Progressive Alignment with VLM-LLM Feature to Augment Defect Classification for the ASE Dataset

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Progressive Alignment with VLM-LLM Feature" to improve defect classification on the ASE dataset.
- The key idea is to leverage the complementary strengths of Vision-Language Models (VLMs) and Large Language Models (LLMs) to enhance the classification of software defects.
- The proposed method aims to address the challenge of few-shot defect recognition, where limited training data is available.
Plain English Explanation
The researchers developed a new technique that combines the power of two types of AI models - vision-language models (VLMs) and large language models (LLMs) - to improve the identification of software defects. The ASE dataset is a collection of software code and associated defects that the researchers used to test their approach.
One of the main challenges in this area is that there is often limited training data available, making it difficult for AI models to accurately recognize different types of software defects. The researchers' solution, called "Progressive Alignment with VLM-LLM Feature," aims to overcome this challenge by leveraging the complementary strengths of VLMs and LLMs.
VLMs are AI models that can understand and process both visual and text-based information, while LLMs are powerful language models that excel at understanding and generating natural language. By combining these two types of models, the researchers believe they can create a more robust and accurate system for detecting software defects, even when the training data is limited.
Technical Explanation
The paper introduces a novel approach called "Progressive Alignment with VLM-LLM Feature" to improve defect classification on the ASE dataset. The key idea is to leverage the complementary strengths of Vision-Language Models (VLMs) and Large Language Models (LLMs) to enhance the classification of software defects, particularly in the context of few-shot scenarios where limited training data is available.
The proposed method consists of two main components:
- Progressive Alignment: This step aligns the VLM and LLM representations to create a unified feature space, allowing the models to share and learn from each other's strengths.
- VLM-LLM Feature Augmentation: The aligned features from the VLM and LLM are then combined to provide a richer and more informative representation for the defect classification task.
The researchers evaluate their approach on the ASE dataset, which contains software code and associated defects. They demonstrate that the proposed method outperforms several baseline approaches, particularly in few-shot scenarios where limited training data is available.
Critical Analysis
The paper presents a promising approach to addressing the challenge of few-shot defect recognition in software engineering. By leveraging the complementary strengths of VLMs and LLMs, the researchers have developed a novel technique that can potentially improve the accuracy and robustness of defect classification models.
However, the paper does not provide a comprehensive analysis of the limitations or potential drawbacks of the proposed method. For example, it would be helpful to understand the computational complexity and training time requirements of the Progressive Alignment and feature augmentation steps, as these factors can be crucial in real-world software engineering applications.
Additionally, the paper could have explored the sensitivity of the method to the choice of VLM and LLM models, as different architectures and pre-training strategies may have varying impacts on the final performance. A more thorough investigation of the generalizability of the approach to other software engineering datasets or tasks would also strengthen the conclusions.
Overall, the paper presents an interesting and potentially impactful contribution to the field of software defect detection. However, further research and analysis would be needed to fully assess the method's limitations and potential for real-world deployment.
Conclusion
The "Progressive Alignment with VLM-LLM Feature" approach proposed in this paper is a novel and promising solution to the challenge of few-shot defect recognition in software engineering. By leveraging the complementary strengths of Vision-Language Models and Large Language Models, the researchers have developed a technique that can enhance the accuracy and robustness of defect classification, even when limited training data is available.
While the paper presents promising results on the ASE dataset, further research is needed to fully understand the method's limitations, computational requirements, and generalizability to other software engineering tasks and datasets. Nonetheless, this work represents an important step forward in the application of advanced AI techniques to the critical problem of software defect detection and prevention.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Progressive Alignment with VLM-LLM Feature to Augment Defect Classification for the ASE Dataset
Chih-Chung Hsu, Chia-Ming Lee, Chun-Hung Sun, Kuang-Ming Wu
Traditional defect classification approaches are facing with two barriers. (1) Insufficient training data and unstable data quality. Collecting sufficient defective sample is expensive and time-costing, consequently leading to dataset variance. It introduces the difficulty on recognition and learning. (2) Over-dependence on visual modality. When the image pattern and texture is monotonic for all defect classes in a given dataset, the performance of conventional AOI system cannot be guaranteed. In scenarios where image quality is compromised due to mechanical failures or when defect information is inherently difficult to discern, the performance of deep models cannot be guaranteed. A main question is, how to solve those two problems when they occur at the same time? The feasible strategy is to explore another feature within dataset and combine an eminent vision-language model (VLM) and Large-Language model (LLM) with their astonishing zero-shot capability. In this work, we propose the special ASE dataset, including rich data description recorded on image, for defect classification, but the defect feature is uneasy to learn directly. Secondly, We present the prompting for VLM-LLM against defect classification with the proposed ASE dataset to activate extra-modality feature from images to enhance performance. Then, We design the novel progressive feature alignment (PFA) block to refine image-text feature to alleviate the difficulty of alignment under few-shot scenario. Finally, the proposed Cross-modality attention fusion (CMAF) module can effectively fuse different modality feature. Experiment results have demonstrated our method's effectiveness over several defect classification methods for the ASE dataset.
Read more4/9/2024
0
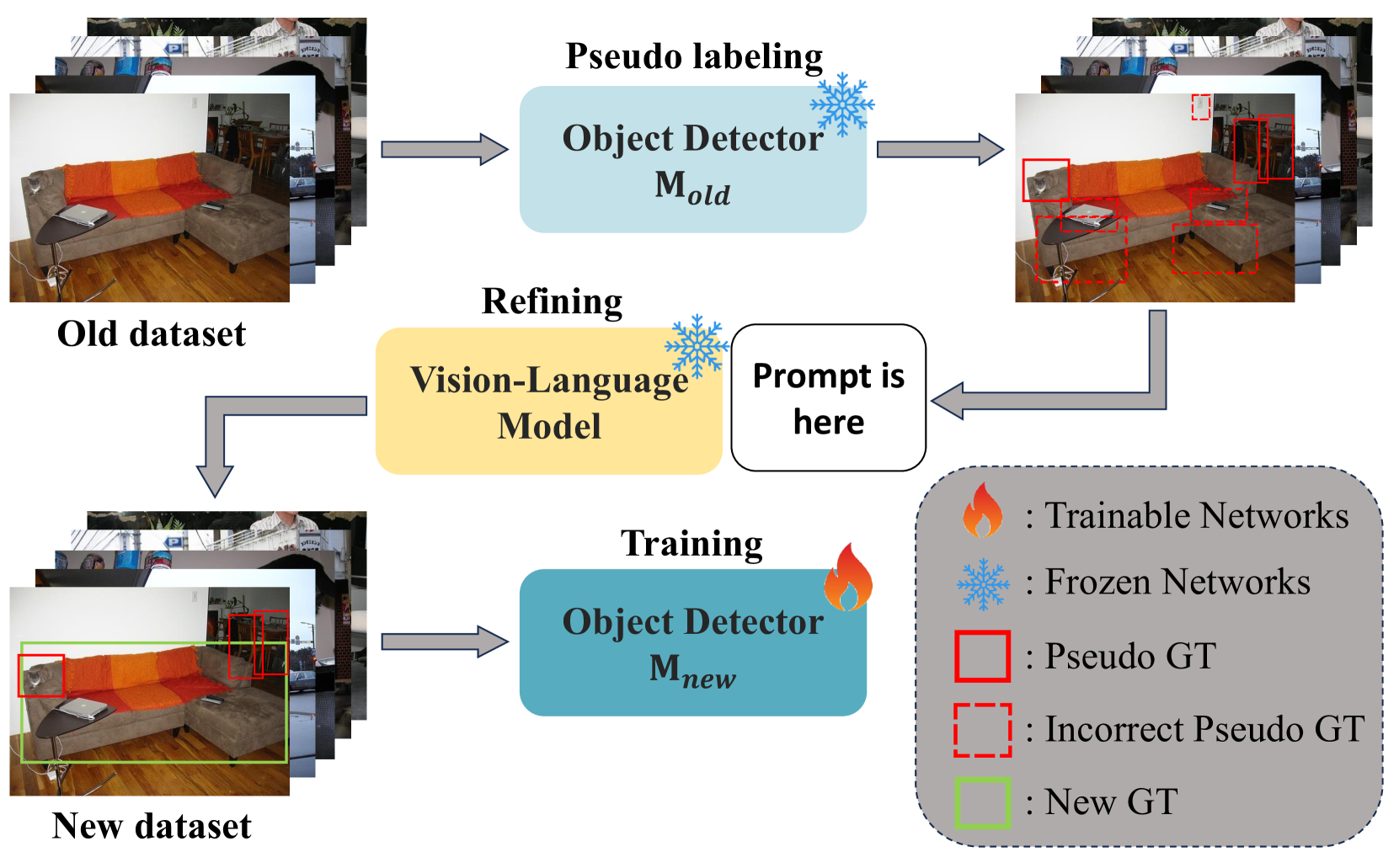
VLM-PL: Advanced Pseudo Labeling Approach for Class Incremental Object Detection via Vision-Language Model
Junsu Kim, Yunhoe Ku, Jihyeon Kim, Junuk Cha, Seungryul Baek
In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
Read more5/10/2024
0
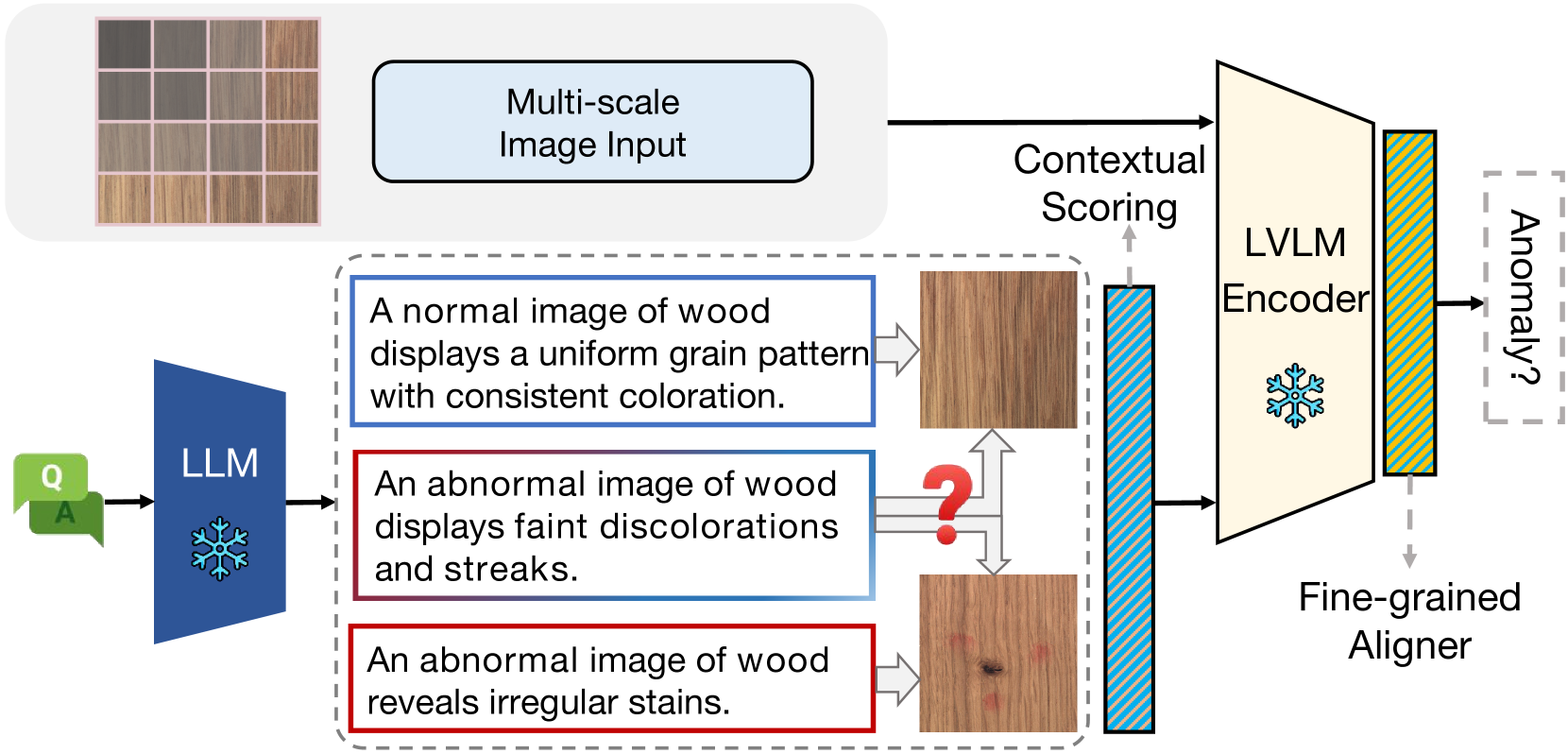
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Jiaqi Zhu, Shaofeng Cai, Fang Deng, Beng Chin Ooi, Junran Wu
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec and 8.9% on VisA compared to state-of-the-art approaches.
Read more9/11/2024

0
An Evaluation of Continual Learning for Advanced Node Semiconductor Defect Inspection
Amit Prasad, Bappaditya Dey, Victor Blanco, Sandip Halder
Deep learning-based semiconductor defect inspection has gained traction in recent years, offering a powerful and versatile approach that provides high accuracy, adaptability, and efficiency in detecting and classifying nano-scale defects. However, semiconductor manufacturing processes are continually evolving, leading to the emergence of new types of defects over time. This presents a significant challenge for conventional supervised defect detectors, as they may suffer from catastrophic forgetting when trained on new defect datasets, potentially compromising performance on previously learned tasks. An alternative approach involves the constant storage of previously trained datasets alongside pre-trained model versions, which can be utilized for (re-)training from scratch or fine-tuning whenever encountering a new defect dataset. However, adhering to such a storage template is impractical in terms of size, particularly when considering High-Volume Manufacturing (HVM). Additionally, semiconductor defect datasets, especially those encompassing stochastic defects, are often limited and expensive to obtain, thus lacking sufficient representation of the entire universal set of defectivity. This work introduces a task-agnostic, meta-learning approach aimed at addressing this challenge, which enables the incremental addition of new defect classes and scales to create a more robust and generalized model for semiconductor defect inspection. We have benchmarked our approach using real resist-wafer SEM (Scanning Electron Microscopy) datasets for two process steps, ADI and AEI, demonstrating its superior performance compared to conventional supervised training methods.
Read more7/18/2024