Revisiting Relevance Feedback for CLIP-based Interactive Image Retrieval
2404.16398
0
0
🖼️
Abstract
Many image retrieval studies use metric learning to train an image encoder. However, metric learning cannot handle differences in users' preferences, and requires data to train an image encoder. To overcome these limitations, we revisit relevance feedback, a classic technique for interactive retrieval systems, and propose an interactive CLIP-based image retrieval system with relevance feedback. Our retrieval system first executes the retrieval, collects each user's unique preferences through binary feedback, and returns images the user prefers. Even when users have various preferences, our retrieval system learns each user's preference through the feedback and adapts to the preference. Moreover, our retrieval system leverages CLIP's zero-shot transferability and achieves high accuracy without training. We empirically show that our retrieval system competes well with state-of-the-art metric learning in category-based image retrieval, despite not training image encoders specifically for each dataset. Furthermore, we set up two additional experimental settings where users have various preferences: one-label-based image retrieval and conditioned image retrieval. In both cases, our retrieval system effectively adapts to each user's preferences, resulting in improved accuracy compared to image retrieval without feedback. Overall, our work highlights the potential benefits of integrating CLIP with classic relevance feedback techniques to enhance image retrieval.
Create account to get full access
Overview
- Existing image retrieval systems use metric learning to train image encoders, but this approach has limitations:
- It cannot handle differences in user preferences
- It requires data to train the image encoder
- This paper proposes an interactive CLIP-based image retrieval system that overcomes these limitations by leveraging relevance feedback:
- The system collects user preferences through binary feedback and adapts to each user's unique preferences
- It leverages CLIP's zero-shot transferability to achieve high accuracy without training
Plain English Explanation
When people search for images online, the search engine typically returns a set of results based on how similar the images are to the search query. Metric learning is a common technique used to train the image encoder that powers these search engines. However, this approach has some drawbacks.
First, metric learning can't account for the fact that different users might have different preferences when it comes to the images they find relevant. What one person considers a good match for a search query, another person might not. Second, metric learning requires a lot of training data to build an effective image encoder, which can be time-consuming and expensive to acquire.
To address these limitations, the researchers in this paper propose an interactive CLIP-based image retrieval system. CLIP is a powerful language-image model that can understand the relationship between text and images, even without being explicitly trained on a specific dataset.
The key idea is to combine CLIP's capabilities with a classic technique called relevance feedback. When a user searches for images, the system first returns a set of results. The user then provides binary feedback (thumbs up or down) on which images they find relevant. The system learns from this feedback and adjusts the search results to better match the user's preferences. Even if different users have varying preferences, the system can adapt to each individual.
Importantly, the researchers show that their interactive CLIP-based system can achieve high accuracy in image retrieval tasks without the need to train a dedicated image encoder for each dataset, as is typically required with metric learning approaches. This makes the system more flexible and easier to deploy in real-world applications.
Technical Explanation
The researchers propose an interactive CLIP-based image retrieval system that combines the power of the CLIP model with the classic technique of relevance feedback.
CLIP is a language-image model that can understand the relationship between text and images, even without being explicitly trained on a specific dataset. The researchers leverage CLIP's zero-shot transferability, which means it can be applied to a wide range of image retrieval tasks without requiring additional training.
The key components of the proposed system are:
- Retrieval: The system first executes a standard image retrieval query, using CLIP to match the user's search query to the available images.
- Relevance Feedback: The system then collects binary feedback (thumbs up or down) from the user on the relevance of the retrieved images.
- Preference Adaptation: Using the relevance feedback, the system learns the user's unique preferences and adapts the search results accordingly.
Through this interactive process, the system is able to effectively handle differences in user preferences, without the need for metric learning or large amounts of training data.
The researchers evaluate their system on several image retrieval tasks, including category-based retrieval, one-label-based retrieval, and conditioned retrieval. They show that their interactive CLIP-based system can compete with state-of-the-art metric learning approaches, despite not requiring any dataset-specific training of the image encoder.
Critical Analysis
The researchers have presented a novel and promising approach to interactive image retrieval that addresses some of the key limitations of metric learning techniques. By integrating CLIP's zero-shot transferability with relevance feedback, the system is able to adapt to individual user preferences without the need for extensive training.
However, the paper does acknowledge a few potential limitations and areas for further research:
- Scalability: While the system performs well on the evaluated datasets, it's unclear how it would scale to larger-scale image retrieval tasks with millions or billions of images.
- User Experience: The paper focuses primarily on the technical aspects of the system, but more research may be needed to optimize the user experience and ensure the relevance feedback process is intuitive and efficient for end-users.
- Contextual Factors: The current system only considers binary user feedback, but in practice, there may be more nuanced factors that influence a user's perception of image relevance, such as the search context or the user's task-specific goals.
Despite these potential limitations, the researchers have demonstrated the potential benefits of integrating CLIP with classic relevance feedback techniques to enhance image retrieval. As the field of language-image models continues to evolve, this type of hybrid approach may become increasingly valuable for building flexible and user-centric image retrieval systems.
Conclusion
This paper presents an innovative interactive CLIP-based image retrieval system that addresses the limitations of traditional metric learning approaches. By leveraging CLIP's zero-shot transferability and integrating relevance feedback, the system can effectively adapt to individual user preferences without the need for extensive dataset-specific training.
The researchers have shown that their system can achieve high accuracy in a variety of image retrieval tasks, outperforming state-of-the-art metric learning techniques in certain scenarios. This work highlights the potential benefits of combining language-image models like CLIP with classic interactive techniques, paving the way for more user-centric and adaptable image retrieval systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval
Christian Lulf, Denis Mayr Lima Martins, Marcos Antonio Vaz Salles, Yongluan Zhou, Fabian Gieseke
0
0
The advent of text-image models, most notably CLIP, has significantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. Despite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and completeness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interactive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative examples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon recent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
6/21/2024
🤯
ReFIT: Relevance Feedback from a Reranker during Inference
Revanth Gangi Reddy, Pradeep Dasigi, Md Arafat Sultan, Arman Cohan, Avirup Sil, Heng Ji, Hannaneh Hajishirzi
0
0
Retrieve-and-rerank is a prevalent framework in neural information retrieval, wherein a bi-encoder network initially retrieves a pre-defined number of candidates (e.g., K=100), which are then reranked by a more powerful cross-encoder model. While the reranker often yields improved candidate scores compared to the retriever, its scope is confined to only the top K retrieved candidates. As a result, the reranker cannot improve retrieval performance in terms of Recall@K. In this work, we propose to leverage the reranker to improve recall by making it provide relevance feedback to the retriever at inference time. Specifically, given a test instance during inference, we distill the reranker's predictions for that instance into the retriever's query representation using a lightweight update mechanism. The aim of the distillation loss is to align the retriever's candidate scores more closely with those produced by the reranker. The algorithm then proceeds by executing a second retrieval step using the updated query vector. We empirically demonstrate that this method, applicable to various retrieve-and-rerank frameworks, substantially enhances retrieval recall across multiple domains, languages, and modalities.
5/29/2024
🖼️
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
0
0
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
4/30/2024
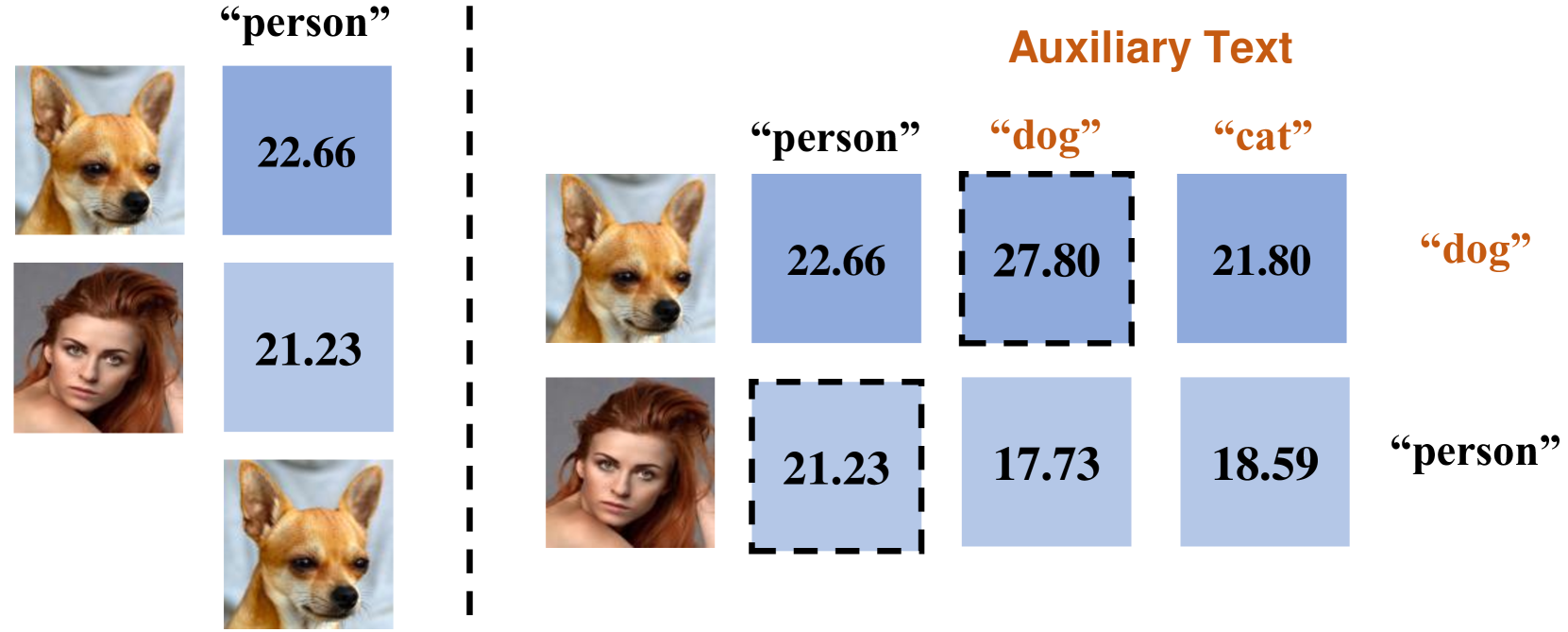
Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
Hanyao Wang, Yibing Zhan, Liu Liu, Liang Ding, Yan Yang, Jun Yu
0
0
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
6/28/2024