, Chandra Irugalbandara, Kugesan Sivasothynathan, Lingjia Tang
Programming with Generative AI (GenAI) models is a type of Neurosymbolic programming and has seen tremendous adoption across many domains. However, leveraging GenAI models in code today can be complex, counter-intuitive and often require specialized frameworks, leading to increased complexity. This is because it is currently unclear as to the right abstractions through which we should marry GenAI models with the nature of traditional programming code constructs. In this paper, we introduce a set of novel abstractions to help bridge the gap between Neuro- and symbolic programming. We introduce Meaning, a new specialized type that represents the underlying semantic value of traditional types (e.g., string). We make the case that GenAI models, LLMs in particular, should be reasoned as a meaning-type wrapped code construct at the language level. We formulate the problem of translation between meaning and traditional types and propose Automatic Meaning-Type Transformation (A-MTT), a runtime feature that abstracts this translation away from the developers by automatically converting between M eaning and types at the interface of LLM invocation. Leveraging this new set of code constructs and OTT, we demonstrate example implementation of neurosymbolic programs that seamlessly utilizes LLMs to solve problems in place of potentially complex traditional programming logic.
Read more5/16/2024

0
Logically Consistent Language Models via Neuro-Symbolic Integration
Diego Calanzone, Stefano Teso, Antonio Vergari
Large language models (LLMs) are a promising venue for natural language understanding and generation. However, current LLMs are far from reliable: they are prone to generating non-factual information and, more crucially, to contradicting themselves when prompted to reason about relations between entities of the world. These problems are currently addressed with large scale fine-tuning or by delegating reasoning to external tools. In this work, we strive for a middle ground and introduce a loss based on neuro-symbolic reasoning that teaches an LLM to be logically consistent with an external set of facts and rules and improves self-consistency even when the LLM is fine-tuned on a limited set of facts. Our approach also allows to easily combine multiple logical constraints at once in a principled way, delivering LLMs that are more consistent w.r.t. all constraints and improve over several baselines w.r.t. a given constraint. Moreover, our method allows LLMs to extrapolate to unseen but semantically similar factual knowledge, represented in unseen datasets, more systematically.
Read more9/24/2024

0
Neurosymbolic AI for Enhancing Instructability in Generative AI
Amit Sheth, Vishal Pallagani, Kaushik Roy
Generative AI, especially via Large Language Models (LLMs), has transformed content creation across text, images, and music, showcasing capabilities in following instructions through prompting, largely facilitated by instruction tuning. Instruction tuning is a supervised fine-tuning method where LLMs are trained on datasets formatted with specific tasks and corresponding instructions. This method systematically enhances the model's ability to comprehend and execute the provided directives. Despite these advancements, LLMs still face challenges in consistently interpreting complex, multi-step instructions and generalizing them to novel tasks, which are essential for broader applicability in real-world scenarios. This article explores why neurosymbolic AI offers a better path to enhance the instructability of LLMs. We explore the use a symbolic task planner to decompose high-level instructions into structured tasks, a neural semantic parser to ground these tasks into executable actions, and a neuro-symbolic executor to implement these actions while dynamically maintaining an explicit representation of state. We also seek to show that neurosymbolic approach enhances the reliability and context-awareness of task execution, enabling LLMs to dynamically interpret and respond to a wider range of instructional contexts with greater precision and flexibility.
Read more7/29/2024

0
Algorithmic Language Models with Neurally Compiled Libraries
Lucas Saldyt, Subbarao Kambhampati
Important tasks such as reasoning and planning are fundamentally algorithmic, meaning that solving them robustly requires acquiring true reasoning or planning algorithms, rather than shortcuts. Large Language Models lack true algorithmic ability primarily because of the limitations of neural network optimization algorithms, their optimization data and optimization objective, but also due to architectural inexpressivity. To solve this, our paper proposes augmenting LLMs with a library of fundamental operations and sophisticated differentiable programs, so that common algorithms do not need to be learned from scratch. We add memory, registers, basic operations, and adaptive recurrence to a transformer architecture built on LLaMA3. Then, we define a method for directly compiling algorithms into a differentiable starting library, which is used natively and propagates gradients for optimization. In this preliminary study, we explore the feasability of augmenting LLaMA3 with a differentiable computer, for instance by fine-tuning small transformers on simple algorithmic tasks with variable computational depth.
Read more7/9/2024