MAP: Low-compute Model Merging with Amortized Pareto Fronts via Quadratic Approximation

0

Sign in to get full access
Overview
- The paper proposes a new method called MAP for efficiently merging pre-trained neural network models while preserving their Pareto-optimal performance on multiple tasks.
- MAP uses a quadratic approximation to estimate the Pareto front, allowing for much faster model merging compared to prior techniques.
- The method is shown to outperform previous model merging approaches on a range of benchmarks, while requiring significantly less computational resources.
Plain English Explanation
The paper introduces a new technique called MAP (Model Merging via Amortized Pareto fronts) that makes it easier and faster to combine pre-trained machine learning models.
When training a single model to perform multiple tasks, there is often a tradeoff between the model's performance on different tasks. MAP: Low-compute Model Merging with Amortized Pareto Fronts via Quadratic Approximation proposes a way to efficiently find the best balance, or "Pareto front", of model performance across these tasks.
The key insight is to use a mathematical approximation to estimate the Pareto front, rather than having to exhaustively search all possible combinations. This quadratic approximation allows MAP to merge models much more quickly than previous methods, while still identifying the best performance tradeoffs.
The authors show that MAP outperforms other model merging techniques across a variety of benchmarks, all while requiring less computational power. This makes it a promising approach for deploying high-performing multi-task models, especially on resource-constrained devices.
Technical Explanation
The paper introduces a new method called MAP (Model Merging via Amortized Pareto fronts) for efficiently merging pre-trained neural network models while preserving their Pareto-optimal performance on multiple tasks.
The core innovation of MAP is the use of a quadratic approximation to estimate the Pareto front of model performance across tasks. Prior techniques, such as Parametric Task MAP-Elites and Merging by Matching, required computationally expensive searches over the full space of possible model combinations.
In contrast, MAP builds a quadratic model of the Pareto front based on a small set of sampled model performance measurements. This allows it to quickly identify the optimal tradeoffs between task performances, leading to much faster model merging.
The authors evaluate MAP on a range of standard multi-task learning benchmarks, including image classification, language modeling, and reinforcement learning tasks. Across these domains, they show that MAP outperforms previous state-of-the-art model merging approaches in terms of final model performance and computational efficiency.
Critical Analysis
The paper makes a compelling case for the effectiveness of MAP, but there are a few potential limitations and areas for further research that could be explored:
-
Generalization to more complex Pareto fronts: The authors demonstrate the quadratic approximation works well on the benchmarks studied, but it may struggle with more complex, non-quadratic Pareto fronts that arise in real-world applications. Towards Geometry-Aware Pareto Set Learning for Neural Networks discusses some of the challenges in this area.
-
Sensitivity to sampling strategy: The performance of the quadratic approximation likely depends on the specific sampling strategy used to gather the initial performance measurements. Further research could explore more sophisticated sampling techniques to improve the robustness of the Pareto front estimation.
-
Practical applicability for large-scale models: While the paper shows MAP is computationally efficient compared to prior methods, merging large, high-performance models may still be prohibitively expensive, even with the quadratic approximation. Scaling MAP to real-world, deployable models is an important area for future work.
Overall, the MAP method represents a promising advance in the field of multi-task model merging, with strong empirical results and a thoughtful technical approach. However, as with any research, there are opportunities to build upon and refine the ideas presented in the paper.
Conclusion
The MAP: Low-compute Model Merging with Amortized Pareto Fronts via Quadratic Approximation paper introduces a novel technique for efficiently merging pre-trained neural network models to capture the Pareto-optimal tradeoffs in their performance across multiple tasks.
By using a quadratic approximation to estimate the Pareto front, MAP is able to identify the best model configurations much more quickly than previous approaches. The authors demonstrate the effectiveness of their method on a range of benchmarks, showing significant improvements in both model performance and computational efficiency.
This work represents an important step forward in the field of multi-task learning, providing a practical solution for deploying high-performing models on resource-constrained devices. As the complexity of machine learning systems continues to grow, techniques like MAP will become increasingly valuable for managing the tradeoffs inherent in these models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MAP: Low-compute Model Merging with Amortized Pareto Fronts via Quadratic Approximation
Lu Li, Tianyu Zhang, Zhiqi Bu, Suyuchen Wang, Huan He, Jie Fu, Yonghui Wu, Jiang Bian, Yong Chen, Yoshua Bengio
Model merging has emerged as an effective approach to combine multiple single-task models, fine-tuned from the same pre-trained model, into a multitask model. This process typically involves computing a weighted average of the model parameters without any additional training. Existing model-merging methods focus on enhancing average task accuracy. However, interference and conflicts between the objectives of different tasks can lead to trade-offs during model merging. In real-world applications, a set of solutions with various trade-offs can be more informative, helping practitioners make decisions based on diverse preferences. In this paper, we introduce a novel low-compute algorithm, Model Merging with Amortized Pareto Front (MAP). MAP identifies a Pareto set of scaling coefficients for merging multiple models to reflect the trade-offs. The core component of MAP is approximating the evaluation metrics of the various tasks using a quadratic approximation surrogate model derived from a pre-selected set of scaling coefficients, enabling amortized inference. Experimental results on vision and natural language processing tasks show that MAP can accurately identify the Pareto front. To further reduce the required computation of MAP, we propose (1) a Bayesian adaptive sampling algorithm and (2) a nested merging scheme with multiple stages.
Read more9/4/2024

0
Towards Efficient Pareto Set Approximation via Mixture of Experts Based Model Fusion
Anke Tang, Li Shen, Yong Luo, Shiwei Liu, Han Hu, Bo Du
Solving multi-objective optimization problems for large deep neural networks is a challenging task due to the complexity of the loss landscape and the expensive computational cost of training and evaluating models. Efficient Pareto front approximation of large models enables multi-objective optimization for various tasks such as multi-task learning and trade-off analysis. Existing algorithms for learning Pareto set, including (1) evolutionary, hypernetworks, and hypervolume-maximization methods, are computationally expensive and have restricted scalability to large models; (2) Scalarization algorithms, where a separate model is trained for each objective ray, which is inefficient for learning the entire Pareto set and fails to capture the objective trade-offs effectively. Inspired by the recent success of model merging, we propose a practical and scalable approach to Pareto set learning problem via mixture of experts (MoE) based model fusion. By ensembling the weights of specialized single-task models, the MoE module can effectively capture the trade-offs between multiple objectives and closely approximate the entire Pareto set of large neural networks. Once the routers are learned and a preference vector is set, the MoE module can be unloaded, thus no additional computational cost is introduced during inference. We conduct extensive experiments on vision and language tasks using large-scale models such as CLIP-ViT and GPT-2. The experimental results demonstrate that our method efficiently approximates the entire Pareto front of large models. Using only hundreds of trainable parameters of the MoE routers, our method even has lower memory usage compared to linear scalarization and algorithms that learn a single Pareto optimal solution, and are scalable to both the number of objectives and the size of the model.
Read more6/17/2024

0
You Only Merge Once: Learning the Pareto Set of Preference-Aware Model Merging
Weiyu Chen, James Kwok
Model merging, which combines multiple models into a single model, has gained increasing popularity in recent years. By efficiently integrating the capabilities of various models without their original training data, this significantly reduces the parameter count and memory usage. However, current methods can only produce one single merged model. This necessitates a performance trade-off due to conflicts among the various models, and the resultant one-size-fits-all model may not align with the preferences of different users who may prioritize certain models over others. To address this issue, we propose preference-aware model merging, and formulate this as a multi-objective optimization problem in which the performance of the merged model on each base model's task is treated as an objective. In only one merging process, the proposed parameter-efficient structure can generate the whole Pareto set of merged models, each representing the Pareto-optimal model for a given user-specified preference. Merged models can also be selected from the learned Pareto set that are tailored to different user preferences. Experimental results on a number of benchmark datasets demonstrate that the proposed preference-aware Pareto Merging can obtain a diverse set of trade-off models and outperforms state-of-the-art model merging baselines.
Read more8/23/2024
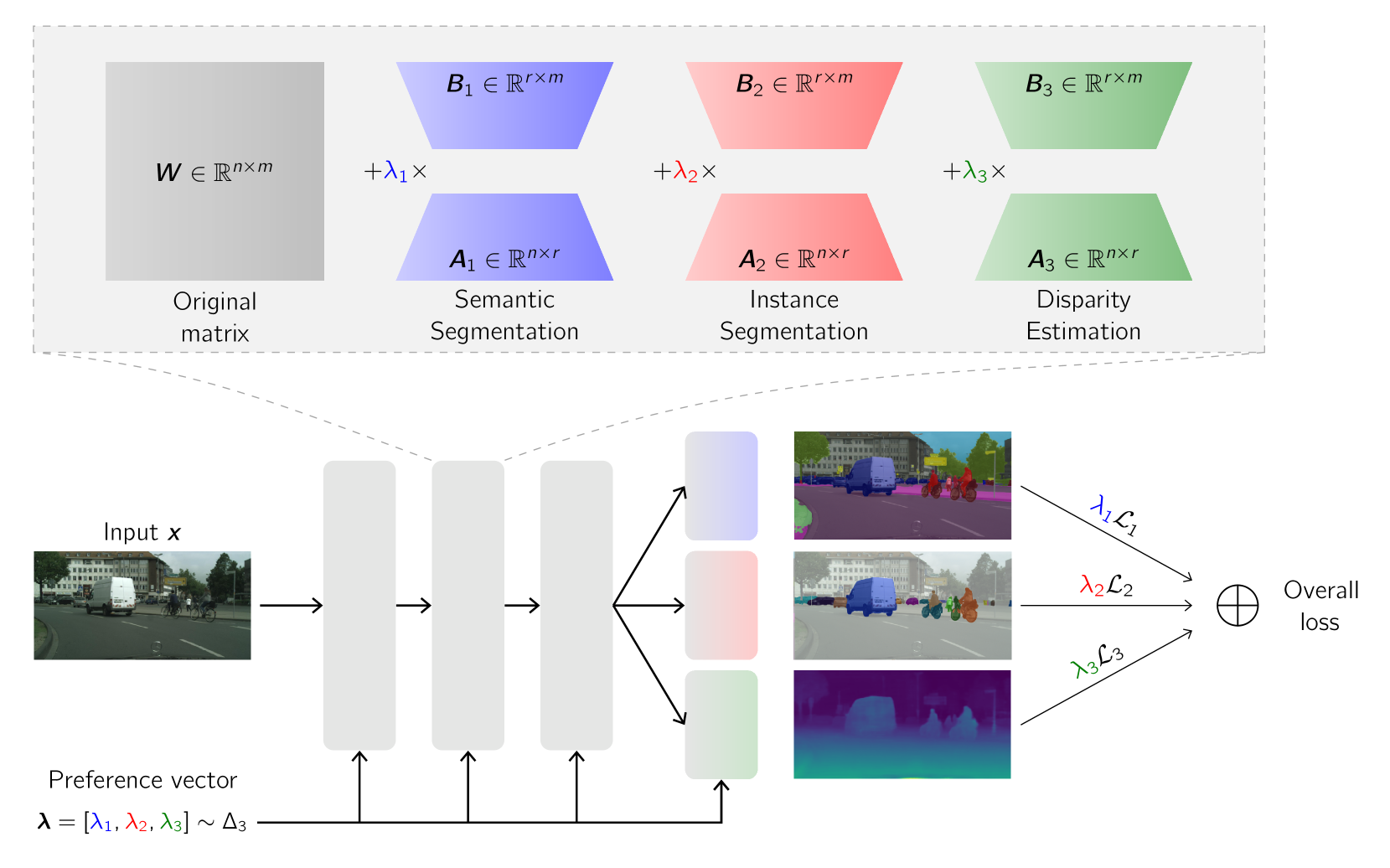
0
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Nikolaos Dimitriadis, Pascal Frossard, Francois Fleuret
Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
Read more7/12/2024