Memorize What Matters: Emergent Scene Decomposition from Multitraverse

0
🎯
Sign in to get full access
Overview
- This paper introduces a novel approach called 3D Gaussian Mapping (3DGM) that allows robots to build detailed 3D maps of their environment while also detecting and segmenting dynamic objects.
- 3DGM is a self-supervised, camera-only mapping framework that leverages repeated traversals of the same environment to distinguish permanent elements (like walls and floors) from ephemeral objects (like people or cars).
- The key idea is that the static environment remains consistent across multiple traversals, while dynamic objects change. 3DGM exploits this to decompose the environment into stable and transient elements.
Plain English Explanation
When humans explore a new area, we naturally remember the permanent features like buildings, roads, and landmarks, while the fleeting moments and moving objects often fade from our memory. 3D Gaussian Mapping (3DGM) aims to give robots this same capability, allowing them to build detailed 3D maps of their surroundings while also detecting and segmenting dynamic objects.
The researchers developed 3DGM as a self-supervised, camera-only mapping framework. This means it can create these environmental maps without any human intervention, just by analyzing video footage from the robot's own camera. The key insight is that while the overall environment remains consistent across multiple traversals, the dynamic objects like people and cars are constantly changing. 3DGM exploits this difference to separate the permanent features from the ephemeral ones, building a rich 3D model of the environment while also detecting and segmenting the moving objects.
This capability could be very valuable for robots and self-driving cars, allowing them to build a deep understanding of their surroundings to navigate more safely and effectively. It builds on previous work in areas like SLAM (simultaneous localization and mapping) and semantic mapping](https://aimodels.fyi/papers/arxiv/real-time-3d-semantic-occupancy-prediction-autonomous), but adds the key innovation of distinguishing static and dynamic elements in an unsupervised way.
Technical Explanation
The core of the 3DGM approach is to formulate the problem of multitraverse environmental mapping as a robust differentiable rendering task. The idea is to treat the permanent, static elements of the environment as the "inliers" that should be accurately reconstructed, while the dynamic, ephemeral objects are treated as "outliers" that can be ignored.
Through a process of robust feature distillation, feature residuals mining, and robust optimization, 3DGM is able to jointly perform 3D mapping of the environment and 2D segmentation of moving objects, all without any human-provided labels or annotations. The self-supervised nature of the approach allows it to scale to large, real-world environments.
To evaluate their method, the researchers built the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets. They demonstrate 3DGM's effectiveness on tasks like unsupervised 2D segmentation, 3D reconstruction, and neural rendering, showcasing its potential for applications in self-driving and robotics.
Critical Analysis
While the results presented in the paper are impressive, the authors acknowledge several limitations and avenues for future work. For example, the current 3DGM framework relies on having multiple traversals of the same environment, which may not always be feasible in real-world scenarios.
Additionally, the quality of the 3D reconstruction and object segmentation is still limited compared to what could be achieved with supervised methods. The authors suggest incorporating additional cues, such as depth information or semantic priors, could further improve performance.
Another potential concern is the computational complexity of the 3DGM approach, which may make it challenging to deploy on resource-constrained robotic platforms. The authors do not provide detailed benchmarks on inference speed or memory usage, so it's difficult to assess the practical limitations.
Overall, 3DGM represents an intriguing step forward in the field of unsupervised 3D scene understanding. While there is still room for improvement, the core ideas of leveraging repeated observations to decompose static and dynamic elements are promising and could inspire further innovation in this area.
Conclusion
This paper introduces a novel 3D Gaussian Mapping (3DGM) framework that allows robots to build detailed 3D maps of their environment while also detecting and segmenting dynamic objects. By exploiting the difference between permanent and ephemeral elements across multiple traversals, 3DGM can perform this task in a self-supervised manner, without any human-provided labels or annotations.
The results demonstrate the effectiveness of this approach on benchmark tasks, showcasing its potential for applications in self-driving and robotics. While there are still some limitations to address, 3DGM represents an exciting advance in the field of unsupervised 3D scene understanding. As robots and autonomous systems become more prevalent, capabilities like those enabled by 3DGM will be crucial for enabling them to safely and effectively navigate the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Memorize What Matters: Emergent Scene Decomposition from Multitraverse
Yiming Li, Zehong Wang, Yue Wang, Zhiding Yu, Zan Gojcic, Marco Pavone, Chen Feng, Jose M. Alvarez
Humans naturally retain memories of permanent elements, while ephemeral moments often slip through the cracks of memory. This selective retention is crucial for robotic perception, localization, and mapping. To endow robots with this capability, we introduce 3D Gaussian Mapping (3DGM), a self-supervised, camera-only offline mapping framework grounded in 3D Gaussian Splatting. 3DGM converts multitraverse RGB videos from the same region into a Gaussian-based environmental map while concurrently performing 2D ephemeral object segmentation. Our key observation is that the environment remains consistent across traversals, while objects frequently change. This allows us to exploit self-supervision from repeated traversals to achieve environment-object decomposition. More specifically, 3DGM formulates multitraverse environmental mapping as a robust differentiable rendering problem, treating pixels of the environment and objects as inliers and outliers, respectively. Using robust feature distillation, feature residuals mining, and robust optimization, 3DGM jointly performs 2D segmentation and 3D mapping without human intervention. We build the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets, to evaluate our method in unsupervised 2D segmentation, 3D reconstruction, and neural rendering. Extensive results verify the effectiveness and potential of our method for self-driving and robotics.
Read more5/31/2024

0
New!GEVO: Memory-Efficient Monocular Visual Odometry Using Gaussians
Dasong Gao, Peter Zhi Xuan Li, Vivienne Sze, Sertac Karaman
Constructing a high-fidelity representation of the 3D scene using a monocular camera can enable a wide range of applications on mobile devices, such as micro-robots, smartphones, and AR/VR headsets. On these devices, memory is often limited in capacity and its access often dominates the consumption of compute energy. Although Gaussian Splatting (GS) allows for high-fidelity reconstruction of 3D scenes, current GS-based SLAM is not memory efficient as a large number of past images is stored to retrain Gaussians for reducing catastrophic forgetting. These images often require two-orders-of-magnitude higher memory than the map itself and thus dominate the total memory usage. In this work, we present GEVO, a GS-based monocular SLAM framework that achieves comparable fidelity as prior methods by rendering (instead of storing) them from the existing map. Novel Gaussian initialization and optimization techniques are proposed to remove artifacts from the map and delay the degradation of the rendered images over time. Across a variety of environments, GEVO achieves comparable map fidelity while reducing the memory overhead to around 58 MBs, which is up to 94x lower than prior works.
Read more9/17/2024

0
TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments
Daeun Song, Jing Liang, Xuesu Xiao, Dinesh Manocha
We present a multi-modal trajectory generation and selection algorithm for real-world mapless outdoor navigation in challenging scenarios with unstructured off-road features like buildings, grass, and curbs. Our goal is to compute suitable trajectories that (1) satisfy the environment-specific traversability constraints and (2) generate human-like paths while navigating in crosswalks, sidewalks, etc. Our formulation uses a Conditional Variational Autoencoder (CVAE) generative model enhanced with traversability constraints to generate multiple candidate trajectories for global navigation. We use VLMs and a visual prompting approach with their zero-shot ability of semantic understanding and logical reasoning to choose the best trajectory given the contextual information about the task. We evaluate our methods in various outdoor scenes with wheeled robots and compare the performance with other global navigation algorithms. In practice, we observe at least 3.35% improvement in traversability and 20.61% improvement in terms of human-like navigation in generated trajectories in challenging outdoor navigation scenarios.
Read more8/9/2024
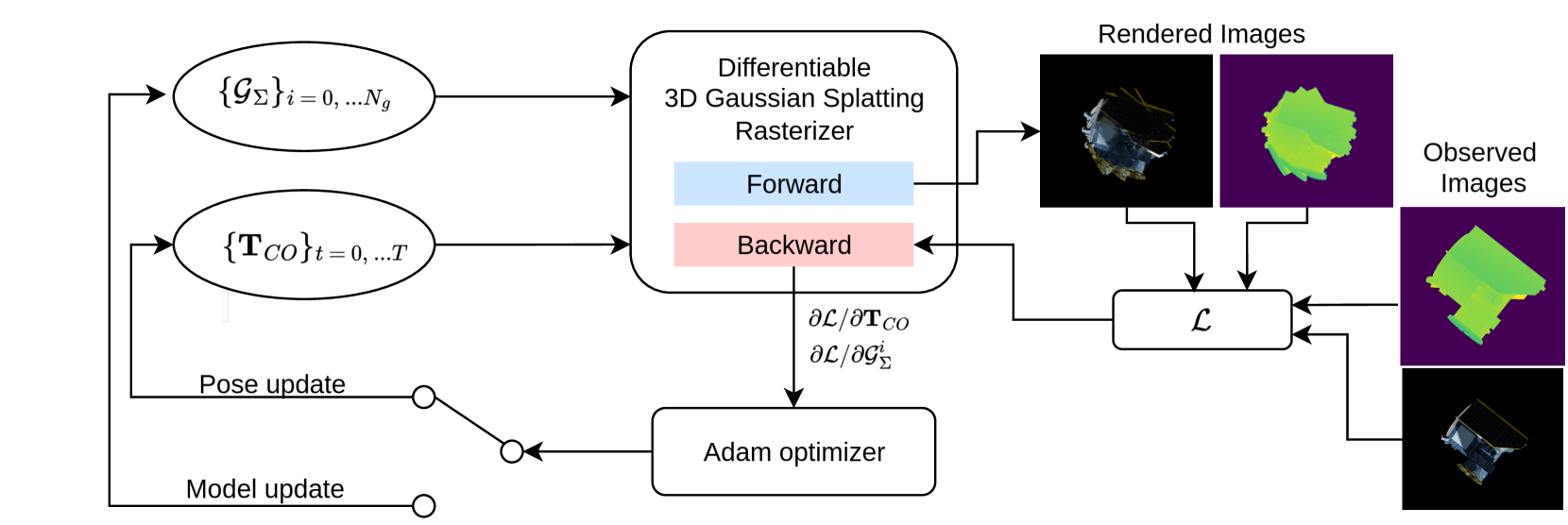
0
Object-centric Reconstruction and Tracking of Dynamic Unknown Objects using 3D Gaussian Splatting
Kuldeep R Barad, Antoine Richard, Jan Dentler, Miguel Olivares-Mendez, Carol Martinez
Generalizable perception is one of the pillars of high-level autonomy in space robotics. Estimating the structure and motion of unknown objects in dynamic environments is fundamental for such autonomous systems. Traditionally, the solutions have relied on prior knowledge of target objects, multiple disparate representations, or low-fidelity outputs unsuitable for robotic operations. This work proposes a novel approach to incrementally reconstruct and track a dynamic unknown object using a unified representation -- a set of 3D Gaussian blobs that describe its geometry and appearance. The differentiable 3D Gaussian Splatting framework is adapted to a dynamic object-centric setting. The input to the pipeline is a sequential set of RGB-D images. 3D reconstruction and 6-DoF pose tracking tasks are tackled using first-order gradient-based optimization. The formulation is simple, requires no pre-training, assumes no prior knowledge of the object or its motion, and is suitable for online applications. The proposed approach is validated on a dataset of 10 unknown spacecraft of diverse geometry and texture under arbitrary relative motion. The experiments demonstrate successful 3D reconstruction and accurate 6-DoF tracking of the target object in proximity operations over a short to medium duration. The causes of tracking drift are discussed and potential solutions are outlined.
Read more5/31/2024