MAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling

0
🖼️
Sign in to get full access
Overview
- This paper presents a "map-guided" framework for few-shot audio-visual acoustics modeling, which aims to synthesize the room impulse response (RIR) in arbitrary locations with limited observations.
- The key idea is to construct acoustic-related visual semantic feature maps of the scenes to better exploit the provided few-shot data for accurate acoustic modeling.
- The framework involves generating an "observation semantic map" from the few-shot observations, and then a "scene semantic map" to capture the broader context of the environment.
- These semantic maps are then used by a transformer-based encoder-decoder to predict the RIR for any speaker-listener query pair.
Plain English Explanation
The paper addresses the challenge of few-shot audio-visual acoustics modeling, which is the task of accurately modeling the acoustics of a room, such as how sound waves bounce and travel, using only a small number of observed examples. This is important for applications like active audio-visual exploration of acoustic environments and learning spatial features from audio-visual correspondence.
The key idea is to leverage visual information about the scene, which can provide valuable cues about how sound propagates. The researchers construct "semantic feature maps" that capture the visual semantics of the environment, such as the shapes and materials of different objects. These maps provide explicit information about the structural regularities of sound propagation, which can help model the acoustics more accurately than using the limited audio observations alone.
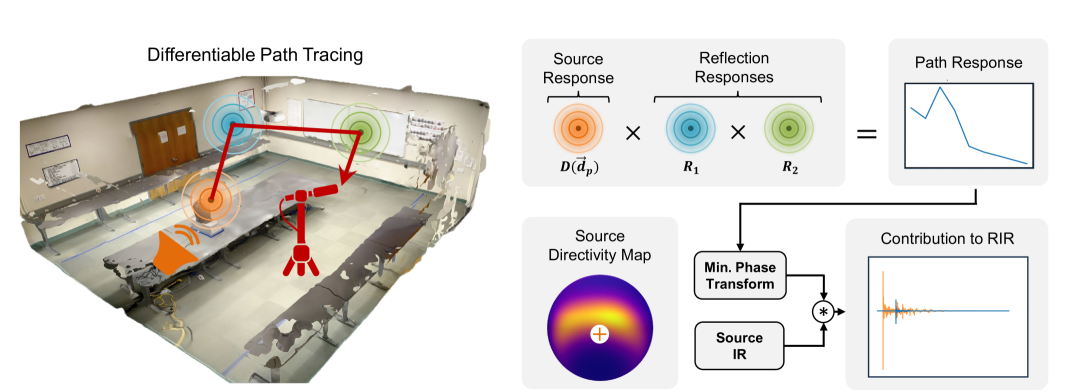
First, an "observation semantic map" is created by projecting the semantic features derived from the few-shot observations onto a top-down view of the scene. This map contains information about the relative positions of different points and the semantic features associated with them.
However, the information from the few-shot observations may not be enough to fully understand the entire scene. To address this, the researchers generate a "scene semantic map" by diffusing the features and anticipating the observation semantic map. This broader map captures the contextual information about the environment that can't be directly observed.
Finally, the scene semantic map is used by a transformer-based model to predict the room impulse response (RIR) for any given speaker-listener pair in the environment. The RIR describes how sound waves travel and interact with the surfaces in the room, which is crucial for accurately simulating audio in virtual environments.
The researchers demonstrate the effectiveness of their approach through extensive experiments on Matterport3D and Replica datasets, showing that their framework can generate accurate RIRs using only a small number of observed examples.
Technical Explanation
The key technical components of the proposed framework are:
-
Observation Semantic Map: The researchers extract pixel-wise semantic features derived from the few-shot observations and project them into a top-down map. This "observation semantic map" contains the relative positional information among points and the semantic feature information associated with each point.
-
Scene Semantic Map: Since the information extracted from the few-shot observations is limited, the researchers address this challenge by generating a "scene semantic map" via diffusing features and anticipating the observation semantic map. This broader map captures the contextual information about the environment.
-
Transformer-based Encoder-Decoder: The scene semantic map is then used by a transformer-based encoder-decoder to predict the room impulse response (RIR) for arbitrary speaker-listener query pairs. The transformer architecture allows the model to effectively capture the complex relationships between the visual semantics and the acoustic properties of the environment.
The researchers evaluate their framework on the Matterport3D and Replica datasets, demonstrating the efficacy of their approach in generating accurate RIRs using only a few-shot observations. The visual grounding provided by the semantic maps plays a crucial role in enabling the model to learn the underlying acoustic properties of the environment from limited data.
Critical Analysis
The paper presents a promising approach to few-shot audio-visual acoustics modeling, but there are a few areas that could be explored further:
-
Limitations of Semantic Maps: While the semantic maps provide valuable structural information, they may not fully capture all the nuances of sound propagation, such as the effects of surface materials, room geometry, and air turbulence. Integrating additional physical and acoustic cues could potentially improve the model's performance.
-
Generalization to Unseen Environments: The experiments in the paper were conducted on the Matterport3D and Replica datasets, which have relatively similar indoor environments. It would be important to evaluate the framework's ability to generalize to more diverse and complex environments, such as outdoor scenes or industrial spaces.
-
Real-world Deployment Challenges: The paper focuses on the technical aspects of the framework, but there may be practical challenges in deploying such a system in real-world applications, such as the availability and quality of the visual and audio data, as well as the computational resources required for inference.
-
Explainability and Interpretability: As the model becomes more complex, it's important to understand the internal workings and decision-making processes of the system. Developing techniques to improve the explainability and interpretability of the model could enhance its trustworthiness and acceptance in practical applications.
Overall, the paper presents a thoughtful and innovative approach to the challenging problem of few-shot audio-visual acoustics modeling. Further research and development in this area could lead to significant advancements in applications like virtual and augmented reality, acoustic simulation, and digital content creation.
Conclusion
The presented "map-guided" framework for few-shot audio-visual acoustics modeling offers a promising solution to the challenge of synthesizing accurate room impulse responses (RIRs) using limited observations. By leveraging visual semantic information in the form of observation and scene semantic maps, the framework can effectively capture the structural regularities of sound propagation and model the complex acoustic properties of environments.
The researchers' thorough evaluation on the Matterport3D and Replica datasets demonstrates the efficacy of their approach, highlighting the importance of visually grounded acoustic modeling for applications like active audio-visual exploration and spatial feature learning. While the paper identifies some potential areas for further research, the proposed framework represents a significant step forward in the field of few-shot audio-visual acoustics modeling, with the potential to enable more realistic and immersive virtual experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
MAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling
Diwei Huang, Kunyang Lin, Peihao Chen, Qing Du, Mingkui Tan
Few-shot audio-visual acoustics modeling seeks to synthesize the room impulse response in arbitrary locations with few-shot observations. To sufficiently exploit the provided few-shot data for accurate acoustic modeling, we present a *map-guided* framework by constructing acoustic-related visual semantic feature maps of the scenes. Visual features preserve semantic details related to sound and maps provide explicit structural regularities of sound propagation, which are valuable for modeling environment acoustics. We thus extract pixel-wise semantic features derived from observations and project them into a top-down map, namely the **observation semantic map**. This map contains the relative positional information among points and the semantic feature information associated with each point. Yet, limited information extracted by few-shot observations on the map is not sufficient for understanding and modeling the whole scene. We address the challenge by generating a **scene semantic map** via diffusing features and anticipating the observation semantic map. The scene semantic map then interacts with echo encoding by a transformer-based encoder-decoder to predict RIR for arbitrary speaker-listener query pairs. Extensive experiments on Matterport3D and Replica dataset verify the efficacy of our framework.
Read more5/24/2024
🖼️
0
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Byeongjoo Ahn, Karren Yang, Brian Hamilton, Jonathan Sheaffer, Anurag Ranjan, Miguel Sarabia, Oncel Tuzel, Jen-Hao Rick Chang
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44dB and a SDR of 14.23dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. We release our code and model on our project website at https://github.com/apple/ml-nvas3d. Please wear headphones when listening to the results.
Read more8/19/2024
0
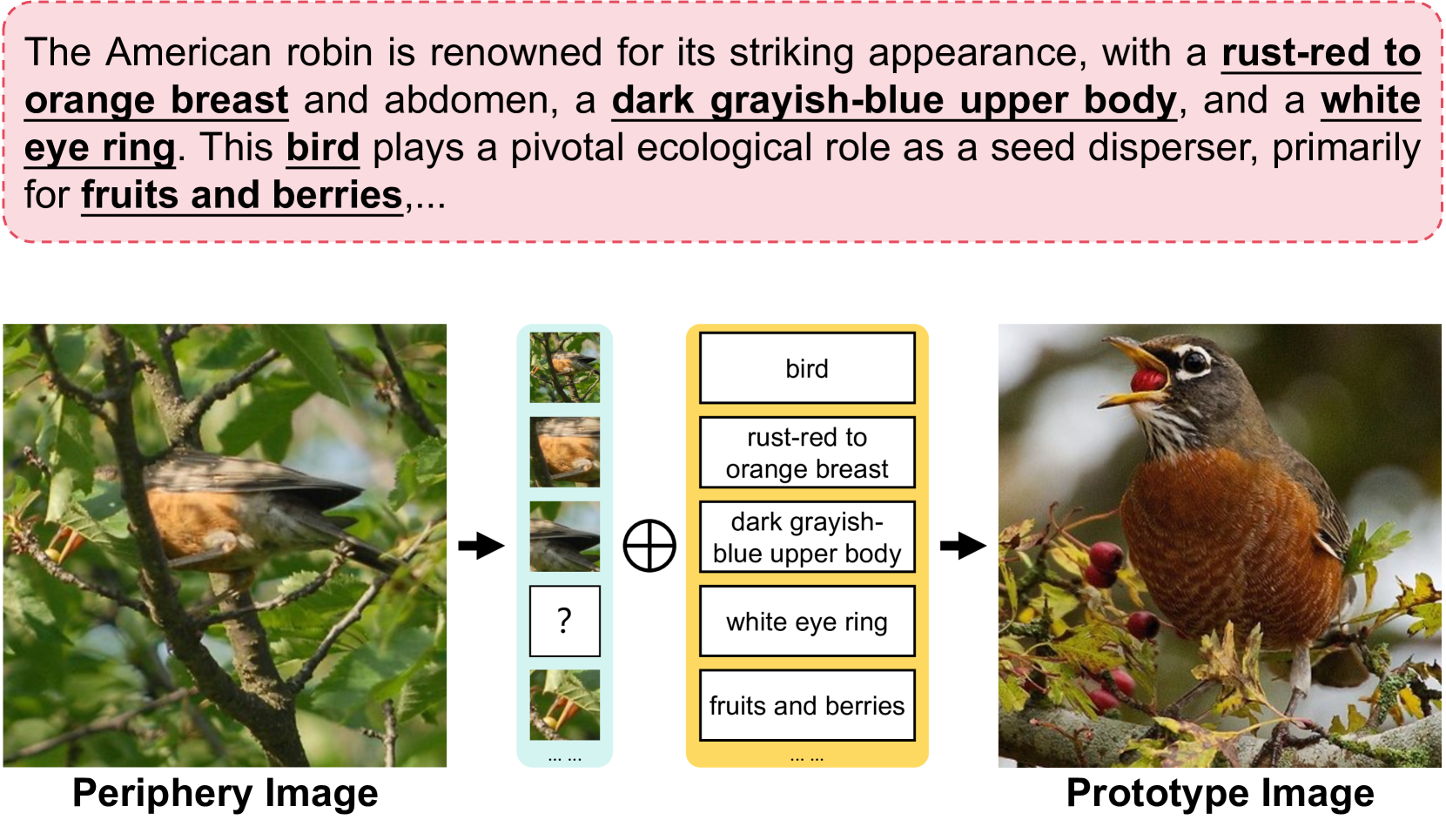
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
Read more4/10/2024
0
Hearing Anything Anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
Read more6/12/2024