PoCo: Point Context Cluster for RGBD Indoor Place Recognition

0

Sign in to get full access
Overview
- This paper proposes a novel approach called PoCo (Point Context Cluster) for RGBD indoor place recognition.
- PoCo leverages the context information in 3D point clouds to improve the accuracy of indoor place recognition tasks.
- The authors demonstrate the effectiveness of PoCo on several indoor datasets, showing improvements over existing methods.
Plain English Explanation
Place recognition, the task of identifying a specific location or scene, is an important problem in robotics and other applications. When a robot or system needs to navigate an indoor environment, it's crucial to be able to recognize and remember different rooms or areas.
The PoCo method proposed in this paper aims to improve indoor place recognition by using the 3D point cloud data that can be captured with RGBD (RGB-Depth) sensors. Rather than just looking at the individual 3D points, PoCo considers the context of each point - the surrounding points and their relationships. By clustering these point cloud contexts, the system can better distinguish between different indoor locations and recognize places more accurately.
The authors show that PoCo outperforms previous 3D point cloud-based methods for indoor place recognition across several benchmark datasets. This suggests the value of leveraging rich contextual information in 3D point clouds for this task.
Technical Explanation
The key innovation in PoCo is the use of point context clusters to represent indoor scenes. Rather than just using individual 3D points, PoCo considers the local neighborhood or context around each point. It groups similar point contexts into clusters, which then serve as the basis for place recognition.
Specifically, PoCo first extracts local point cloud patches around each 3D point. It then computes features that capture the geometry and appearance of these point cloud patches. Next, PoCo clusters the point cloud patches into a set of point context clusters.
For place recognition, PoCo represents each scene as a histogram of the occurrences of these point context clusters. This compact mapping allows for efficient comparison of different indoor locations. The authors demonstrate that this point context-based approach outperforms prior methods that only use individual 3D points or simple geometric features.
Critical Analysis
The authors acknowledge several limitations of the PoCo approach. First, the unsupervised occupancy learning used to cluster point contexts may not always capture the most discriminative features for place recognition. Additionally, the histogram-based scene representation, while efficient, may lose some of the rich spatial information present in the original point cloud data.
Furthermore, the experiments in the paper are conducted on relatively small-scale indoor datasets. It remains to be seen how well PoCo would scale to larger environments or handle more complex real-world situations. The authors also do not explore the robustness of the method to sensor noise, occlusions, or other common challenges in real-world indoor navigation.
Overall, the PoCo approach represents an interesting step forward in leveraging 3D point cloud context for indoor place recognition. However, further research is needed to address the potential limitations and explore the method's performance in more diverse and realistic scenarios.
Conclusion
The PoCo method proposed in this paper demonstrates the value of considering point cloud context for indoor place recognition tasks. By capturing the relationships between 3D points and clustering similar point cloud patches, PoCo is able to outperform previous approaches that rely solely on individual 3D points or simple geometric features.
While the paper highlights several promising results, there are still opportunities for improvement and further research. Addressing the limitations around the unsupervised clustering and the potential loss of spatial information could help strengthen the PoCo approach. Evaluating the method's performance in larger-scale, more complex indoor environments would also be valuable.
Overall, this work contributes to the ongoing efforts to develop robust and efficient indoor navigation systems, with potential applications in robotics, augmented reality, and smart building technologies. As the field continues to evolve, approaches like PoCo that leverage the rich contextual information in 3D point clouds may play an increasingly important role.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Jing Liang, Zhuo Deng, Zheming Zhou, Omid Ghasemalizadeh, Dinesh Manocha, Min Sun, Cheng-Hao Kuo, Arnie Sen
We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.
Read more9/4/2024
0
CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition
Jing Liang, Zhuo Deng, Zheming Zhou, Min Sun, Omid Ghasemalizadeh, Cheng-Hao Kuo, Arnie Sen, Dinesh Manocha
We present a new algorithm, Cross-Source-Context Place Recognition (CSCPR), for RGB-D indoor place recognition that integrates global retrieval and reranking into a single end-to-end model. Unlike prior approaches that primarily focus on the RGB domain, CSCPR is designed to handle the RGB-D data. We extend the Context-of-Clusters (CoCs) for handling noisy colorized point clouds and introduce two novel modules for reranking: the Self-Context Cluster (SCC) and Cross Source Context Cluster (CSCC), which enhance feature representation and match query-database pairs based on local features, respectively. We also present two new datasets, ScanNetIPR and ARKitIPR. Our experiments demonstrate that CSCPR significantly outperforms state-of-the-art models on these datasets by at least 36.5% in Recall@1 at ScanNet-PR dataset and 44% in new datasets. Code and datasets will be released.
Read more7/25/2024

0
Context-Aware Indoor Point Cloud Object Generation through User Instructions
Yiyang Luo, Ke Lin, Chao Gu
Indoor scene modification has emerged as a prominent area within computer vision, particularly for its applications in Augmented Reality (AR) and Virtual Reality (VR). Traditional methods often rely on pre-existing object databases and predetermined object positions, limiting their flexibility and adaptability to new scenarios. In response to this challenge, we present a novel end-to-end multi-modal deep neural network capable of generating point cloud objects seamlessly integrated with their surroundings, driven by textual instructions. Our model revolutionizes scene modification by enabling the creation of new environments with previously unseen object layouts, eliminating the need for pre-stored CAD models. Leveraging Point-E as our generative model, we introduce innovative techniques such as quantized position prediction and Top-K estimation to address the issue of false negatives resulting from ambiguous language descriptions. Furthermore, we conduct comprehensive evaluations to showcase the diversity of generated objects, the efficacy of textual instructions, and the quantitative metrics, affirming the realism and versatility of our model in generating indoor objects. To provide a holistic assessment, we incorporate visual grounding as an additional metric, ensuring the quality and coherence of the scenes produced by our model. Through these advancements, our approach not only advances the state-of-the-art in indoor scene modification but also lays the foundation for future innovations in immersive computing and digital environment creation.
Read more8/13/2024
0
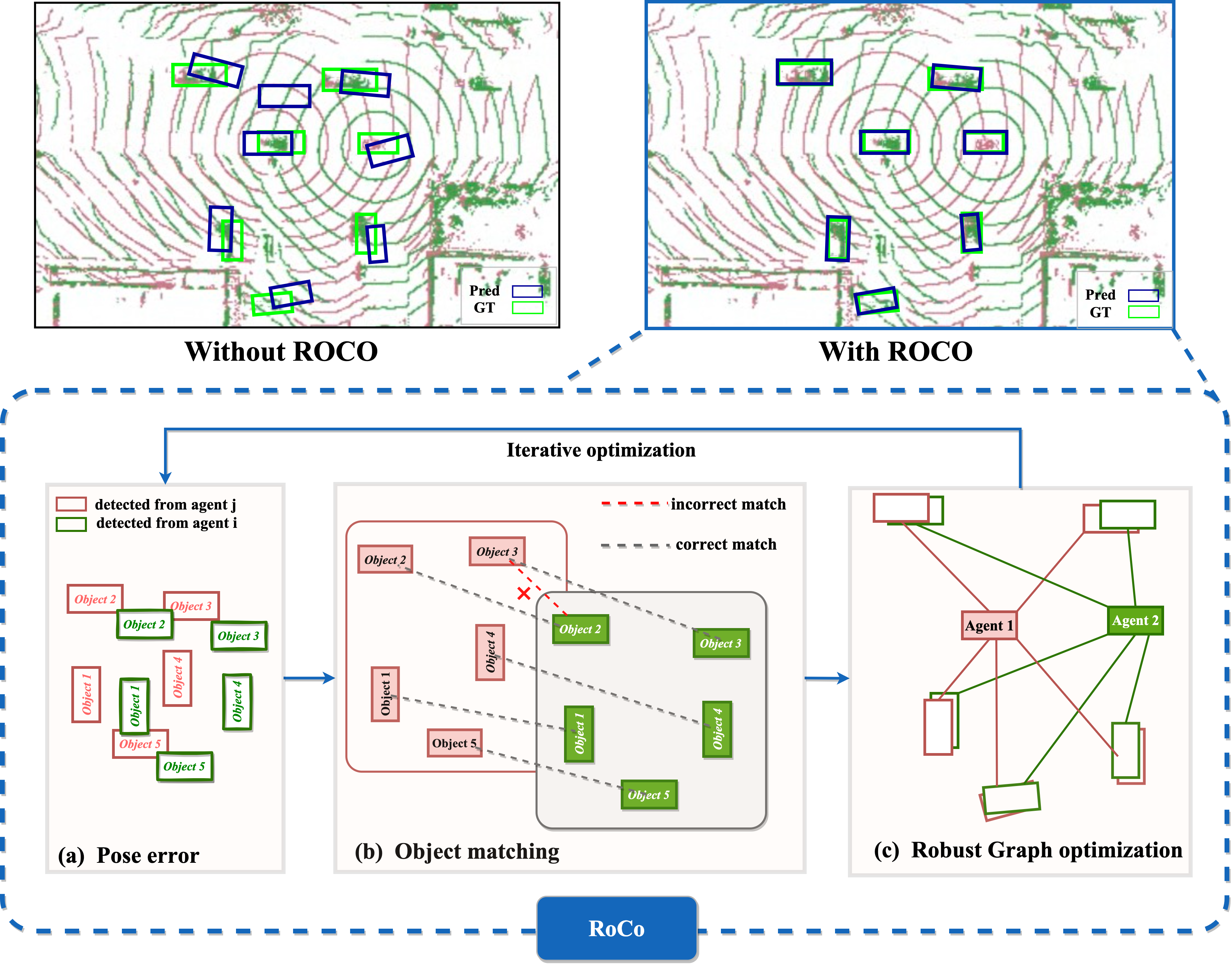
RoCo:Robust Collaborative Perception By Iterative Object Matching and Pose Adjustment
Zhe Huang, Shuo Wang, Yongcai Wang, Wanting Li, Deying Li, Lei Wang
Collaborative autonomous driving with multiple vehicles usually requires the data fusion from multiple modalities. To ensure effective fusion, the data from each individual modality shall maintain a reasonably high quality. However, in collaborative perception, the quality of object detection based on a modality is highly sensitive to the relative pose errors among the agents. It leads to feature misalignment and significantly reduces collaborative performance. To address this issue, we propose RoCo, a novel unsupervised framework to conduct iterative object matching and agent pose adjustment. To the best of our knowledge, our work is the first to model the pose correction problem in collaborative perception as an object matching task, which reliably associates common objects detected by different agents. On top of this, we propose a graph optimization process to adjust the agent poses by minimizing the alignment errors of the associated objects, and the object matching is re-done based on the adjusted agent poses. This process is carried out iteratively until convergence. Experimental study on both simulated and real-world datasets demonstrates that the proposed framework RoCo consistently outperforms existing relevant methods in terms of the collaborative object detection performance, and exhibits highly desired robustness when the pose information of agents is with high-level noise. Ablation studies are also provided to show the impact of its key parameters and components. The code is released at https://github.com/HuangZhe885/RoCo.
Read more8/2/2024