PARL: A Unified Framework for Policy Alignment in Reinforcement Learning from Human Feedback

0
🏅
Sign in to get full access
Overview
- Introduces a novel bilevel optimization framework called PARL to address policy alignment in reinforcement learning (RL) using preference-based feedback.
- Identifies issues in current algorithms due to lack of precise characterization of the dependence between the alignment objective and policy trajectories.
- Proposes a formulation that explicitly models this relationship, leading to a new class of stochastic bilevel optimization problems.
- Presents an algorithm called A-PARL to solve the PARL problem, with theoretical guarantees.
- Demonstrates significant improvements in policy alignment for large-scale RL environments.
Plain English Explanation
In reinforcement learning (RL), the goal is for an agent to learn an optimal policy (a set of rules for making decisions) by interacting with an environment and receiving feedback, often in the form of rewards. However, a key challenge in RL is policy alignment, which refers to ensuring that the agent's learned policy aligns with the preferences or utility of the human providing the feedback.
The authors of this paper identify a shortcoming in existing algorithms for solving the policy alignment problem. Specifically, they note that these algorithms do not adequately capture the dependence between the alignment objective (the reward design) and the optimal policy. This lack of precise characterization leads to suboptimal performance.
To address this issue, the researchers propose a novel bilevel optimization framework called PARL. In this framework, the upper-level problem involves designing the optimal reward function (alignment objective), while the lower-level problem involves finding the optimal policy for the designed reward. By explicitly modeling the relationship between these two components, the authors create a new class of stochastic bilevel optimization problems.
The researchers then devise an algorithm called A-PARL to solve the PARL problem, and they provide theoretical guarantees on its sample complexity (the number of samples required to achieve a certain level of performance). Additionally, they demonstrate that the proposed PARL framework can significantly improve policy alignment in large-scale RL environments, such as those in the DeepMind control suite and Meta World tasks.
Overall, this work addresses an important challenge in RL by proposing a principled framework for aligning agent policies with human preferences. The authors' novel formulation and algorithm represent an important step towards developing more robust and reliable RL systems.
Technical Explanation
The authors present a novel unified bilevel optimization-based framework, PARL, to address the critical issue of policy alignment in reinforcement learning (RL) using utility or preference-based feedback. They identify a major gap in current algorithmic designs for solving policy alignment, which is the lack of precise characterization of the dependence of the alignment objective (reward design) on the data generated by policy trajectories. This shortfall contributes to the suboptimal performance observed in contemporary algorithms.
The PARL framework addresses these concerns by explicitly parameterizing the distribution of the upper alignment objective (reward design) by the lower-level optimal variable (optimal policy for the designed reward). From an optimization perspective, this formulation leads to a new class of stochastic bilevel problems where the stochasticity at the upper objective depends on the lower-level variable.
To demonstrate the efficacy of the PARL formulation in resolving alignment issues in RL, the authors devised an algorithm called A-PARL to solve the PARL problem. They establish sample complexity bounds of order O(1/T) for the A-PARL algorithm, where T is the number of iterations.
The empirical results presented in the paper show that the proposed PARL framework can address the alignment concerns in RL by achieving significant improvements (up to 63% in terms of required samples) for policy alignment in large-scale environments of the DeepMind control suite and Meta World tasks.
Critical Analysis
The paper presents a well-designed and principled approach to addressing the critical issue of policy alignment in reinforcement learning (RL) using preference-based feedback. The authors' identification of the key gap in current algorithmic designs and their proposed solution through the PARL framework are commendable.
One potential limitation of the PARL framework is its reliance on the assumption that the distribution of the alignment objective (reward design) can be explicitly parameterized by the optimal policy. While this assumption may hold in certain problem settings, it may not be universally applicable, especially in more complex RL environments. The authors acknowledge this limitation and suggest further research to relax this assumption.
Additionally, the paper does not provide a comprehensive comparison of the PARL framework with other state-of-the-art approaches for policy alignment, such as contrastive preference learning, iterative preference learning, or personalized reinforcement learning from heterogeneous feedback. A more thorough comparison would help to better contextualize the contributions of the PARL framework and its relative strengths and weaknesses.
Overall, the paper presents a novel and promising approach to the policy alignment problem in RL, and the authors' theoretical and empirical results are convincing. However, further research to address the limitations and explore the broader implications of the PARL framework would be valuable for the field.
Conclusion
The authors of this paper have introduced a novel unified bilevel optimization-based framework called PARL to address the critical issue of policy alignment in reinforcement learning (RL) using preference-based feedback. By explicitly modeling the dependence between the alignment objective (reward design) and the optimal policy, the PARL framework addresses a key shortcoming in existing algorithms and leads to a new class of stochastic bilevel optimization problems.
The proposed A-PARL algorithm, designed to solve the PARL problem, demonstrates significant improvements in policy alignment for large-scale RL environments, with theoretical guarantees on its sample complexity. This work represents an important step forward in developing more robust and reliable RL systems that can effectively align agent policies with human preferences.
While the PARL framework has some limitations, the authors' innovative approach and the promising results suggest that this research could have far-reaching implications for the field of reinforcement learning and the broader challenge of aligning artificial intelligence systems with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
PARL: A Unified Framework for Policy Alignment in Reinforcement Learning from Human Feedback
Souradip Chakraborty, Amrit Singh Bedi, Alec Koppel, Dinesh Manocha, Huazheng Wang, Mengdi Wang, Furong Huang
We present a novel unified bilevel optimization-based framework, textsf{PARL}, formulated to address the recently highlighted critical issue of policy alignment in reinforcement learning using utility or preference-based feedback. We identify a major gap within current algorithmic designs for solving policy alignment due to a lack of precise characterization of the dependence of the alignment objective on the data generated by policy trajectories. This shortfall contributes to the sub-optimal performance observed in contemporary algorithms. Our framework addressed these concerns by explicitly parameterizing the distribution of the upper alignment objective (reward design) by the lower optimal variable (optimal policy for the designed reward). Interestingly, from an optimization perspective, our formulation leads to a new class of stochastic bilevel problems where the stochasticity at the upper objective depends upon the lower-level variable. {True to our best knowledge, this work presents the first formulation of the RLHF as a bilevel optimization problem which generalizes the existing RLHF formulations and addresses the existing distribution shift issues in RLHF formulations.} To demonstrate the efficacy of our formulation in resolving alignment issues in RL, we devised an algorithm named textsf{A-PARL} to solve PARL problem, establishing sample complexity bounds of order $mathcal{O}(1/T)$. Our empirical results substantiate that the proposed textsf{PARL} can address the alignment concerns in RL by showing significant improvements (up to 63% in terms of required samples) for policy alignment in large-scale environments of the Deepmind control suite and Meta world tasks.
Read more5/2/2024

0
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences
Daiwei Chen, Yi Chen, Aniket Rege, Ramya Korlakai Vinayak
Large foundation models pretrained on raw web-scale data are not readily deployable without additional step of extensive alignment to human preferences. Such alignment is typically done by collecting large amounts of pairwise comparisons from humans (Do you prefer output A or B?) and learning a reward model or a policy with the Bradley-Terry-Luce (BTL) model as a proxy for a human's underlying implicit preferences. These methods generally suffer from assuming a universal preference shared by all humans, which lacks the flexibility of adapting to plurality of opinions and preferences. In this work, we propose PAL, a framework to model human preference complementary to existing pretraining strategies, which incorporates plurality from the ground up. We propose using the ideal point model as a lens to view alignment using preference comparisons. Together with our novel reformulation and using mixture modeling, our framework captures the plurality of population preferences while simultaneously learning a common preference latent space across different preferences, which can few-shot generalize to new, unseen users. Our approach enables us to use the penultimate-layer representation of large foundation models and simple MLP layers to learn reward functions that are on-par with the existing large state-of-the-art reward models, thereby enhancing efficiency of reward modeling significantly. We show that PAL achieves competitive reward model accuracy compared to strong baselines on 1) Language models with Summary dataset ; 2) Image Generative models with Pick-a-Pic dataset ; 3) A new semisynthetic heterogeneous dataset generated using Anthropic Personas. Finally, our experiments also highlight the shortcoming of current preference datasets that are created using rigid rubrics which wash away heterogeneity, and call for more nuanced data collection approaches.
Read more6/13/2024
0
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
Read more5/7/2024
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
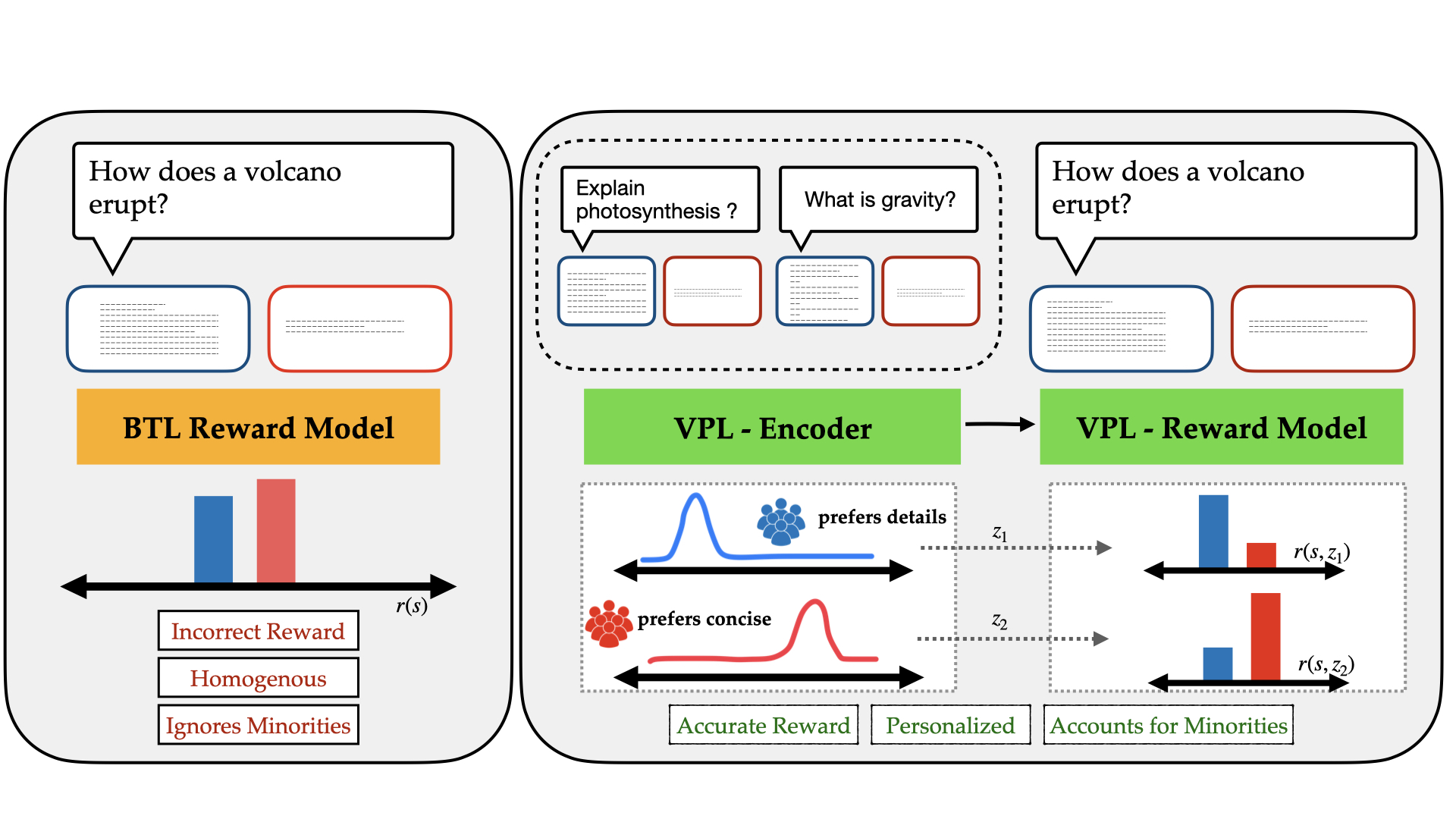
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024