Pre-training with Synthetic Data Helps Offline Reinforcement Learning

0
Sign in to get full access
Overview
- This paper explores using pre-training with synthetic data to improve offline reinforcement learning (RL) performance using the Decision Transformer model.
- The researchers demonstrate that pre-training on synthetic data can significantly boost the performance of the Decision Transformer on offline RL benchmarks compared to training from scratch.
- The paper provides insights into the benefits of leveraging synthetic data for offline RL and the capabilities of the Decision Transformer architecture.
Plain English Explanation
The paper discusses a technique to improve the performance of a type of machine learning model called a Decision Transformer when applied to offline reinforcement learning. Offline reinforcement learning is a challenging machine learning problem where the model has to learn how to make good decisions based on historical data, without the ability to actively interact with the environment.
The key insight of the paper is that pre-training the Decision Transformer model on synthetic data - data that is artificially generated to mimic real-world scenarios - can significantly boost its performance on offline reinforcement learning benchmarks compared to training it from scratch. This suggests that the knowledge gained from the synthetic pre-training helps the model learn more effectively from the limited historical data available in offline RL settings.
The Decision Transformer is an interesting model architecture that uses transformer-based language models to tackle reinforcement learning problems. By framing the RL task as a "language modeling" problem, the Decision Transformer can leverage the powerful capabilities of transformers to make effective decisions.
Overall, this paper provides valuable insights into how synthetic data can be leveraged to improve the performance of offline reinforcement learning systems, as well as the potential of the Decision Transformer model for tackling complex decision-making problems.
Technical Explanation
The paper proposes a method to improve the performance of the Decision Transformer model on offline reinforcement learning tasks by pre-training it on synthetic data. The Decision Transformer is a transformer-based architecture that frames the RL problem as a language modeling task, where the model predicts the next action given the current state and a desired return trajectory.
The authors first generate synthetic datasets using a dynamics model and reward function, which are then used to pre-train the Decision Transformer. They evaluate the pre-trained model on several offline RL benchmarks, including D4RL and Gym Minigrid, and compare its performance to models trained from scratch.
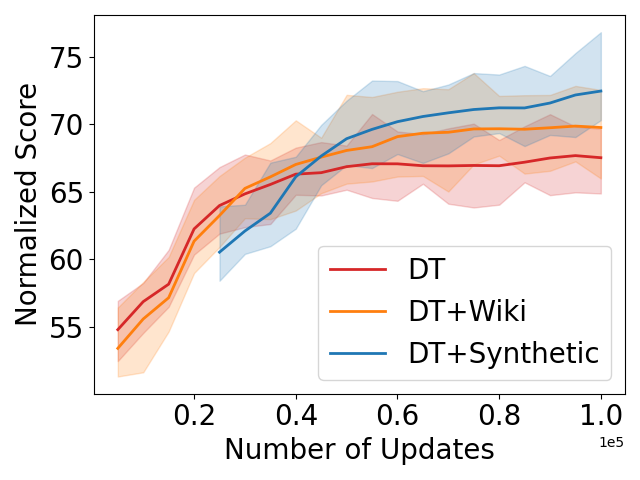
The results show that pre-training on synthetic data significantly boosts the performance of the Decision Transformer on these offline RL tasks, outperforming models trained without pre-training. The authors attribute this improvement to the synthetic data helping the model learn better representations and priors that are useful for the offline RL problem.
Additionally, the paper investigates the impact of the quality and diversity of the synthetic data, as well as the effect of fine-tuning the pre-trained model on the actual offline RL datasets. The findings suggest that high-quality and diverse synthetic data is crucial for effective pre-training, and that further fine-tuning on the offline data can provide additional performance gains.
Critical Analysis
The paper provides a compelling approach for leveraging synthetic data to improve the performance of the Decision Transformer on offline reinforcement learning tasks. The researchers demonstrate the effectiveness of this technique across multiple benchmark datasets, which is a strength of the work.
However, some potential limitations or caveats are worth considering:
-
Dependence on Synthetic Data Quality: The performance gains of the pre-trained Decision Transformer largely depend on the quality and fidelity of the synthetic data used. If the synthetic data does not accurately reflect the real-world dynamics and reward structures, the pre-training may not provide the expected benefits. Further research could explore techniques to generate even more robust and representative synthetic data.
-
Generalization to Other RL Architectures: While the paper focuses on the Decision Transformer, it would be interesting to see if the synthetic data pre-training approach can also benefit other offline RL architectures, such as Behavior Cloning or Advantage Weighted Actor-Critic. Expanding the evaluation to a wider range of models would help establish the broader applicability of this technique.
-
Real-world Deployment Considerations: The paper does not explicitly address the practical challenges of deploying such a system in real-world scenarios, where the availability and quality of historical data may be limited. Further research could explore the robustness of this approach to noisy or incomplete offline data, as well as the computational and resource requirements for pre-training and fine-tuning.
Overall, this paper makes a valuable contribution to the field of offline reinforcement learning by demonstrating the potential of synthetic data pre-training to boost the performance of the Decision Transformer. The findings provide a promising direction for future research and development in this area.
Conclusion
This paper presents a novel approach to improve the performance of the Decision Transformer model on offline reinforcement learning tasks by pre-training it on synthetic data. The results show that leveraging high-quality and diverse synthetic data can significantly boost the Decision Transformer's performance on a range of offline RL benchmarks, outperforming models trained from scratch.
The insights from this research suggest that synthetic data can be a powerful tool for enhancing the capabilities of offline RL systems, particularly when working with limited historical data. The findings also highlight the potential of the Decision Transformer architecture to tackle complex decision-making problems by framing them as language modeling tasks.
As the field of offline reinforcement learning continues to evolve, techniques like the one proposed in this paper could pave the way for more robust and effective solutions, with potential applications in areas such as robotics, resource allocation, and decision support systems. Further research exploring the broader applicability of synthetic data pre-training and the real-world deployment challenges would be valuable next steps.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pre-training with Synthetic Data Helps Offline Reinforcement Learning
Zecheng Wang, Che Wang, Zixuan Dong, Keith Ross
Recently, it has been shown that for offline deep reinforcement learning (DRL), pre-training Decision Transformer with a large language corpus can improve downstream performance (Reid et al., 2022). A natural question to ask is whether this performance gain can only be achieved with language pre-training, or can be achieved with simpler pre-training schemes which do not involve language. In this paper, we first show that language is not essential for improved performance, and indeed pre-training with synthetic IID data for a small number of updates can match the performance gains from pre-training with a large language corpus; moreover, pre-training with data generated by a one-step Markov chain can further improve the performance. Inspired by these experimental results, we then consider pre-training Conservative Q-Learning (CQL), a popular offline DRL algorithm, which is Q-learning-based and typically employs a Multi-Layer Perceptron (MLP) backbone. Surprisingly, pre-training with simple synthetic data for a small number of updates can also improve CQL, providing consistent performance improvement on D4RL Gym locomotion datasets. The results of this paper not only illustrate the importance of pre-training for offline DRL but also show that the pre-training data can be synthetic and generated with remarkably simple mechanisms.
Read more5/28/2024
🏅
0
Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining
Licong Lin, Yu Bai, Song Mei
Large transformer models pretrained on offline reinforcement learning datasets have demonstrated remarkable in-context reinforcement learning (ICRL) capabilities, where they can make good decisions when prompted with interaction trajectories from unseen environments. However, when and how transformers can be trained to perform ICRL have not been theoretically well-understood. In particular, it is unclear which reinforcement-learning algorithms transformers can perform in context, and how distribution mismatch in offline training data affects the learned algorithms. This paper provides a theoretical framework that analyzes supervised pretraining for ICRL. This includes two recently proposed training methods -- algorithm distillation and decision-pretrained transformers. First, assuming model realizability, we prove the supervised-pretrained transformer will imitate the conditional expectation of the expert algorithm given the observed trajectory. The generalization error will scale with model capacity and a distribution divergence factor between the expert and offline algorithms. Second, we show transformers with ReLU attention can efficiently approximate near-optimal online reinforcement learning algorithms like LinUCB and Thompson sampling for stochastic linear bandits, and UCB-VI for tabular Markov decision processes. This provides the first quantitative analysis of the ICRL capabilities of transformers pretrained from offline trajectories.
Read more5/28/2024

0
Pre-trained Language Models Improve the Few-shot Prompt Ability of Decision Transformer
Yu Yang, Pan Xu
Decision Transformer (DT) has emerged as a promising class of algorithms in offline reinforcement learning (RL) tasks, leveraging pre-collected datasets and Transformer's capability to model long sequences. Recent works have demonstrated that using parts of trajectories from training tasks as prompts in DT enhances its performance on unseen tasks, giving rise to Prompt-DT methods. However, collecting data from specific environments can be both costly and unsafe in many scenarios, leading to suboptimal performance and limited few-shot prompt abilities due to the data-hungry nature of Transformer-based models. Additionally, the limited datasets used in pre-training make it challenging for Prompt-DT type of methods to distinguish between various RL tasks through prompts alone. To address these challenges, we introduce the Language model-initialized Prompt Decision Transformer (LPDT), which leverages pre-trained language models for meta-RL tasks and fine-tunes the model using Low-rank Adaptation (LoRA). We further incorporate prompt regularization to effectively differentiate between tasks based on prompt feature representations. Our approach integrates pre-trained language model and RL tasks seamlessly. Extensive empirical studies demonstrate that initializing with a pre-trained language model significantly enhances the performance of Prompt-DT on unseen tasks compared to baseline methods.
Read more8/6/2024

2
Synthetic continued pretraining
Zitong Yang, Neil Band, Shuangping Li, Emmanuel Cand`es, Tatsunori Hashimoto
Pretraining on large-scale, unstructured internet text has enabled language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient -- to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining using EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can rearrange knowledge to enable more data-efficient learning.
Read more9/12/2024