On The Persona-based Summarization of Domain-Specific Documents

0

Sign in to get full access
Overview
- This paper presents an approach for summarizing medical documents based on the target persona (e.g., patient, doctor, caregiver).
- It aims to generate summaries that are tailored to the needs and perspectives of different stakeholders in the healthcare system.
- The authors explore techniques like persona-specific prompt engineering and persona-conditioned summarization models.
Plain English Explanation
The paper focuses on automatically summarizing medical documents in a way that is customized for different types of readers, such as patients, doctors, and caregivers. The idea is that the same medical information can be summarized differently depending on who is reading it.
For example, a summary for a patient might focus more on explaining medical concepts in simple terms and highlighting key takeaways, while a summary for a doctor might provide more technical details and treatment recommendations. By tailoring the summaries to the reader's needs and perspective, the authors hope to make the information more accessible and useful.
The paper explores techniques like prompt engineering to craft persona-specific prompts that guide the summarization model, as well as persona-conditioned summarization models that can generate summaries adapted to different personas.
Technical Explanation
The paper presents a novel approach for persona-based summarization of medical documents. The authors first define three key personas in the healthcare domain: patients, doctors, and caregivers. They then develop persona-specific prompts to guide the summarization model, with the goal of generating summaries that are tailored to the needs and perspectives of each persona.
The authors experiment with both prompt engineering and persona-conditioned summarization models. In the prompt engineering approach, they craft persona-specific prompts that instruct the summarization model to focus on different aspects of the input document. In the persona-conditioned model approach, they fine-tune a large language model to generate summaries that are conditioned on the target persona.
The authors evaluate their approaches on a dataset of medical documents and find that the persona-based summaries are more useful and relevant to their target audiences compared to generic, one-size-fits-all summaries.
Critical Analysis
The paper presents a promising approach for improving the usefulness of medical document summaries by tailoring them to different personas. However, there are a few potential limitations and areas for further research:
- The paper only considers three broad personas (patients, doctors, caregivers) and does not explore finer-grained persona segmentation or the potential for more personalized summaries.
- The evaluation is limited to quantitative metrics and does not include user studies or feedback from actual stakeholders to assess the real-world impact of the persona-based summaries.
- The authors do not discuss the potential ethical implications of persona-based summarization, such as concerns about bias or fairness if the summaries reinforce stereotypes or fail to meet the needs of certain groups.
Further research could explore ways to make the persona-based summarization more flexible and adaptable, as well as investigate the long-term effects and societal impact of this technology.
Conclusion
This paper presents a novel approach for persona-based summarization of medical documents, which aims to generate summaries that are tailored to the needs and perspectives of different stakeholders in the healthcare system, such as patients, doctors, and caregivers.
The authors explore techniques like prompt engineering and persona-conditioned summarization models to create summaries that are more useful and relevant to their target audiences. While the paper presents promising results, there are also some potential limitations and areas for further research, such as exploring more personalized personas and investigating the ethical implications of this technology.
Overall, this work highlights the importance of considering the diverse needs and perspectives of different users when summarizing complex medical information, and it offers a valuable contribution to the field of document summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On The Persona-based Summarization of Domain-Specific Documents
Ankan Mullick, Sombit Bose, Rounak Saha, Ayan Kumar Bhowmick, Pawan Goyal, Niloy Ganguly, Prasenjit Dey, Ravi Kokku
In an ever-expanding world of domain-specific knowledge, the increasing complexity of consuming, and storing information necessitates the generation of summaries from large information repositories. However, every persona of a domain has different requirements of information and hence their summarization. For example, in the healthcare domain, a persona-based (such as Doctor, Nurse, Patient etc.) approach is imperative to deliver targeted medical information efficiently. Persona-based summarization of domain-specific information by humans is a high cognitive load task and is generally not preferred. The summaries generated by two different humans have high variability and do not scale in cost and subject matter expertise as domains and personas grow. Further, AI-generated summaries using generic Large Language Models (LLMs) may not necessarily offer satisfactory accuracy for different domains unless they have been specifically trained on domain-specific data and can also be very expensive to use in day-to-day operations. Our contribution in this paper is two-fold: 1) We present an approach to efficiently fine-tune a domain-specific small foundation LLM using a healthcare corpus and also show that we can effectively evaluate the summarization quality using AI-based critiquing. 2) We further show that AI-based critiquing has good concordance with Human-based critiquing of the summaries. Hence, such AI-based pipelines to generate domain-specific persona-based summaries can be easily scaled to other domains such as legal, enterprise documents, education etc. in a very efficient and cost-effective manner.
Read more6/7/2024

0
AspirinSum: an Aspect-based utility-preserved de-identification Summarization framework
Ya-Lun Li
Due to the rapid advancement of Large Language Model (LLM), the whole community eagerly consumes any available text data in order to train the LLM. Currently, large portion of the available text data are collected from internet, which has been thought as a cheap source of the training data. However, when people try to extend the LLM's capability to the personal related domain, such as healthcare or education, the lack of public dataset in these domains make the adaption of the LLM in such domains much slower. The reason of lacking public available dataset in such domains is because they usually contain personal sensitive information. In order to comply with privacy law, the data in such domains need to be de-identified before any kind of dissemination. It had been much research tried to address this problem for the image or tabular data. However, there was limited research on the efficient and general de-identification method for text data. Most of the method based on human annotation or predefined category list. It usually can not be easily adapted to specific domains. The goal of this proposal is to develop a text de-identification framework, which can be easily adapted to the specific domain, leverage the existing expert knowledge without further human annotation. We propose an aspect-based utility-preserved de-identification summarization framework, AspirinSum, by learning to align expert's aspect from existing comment data, it can efficiently summarize the personal sensitive document by extracting personal sensitive aspect related sub-sentence and de-identify it by substituting it with similar aspect sub-sentence. We envision that the de-identified text can then be used in data publishing, eventually publishing our de-identified dataset for downstream task use.
Read more6/21/2024
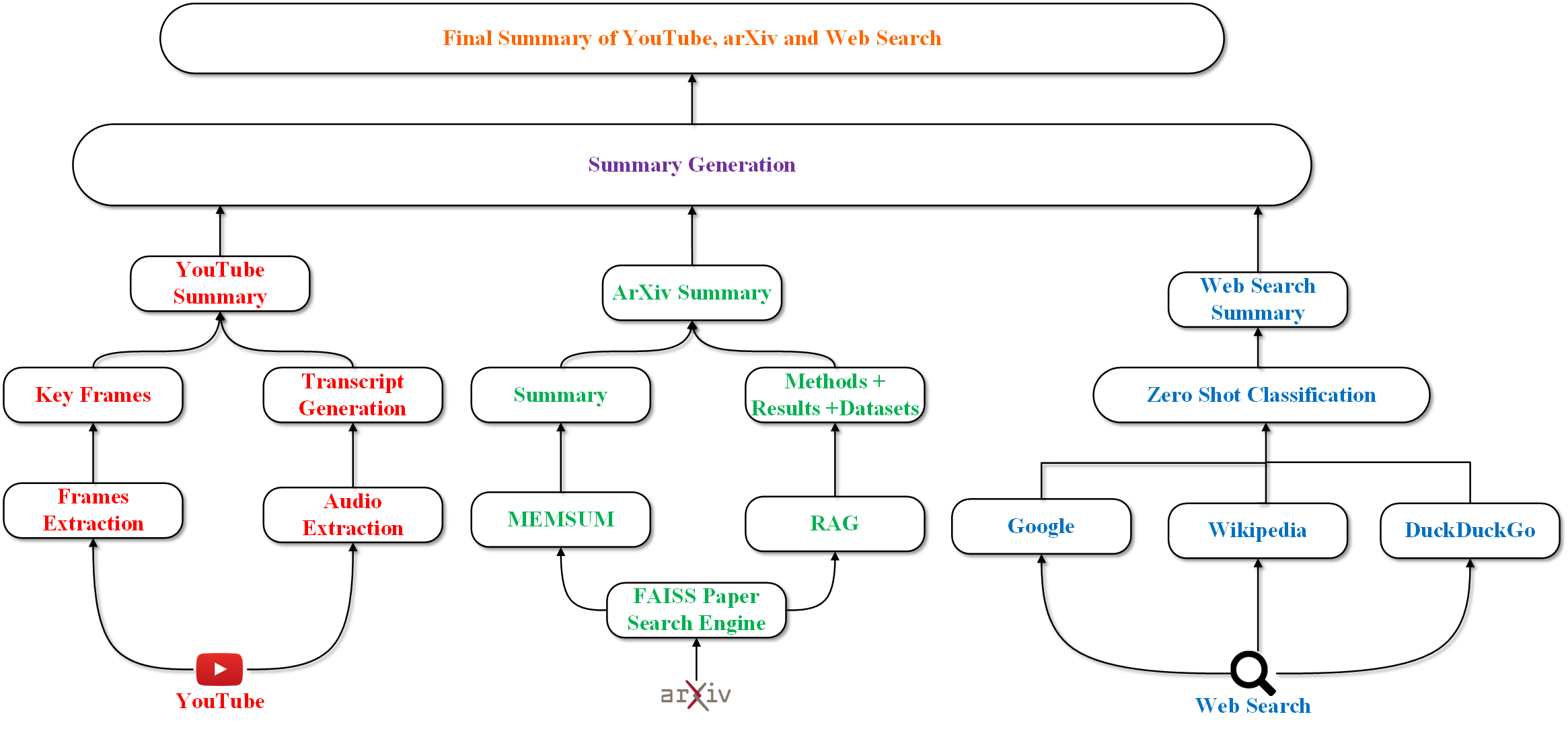
0
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
Read more6/21/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024