FairEvalLLM. A Comprehensive Framework for Benchmarking Fairness in Large Language Model Recommender Systems

0
💬
Sign in to get full access
Overview
- This paper presents a framework for evaluating fairness in recommender systems powered by Large Language Models (RecLLMs).
- The framework addresses fairness across different dimensions, including sensitivity to user attributes, intrinsic fairness, and discussions of fairness based on underlying benefits.
- The framework also introduces counterfactual evaluations and integrates diverse user group considerations to enhance the discourse on fairness evaluation for RecLLMs.
Plain English Explanation
The paper describes a way to evaluate the fairness of recommendation systems that use large language models (LLMs) to make suggestions. Fairness is an important consideration in these systems, as they can potentially reinforce biases or discriminate against certain groups of users.
The framework developed in the paper looks at fairness from multiple angles. It considers how sensitive the recommendations are to user attributes like demographics, whether the recommendations are intrinsically fair (i.e., fair even without considering user attributes), and whether the underlying benefits of the recommendations are distributed fairly.
The framework also introduces counterfactual evaluations, which allow the researchers to see how recommendations would change if certain user attributes were different. This helps uncover potential biases. The framework also looks at fairness across diverse user groups.
Overall, the goal is to provide a comprehensive way to assess the fairness of these powerful recommendation systems, which are increasingly being used in various applications.
Technical Explanation
The paper presents a framework for evaluating fairness in RecLLMs. The key contributions include:
- Development of a robust framework for fairness evaluation in LLM-based recommendations.
- A structured method to create "informative user profiles" from demographic data, historical user preferences, and recent interactions. The authors argue this is essential for enhancing personalization in temporal-driven scenarios.
The researchers demonstrate the utility of their framework through practical applications on two datasets, LastFM-1K and ML-1M. They conduct experiments on a subsample of 80 users from each dataset, testing and assessing the effectiveness of various prompt construction scenarios and in-context learning, comprising more than 50 scenarios. This results in more than 4000 recommendations.
The study reveals that while there are no significant unfairness issues in scenarios involving sensitive attributes, some concerns remain. However, in terms of intrinsic fairness, which does not involve direct sensitivity, unfairness across demographic groups remains significant.
Critical Analysis
The paper presents a comprehensive framework for evaluating fairness in RecLLMs, which is a crucial aspect as these systems become more prevalent. The introduction of counterfactual evaluations and the integration of diverse user group considerations are valuable additions to the fairness discourse.
However, the paper acknowledges that the study is limited to a subsample of users, and the findings may not fully generalize to larger user populations. Additionally, the paper does not explore the potential impacts of different prompt construction scenarios and in-context learning techniques on fairness, which could be an interesting avenue for further research.
It would also be beneficial to see a more in-depth discussion of the specific fairness concerns identified in the intrinsic fairness evaluations and potential strategies to mitigate these issues.
Conclusion
This paper presents a comprehensive framework for evaluating fairness in RecLLMs, addressing the critical need for a unified approach to assessing fairness across multiple dimensions. The framework's introduction of counterfactual evaluations and its integration of diverse user group considerations are valuable contributions to the field.
The findings suggest that while there are no significant unfairness issues in scenarios involving sensitive attributes, concerns remain in terms of intrinsic fairness across demographic groups. This highlights the importance of continued research and development of fairness-aware recommendation systems to ensure equitable and inclusive experiences for all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
FairEvalLLM. A Comprehensive Framework for Benchmarking Fairness in Large Language Model Recommender Systems
Yashar Deldjoo, Fatemeh Nazary
The rapid adoption of large language models (LLMs) in recommender systems (RS) presents new challenges in understanding and evaluating their biases, which can result in unfairness or the amplification of stereotypes. Traditional fairness evaluations in RS primarily focus on collaborative filtering (CF) settings, which may not fully capture the complexities of LLMs, as these models often inherit biases from large, unregulated data. This paper proposes a normative framework to benchmark consumer fairness in LLM-powered recommender systems (RecLLMs). We critically examine how fairness norms in classical RS fall short in addressing the challenges posed by LLMs. We argue that this gap can lead to arbitrary conclusions about fairness, and we propose a more structured, formal approach to evaluate fairness in such systems. Our experiments on the MovieLens dataset on consumer fairness, using in-context learning (zero-shot vs. few-shot) reveal fairness deviations in age-based recommendations, particularly when additional contextual examples are introduced (ICL-2). Statistical significance tests confirm that these deviations are not random, highlighting the need for robust evaluation methods. While this work offers a preliminary discussion on a proposed normative framework, our hope is that it could provide a formal, principled approach for auditing and mitigating bias in RecLLMs. The code and dataset used for this work will be shared at gihub-anonymized.
Read more9/12/2024
0
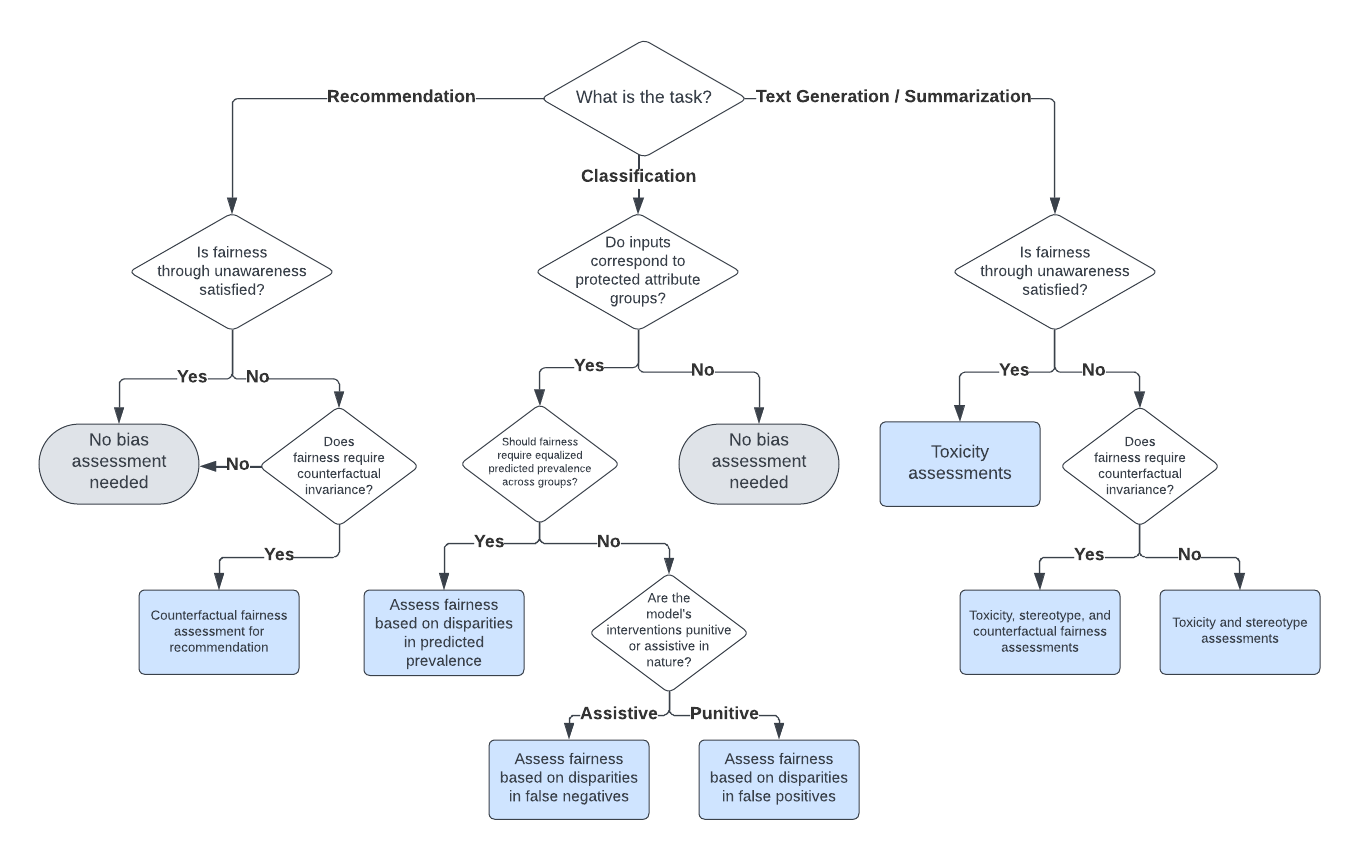
An Actionable Framework for Assessing Bias and Fairness in Large Language Model Use Cases
Dylan Bouchard
Large language models (LLMs) can exhibit bias in a variety of ways. Such biases can create or exacerbate unfair outcomes for certain groups within a protected attribute, including, but not limited to sex, race, sexual orientation, or age. This paper aims to provide a technical guide for practitioners to assess bias and fairness risks in LLM use cases. The main contribution of this work is a decision framework that allows practitioners to determine which metrics to use for a specific LLM use case. To achieve this, this study categorizes LLM bias and fairness risks, maps those risks to a taxonomy of LLM use cases, and then formally defines various metrics to assess each type of risk. As part of this work, several new bias and fairness metrics are introduced, including innovative counterfactual metrics as well as metrics based on stereotype classifiers. Instead of focusing solely on the model itself, the sensitivity of both prompt-risk and model-risk are taken into account by defining evaluations at the level of an LLM use case, characterized by a model and a population of prompts. Furthermore, because all of the evaluation metrics are calculated solely using the LLM output, the proposed framework is highly practical and easily actionable for practitioners.
Read more8/9/2024
🏷️
0
New!Challenging Fairness: A Comprehensive Exploration of Bias in LLM-Based Recommendations
Shahnewaz Karim Sakib, Anindya Bijoy Das
Large Language Model (LLM)-based recommendation systems provide more comprehensive recommendations than traditional systems by deeply analyzing content and user behavior. However, these systems often exhibit biases, favoring mainstream content while marginalizing non-traditional options due to skewed training data. This study investigates the intricate relationship between bias and LLM-based recommendation systems, with a focus on music, song, and book recommendations across diverse demographic and cultural groups. Through a comprehensive analysis conducted over different LLM-models, this paper evaluates the impact of bias on recommendation outcomes. Our findings reveal that bias is so deeply ingrained within these systems that even a simpler intervention like prompt engineering can significantly reduce bias, underscoring the pervasive nature of the issue. Moreover, factors like intersecting identities and contextual information, such as socioeconomic status, further amplify these biases, demonstrating the complexity and depth of the challenges faced in creating fair recommendations across different groups.
Read more9/18/2024
💬
0
Fairness in Large Language Models in Three Hour
Thang Doan Viet, Zichong Wang, Minh Nhat Nguyen, Wenbin Zhang
Large Language Models (LLMs) have demonstrated remarkable success across various domains but often lack fairness considerations, potentially leading to discriminatory outcomes against marginalized populations. Unlike fairness in traditional machine learning, fairness in LLMs involves unique backgrounds, taxonomies, and fulfillment techniques. This tutorial provides a systematic overview of recent advances in the literature concerning fair LLMs, beginning with real-world case studies to introduce LLMs, followed by an analysis of bias causes therein. The concept of fairness in LLMs is then explored, summarizing the strategies for evaluating bias and the algorithms designed to promote fairness. Additionally, resources for assessing bias in LLMs, including toolkits and datasets, are compiled, and current research challenges and open questions in the field are discussed. The repository is available at url{https://github.com/LavinWong/Fairness-in-Large-Language-Models}.
Read more8/6/2024