Optimizing Sparse Convolution on GPUs with CUDA for 3D Point Cloud Processing in Embedded Systems
2402.07710
0
0

Abstract
In recent years, there has been a significant increase in the utilization of deep learning methods, particularly convolutional neural networks (CNNs), which have emerged as the dominant approach in various domains that involve structured grid data, such as picture analysis and processing. Nevertheless, the exponential growth in the utilization of LiDAR and 3D sensors across many domains has resulted in an increased need for the analysis of 3D point clouds. The utilization of 3D point clouds is crucial in various applications, including object recognition and segmentation, as they offer a spatial depiction of things within a three-dimensional environment. In contrast to photos, point clouds exhibit sparsity and lack a regular grid, hence posing distinct processing and computational issues.
Create account to get full access
Overview
- This paper explores optimizing sparse convolution, a key operation in 3D point cloud processing, on GPUs using CUDA.
- Sparse convolution is computationally intensive and can be a bottleneck in 3D point cloud applications like unsupervised occupancy learning from sparse point cloud, PV-SSDA multi-modal point cloud feature, few-shot point cloud reconstruction and denoising, and fully sparse 3D occupancy prediction.
- The authors propose several GPU-based optimizations to improve the performance of sparse convolution, including leveraging the sparsity of 3D point clouds.
- Experiments on real-world datasets show significant speedups compared to existing methods, with the potential to boost the efficiency of 3D point cloud processing pipelines.
Plain English Explanation
This research paper is about making 3D point cloud processing more efficient on graphics processing units (GPUs). 3D point clouds are digital representations of real-world objects or environments, made up of a large number of individual 3D data points.
One of the key operations in processing 3D point clouds is called "sparse convolution." This is a computationally intensive task that can slow down the overall performance of 3D point cloud applications, like detecting and tracking objects in point cloud data.
The researchers in this paper developed several optimizations to speed up sparse convolution on GPUs using a programming framework called CUDA. They took advantage of the fact that 3D point clouds are often sparse, meaning there are many empty or unoccupied regions, to make the convolution process more efficient.
Through experiments on real-world datasets, the researchers showed that their optimized sparse convolution methods can provide significant performance improvements compared to existing approaches. This could lead to more efficient and responsive 3D point cloud processing pipelines, benefiting a wide range of applications, from autonomous vehicles to augmented reality.
Technical Explanation
The core focus of this paper is optimizing sparse convolution, a crucial operation in 3D point cloud processing, for execution on GPUs using CUDA. Sparse convolution is computationally intensive and can be a major performance bottleneck in applications that rely on 3D point cloud data, multi-modal point cloud features, few-shot point cloud reconstruction and denoising, and fully sparse 3D occupancy prediction.
The authors propose several GPU-based optimizations to improve the performance of sparse convolution. These include:
- Leveraging the inherent sparsity of 3D point clouds to reduce the number of computations
- Utilizing efficient data structures and memory access patterns on the GPU
- Optimizing kernel launch configurations and thread block sizes
- Overlapping computation and data transfer to hide latency
The researchers evaluated their optimized sparse convolution methods on real-world datasets and compared them to existing approaches. Their results demonstrate significant speedups, ranging from 2x to 10x, depending on the specific workload and configuration.
Critical Analysis
The paper provides a comprehensive set of optimizations for sparse convolution on GPUs, addressing a critical performance bottleneck in 3D point cloud processing. The authors have thoroughly evaluated their techniques and demonstrated impressive speedups across various datasets and workloads.
One potential limitation of the work is that it focuses solely on the sparse convolution operation, without considering the broader context of the entire 3D point cloud processing pipeline. While improving the efficiency of this key step is valuable, the overall performance may still be constrained by other components of the pipeline, such as data preprocessing, feature extraction, or downstream tasks.
Additionally, the paper does not explore the trade-offs between the proposed optimizations and other factors, such as power consumption, memory usage, or programming complexity. These aspects could be important considerations for real-world deployment in resource-constrained environments or complex system integrations.
Further research could investigate the integration of the optimized sparse convolution module into end-to-end 3D point cloud processing frameworks, evaluating the overall system-level performance and exploring opportunities for holistic optimization. Incorporating additional benchmarks, such as energy efficiency or development complexity, could also provide a more comprehensive assessment of the proposed techniques.
Conclusion
This research paper presents a series of GPU-based optimizations for improving the performance of sparse convolution, a crucial operation in 3D point cloud processing. By leveraging the inherent sparsity of 3D point clouds and employing efficient data structures and memory access patterns, the authors have demonstrated significant speedups in sparse convolution compared to existing methods.
The potential impact of this work is substantial, as it can contribute to more efficient and responsive 3D point cloud processing pipelines across a wide range of applications, from autonomous vehicles and robotics to augmented reality and digital twins. By addressing a key bottleneck in the 3D point cloud processing workflow, this research paves the way for more accurate, real-time, and cost-effective solutions that can benefit both industry and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
A comprehensive overview of deep learning techniques for 3D point cloud classification and semantic segmentation
Sushmita Sarker, Prithul Sarker, Gunner Stone, Ryan Gorman, Alireza Tavakkoli, George Bebis, Javad Sattarvand
0
0
Point cloud analysis has a wide range of applications in many areas such as computer vision, robotic manipulation, and autonomous driving. While deep learning has achieved remarkable success on image-based tasks, there are many unique challenges faced by deep neural networks in processing massive, unordered, irregular and noisy 3D points. To stimulate future research, this paper analyzes recent progress in deep learning methods employed for point cloud processing and presents challenges and potential directions to advance this field. It serves as a comprehensive review on two major tasks in 3D point cloud processing-- namely, 3D shape classification and semantic segmentation.
5/21/2024

Sparse Points to Dense Clouds: Enhancing 3D Detection with Limited LiDAR Data
Aakash Kumar, Chen Chen, Ajmal Mian, Neils Lobo, Mubarak Shah
0
0
3D detection is a critical task that enables machines to identify and locate objects in three-dimensional space. It has a broad range of applications in several fields, including autonomous driving, robotics and augmented reality. Monocular 3D detection is attractive as it requires only a single camera, however, it lacks the accuracy and robustness required for real world applications. High resolution LiDAR on the other hand, can be expensive and lead to interference problems in heavy traffic given their active transmissions. We propose a balanced approach that combines the advantages of monocular and point cloud-based 3D detection. Our method requires only a small number of 3D points, that can be obtained from a low-cost, low-resolution sensor. Specifically, we use only 512 points, which is just 1% of a full LiDAR frame in the KITTI dataset. Our method reconstructs a complete 3D point cloud from this limited 3D information combined with a single image. The reconstructed 3D point cloud and corresponding image can be used by any multi-modal off-the-shelf detector for 3D object detection. By using the proposed network architecture with an off-the-shelf multi-modal 3D detector, the accuracy of 3D detection improves by 20% compared to the state-of-the-art monocular detection methods and 6% to 9% compare to the baseline multi-modal methods on KITTI and JackRabbot datasets.
4/11/2024
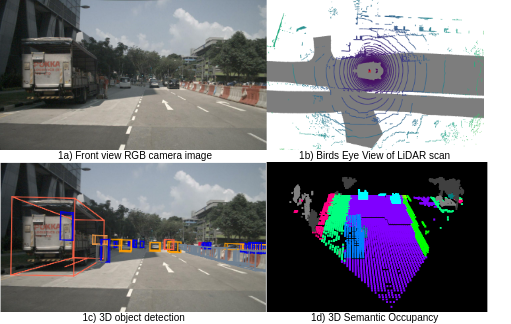
Real-time 3D semantic occupancy prediction for autonomous vehicles using memory-efficient sparse convolution
Samuel Sze, Lars Kunze
0
0
In autonomous vehicles, understanding the surrounding 3D environment of the ego vehicle in real-time is essential. A compact way to represent scenes while encoding geometric distances and semantic object information is via 3D semantic occupancy maps. State of the art 3D mapping methods leverage transformers with cross-attention mechanisms to elevate 2D vision-centric camera features into the 3D domain. However, these methods encounter significant challenges in real-time applications due to their high computational demands during inference. This limitation is particularly problematic in autonomous vehicles, where GPU resources must be shared with other tasks such as localization and planning. In this paper, we introduce an approach that extracts features from front-view 2D camera images and LiDAR scans, then employs a sparse convolution network (Minkowski Engine), for 3D semantic occupancy prediction. Given that outdoor scenes in autonomous driving scenarios are inherently sparse, the utilization of sparse convolution is particularly apt. By jointly solving the problems of 3D scene completion of sparse scenes and 3D semantic segmentation, we provide a more efficient learning framework suitable for real-time applications in autonomous vehicles. We also demonstrate competitive accuracy on the nuScenes dataset.
5/21/2024

Twin Deformable Point Convolutions for Point Cloud Semantic Segmentation in Remote Sensing Scenes
Yong-Qiang Mao, Hanbo Bi, Xuexue Li, Kaiqiang Chen, Zhirui Wang, Xian Sun, Kun Fu
0
0
Thanks to the application of deep learning technology in point cloud processing of the remote sensing field, point cloud segmentation has become a research hotspot in recent years, which can be applied to real-world 3D, smart cities, and other fields. Although existing solutions have made unprecedented progress, they ignore the inherent characteristics of point clouds in remote sensing fields that are strictly arranged according to latitude, longitude, and altitude, which brings great convenience to the segmentation of point clouds in remote sensing fields. To consider this property cleverly, we propose novel convolution operators, termed Twin Deformable point Convolutions (TDConvs), which aim to achieve adaptive feature learning by learning deformable sampling points in the latitude-longitude plane and altitude direction, respectively. First, to model the characteristics of the latitude-longitude plane, we propose a Cylinder-wise Deformable point Convolution (CyDConv) operator, which generates a two-dimensional cylinder map by constructing a cylinder-like grid in the latitude-longitude direction. Furthermore, to better integrate the features of the latitude-longitude plane and the spatial geometric features, we perform a multi-scale fusion of the extracted latitude-longitude features and spatial geometric features, and realize it through the aggregation of adjacent point features of different scales. In addition, a Sphere-wise Deformable point Convolution (SpDConv) operator is introduced to adaptively offset the sampling points in three-dimensional space by constructing a sphere grid structure, aiming at modeling the characteristics in the altitude direction. Experiments on existing popular benchmarks conclude that our TDConvs achieve the best segmentation performance, surpassing the existing state-of-the-art methods.
5/31/2024